






论文特点:多目标优化、多目标测试
重要技术:
MAMAB:根据多个优化目标选择最佳目标组合
NIC:优化所选目标组合
--自适应种群大小
--联合突变算子
--共享种子池

灰盒模糊测试中的自适应多目标优化
MobFuzz: Adaptive Multi-objective Optimization in Gray-box Fuzzing(2024)
摘要:
覆盖率引导灰盒模糊测试(Coverage-guided gray-box fuzzing,CGF)是一种有效的软件测试技术。在CGF中通常有多个目标需要优化。然而,现有的CGF方法不能成功地同时找到多个目标的最优值。本文提出了一种用于多目标优化(MOO)的灰盒模糊器——MobFuzz。我们将多目标优化过程建模为多人多臂老虎机问题(MPMAB)。首先,它自适应地选择包含最适合当前情况的目标的目标组合。其次,我们的模型处理功率调度,在选择的目标组合下自适应分配能量给种子。在MobFuzz中,我们提出了一种称为NIC的进化算法来同时优化我们选择的目标,而不会产生额外的性能开销。为了证明MobFuzz的有效性,我们在12个实际程序和MAGMA数据集上进行了实验。实验结果表明,MobFuzz中的多目标优化优于基线模糊器中的单目标模糊。相比之下,MobFuzz可以选择最优的目标组合,并将多个目标的值提高107%,最多减少55%的能耗。此外,MobFuzz的程序覆盖率比基线fuzzers高6%,发现的独特漏洞比基线fuzzers多3倍。NIC算法至少有2倍的改进,性能开销大约为3%。
|
MAB是多臂老虎机(Multi-Armed Bandit)的缩写,MAB问题就是假设有个赌徒到赌场里面摇老虎机,赌场里面有10个老虎机,每个老虎机的赢钱概率是不一样的,此时他不知道每个老虎机的赢钱概率,而且他只有100个币,也就是说只能摇100次,如果他想最大化收益应该怎么摇? |
1引言:
模糊测试是最成功的基于搜索的软件测试方法之一。覆盖度引导的灰盒模糊(CGF)作为模糊的一种重要变体,近年来受到了研究者的广泛关注[1]。本质上,CGF是一个优化问题[2],[3]。优化方法的关键是搜索输入空间以找到最优解并优化目标。优化目标是指寻找使目标值最大化或最小化的输入[4]。在CGF中,最重要的目标是代码覆盖率,而CGF的目标是最大化覆盖率。
单目标优化只搜索一个目标的最优解。然而,在现实情况下,需要同时优化多个目标来解决难题[4],[5],如检测不同种类的bug,提高模糊效率等。具体来说,在模糊过程的不同阶段,应该根据测试场景自适应地选择这些目标并对其进行优先级排序。例如,在测试内存分配的代码片段时,应该优先考虑与内存消耗目标相关的种子;为了打破嵌入的分支条件,具有更高满意度的比较字节的种子应该是一个重要的目标。因此,多目标优化(multi-objective optimization, MOO)被提出来有效地研究多目标间最优权衡的平衡解[6],[3],[4]。
尽管覆盖引导模糊器在搜索过程中也考虑了覆盖以外的目标,但现有的灰盒模糊器并不能真正支持多目标优化。例如,AFL[7]也会搜索另外两个目标:执行时间和输入大小。选择具有这两个目标(速度*大小)的较小乘积的有利输入(即种子)。理论上,在搜索过程中,一次只考虑一个解,例如目标的乘积,可能会陷入局部最优,无法产生全局最优解[3]。有些工具不能同时协调多个目标。当添加新目标时,旧目标将被丢弃。例如,MemLock[8]通过选择内存消耗更多的种子来解决内存消耗错误。它优化了覆盖率和内存消耗的目标。然而,作为一个基于AFL的工具,MemLock完全取消了AFL的速度目标。根据我们的实验,这种对多目标的忽略明显影响了模糊测试的执行速度。
因此,在现实中,要在CGF中对多个目标同时进行合理优化,需要克服以下挑战:1)不同目标之间的冲突效应。在长期的模糊测试过程中,优化一个目标可能会对另一个目标产生负面影响。例如,根据我们的实验,将满足的比较字节数推到较大的值以通过分支条件会减慢整个模糊过程。这种目标之间相互冲突的内在关系要求我们在不同阶段对不同的目标进行适当的协调,以寻求全局最优解。因此,我们将目标组合的自适应选择作为本文的第一个研究点。
2)适应多目标情况的能量调度。CGF的功率调度用于控制种子的突变次数和执行次数(即能量)[9],从而指导模糊过程。以往在能量调度方面的工作,如AFLFast[1]和EcoFuzz[10],都是基于种子的路径发现能力来分配适当的能量,从而达到节能的目的。然而,在多目标情况下,需要将能量调度计划与目标组合选择相结合来控制能量分配。因此,我们确定了结合目标组合选择的功率调度计划作为本文的第二个研究点。
3)减少多目标模糊带来的性能开销。效率是模糊测试的一个重要指标。当考虑多目标时,目标组合选择、功率调度和突变策略的优化都会引入额外的开销。例如,Cerebro[11]使用了Pareto边界(即具有最优目标值的种子集合)和非支配排序[12]的思想来寻找进化过程中的最优解。然而,这个过程在一个模糊循环中只执行一次。它使模糊器等待最终结果,浪费宝贵的CPU时间。此外,单次运行不能产生全局最优解。计算Pareto边界并揭示收敛性通常需要在进化过程中进行100多次迭代[12]。在模糊测试中直接采用这种进化过程来寻找最优解将带来巨大的性能开销。因此,第三个研究点是在不引入额外性能开销的情况下,找到所选目标的最优结果。
为了克服上述灰盒模糊在MOO中的挑战,在本文中,我们提出了MobFuzz。为了解决目标组合的自适应选择问题,我们将多目标下的CGF过程建模为一个多玩家多臂老虎机问题(MPMAB)问题。经典MAB模型的目标是在有限的试验中通过选择合适的臂来最大化奖励[13],[10]。我们将目标组合建模为具有各自目标的不同参与者,以解决组合选择问题。选择对当前模糊状态具有最大回报的最佳目标组合。为了处理适合多目标情况的能量调度问题,我们将种子建模为老虎机的手臂,并将模糊状态分为探索和开发两种。MobFuzz通过自适应能量调度控制种子的突变和执行的数量。利用该模型,MobFuzz在选择的组合下为种子分配合适的能量,达到最优效果,避免能量浪费。为了解决第三个挑战,我们提出了一种称为CGF (NIC)非支配排序遗传算法的进化算法。该算法基于Pareto边界和非支配排序,在进化过程中寻找最优解。通过将目标组合转换为相应的变异算子组合,设计了一种新的变异策略。更有可能增加目标值的突变体被选择的机会更大。此外,我们提出了一些方法,如共享种子池,以减少性能开销。
|
"帕累托最优边界"(Pareto Frontier)或称为"帕累托前沿",来源于经济学中的帕累托效率或帕累托最优(Pareto Efficiency 或 Pareto Optimality)的概念,是指在一个分配系统中,没有可能通过重新分配使某个个体更好而不使任何其他个体变得更坏的状态。简而言之,这是一种“最优”的状态,其中任何个体的利益增加都将以另一个个体的损失为代价。 |
为了证明MobFuzz的有效性,我们在真实的目标程序和MAGMA数据集上进行了一系列实验。实验结果表明,MobFuzz中的多目标优化在基线上优于单目标优化。与MemLock和FuzzFactory等最先进的fuzzers相比,MobFuzz可以同时优化所有目标以达到最优值。具体来说,MobFuzz在目标价值上超过竞争对手高达107%。此外,实验结果表明了MPMAB模型和NIC算法的有效性。我们最多减少55%的能耗,与基线模糊器相比,NIC的性能至少提高了2倍,而性能开销仅为3.3%。此外,MobFuzz的程序覆盖率最多比竞争对手多6%,发现的漏洞也比竞争对手多3倍。综上所述,本文的贡献如下:
-
- 针对CGF算法在多目标优化中的不足。我们将灰盒模糊中的MOO建模为一个多人MAB问题,并根据模型自适应地选择目标组合和分配能量给种子。
- 为了解决现有模糊器在寻找最优结果方面存在的问题,我们提出了MobFuzz中的NIC算法。将NIC集成到模糊回路中,在不引入过多开销的情况下搜索最优目标值。
- 我们实现了MobFuzz,并用实际程序和MAGMA数据集对其进行了评估。结果证明了多目标优化在CGF中的有效性。
2研究背景:
A. CFG及目标:
模糊测试是目前最流行的软件测试技术之一,近年来发展迅速,尤其是覆盖率引导的灰盒模糊测试[14],[15],[16],[17],[18]。与简单的黑盒模糊测试和复杂的白盒模糊测试相比,CGF的关键在于通过轻量级的检测来最大化代码覆盖率[9]。AFL作为CGF的代表,暴露了许多具有这些特性的安全关键漏洞[19]。
基本流程。CGF首先根据目标从种子池中选择一个种子,然后通过功率调度将能量分配给所选择的种子。能量控制着这个种子的变异和执行的数量。接下来,对种子进行变异以生成测试用例。当执行这些测试用例时,CGF监视它们是否实现了新的代码覆盖。获得新覆盖率的测试用例将作为种子保存到种子池中。之后,CGF回到种子选择并开始下一轮模糊测试。
CFG的目标。除了代码覆盖率之外,灰盒模糊器在维护种子库时通常需要最大化多个目标。例如,AFL搜索执行速度更快、尺寸更小的种子。它们的乘积,即速度*大小,用于优化目标。具有较大乘积结果的种子将被标记为受青睐,并且它们将比不受青睐的种子有更大的机会被选中。
然而,现有的覆盖率引导的模糊器不能支持多目标优化。一些基于AFL的fuzzers在添加新目标时会禁用AFL中原有的速度目标,如MemLock[8]和FuzzFactory [20];其他解决方案使用简单的算法来协调多个目标,这将陷入局部最优[7],或引入不可接受的开销[11]。因此,需要一种能够同时优化多个目标而不会导致性能降低的解决方案。
B. MAB问题:
探索vs.开发。探索与开发之间的权衡是博弈论中的一个重要概念[13]。受玩家在玩老虎机时选择最大化奖励的启发,提出了多臂老虎机问题模型来解决这一问题[21]。根据定义,经典MAB模型包含N条平行臂,每次只选择一条臂。手臂i (i∈{1,2,…, N})定义为Ri。MAB问题的关键是在有限的手臂选择中使总奖励最大化。然而,在尝试某条手臂之前,它的回报是未知的。探索的过程是在手臂上进行试验,以获得更准确的奖励计算。当所有手臂的报酬都已知时,选择报酬最大的手臂就是开发的过程。综上所述,选择最佳策略(开发)将使当前总奖励最大化。从长期来看,对奖励未知臂(探索)进行试验有助于获得更大的总奖励[22]。我们的目标是权衡MAB问题中探索和开发之间的优势和劣势。
CGF中使用MAB的不适宜性。之前在模糊方面的工作,如EcoFuzz[10],将种子建模为MAB中的手臂,并通过该模型解决具体问题,如能量分配。如果我们想对CGF中的MOO进行改进,经典的MAB模型是不合适的。首先,如上所述,我们需要做出两个选择:目标组合选择和能量分配。在MAB模型中,将种子视为臂是很自然的。然而,单人MAB模型不再适用,因为不同的目标组合代表不同的玩家有自己的目标。换句话说,我们需要一个多人MAB来模拟这个过程。其次,经典MAB模型的奖励是不变的,臂数是恒定的[10]。然而,随着模糊活动的继续,目标组合和种子的奖励也会相应改变。此外,在模糊过程中,种子的数量不是恒定的。经典MAB模型的上述缺陷促使我们提出一种适用于模糊多目标的MAB变体模型。
3 自适应多目标优化:
A.概述:
如图1所示,MobFuzz是通过向经典模糊处理过程添加两个新模块来设计的:MPMAB模型和NIC算法。MPMAB模型自适应地确定目标组合和能量分配。NIC算法在不引入额外性能开销的情况下,通过进化过程产生最优目标值。
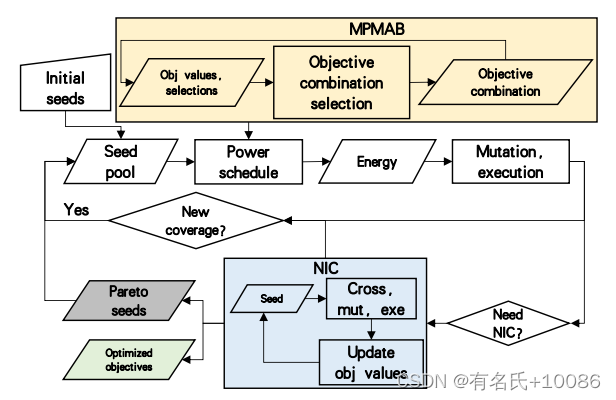
图1 MobFuzz主要的模糊循环。不同颜色的子进程是我们在MobFuzz中的关键方法。
MobFuzz的基本流程包括以下几个步骤。首先,从种子池中选择一个种子。其次,MPMAB模型确定当前模糊状态下的最佳目标组合。MPMAB根据选择的目标组合,对处于探索和开发状态的种子分配不同的能量。然后,MobFuzz根据分配的能量执行突变和执行。同时,对所选组合中的目标值进行监测。如果满足启动条件,则调用NIC算法。NIC是一个进化的过程。它更新目标值,逐步逼近最优解。最后,将具有最优值的Pareto种子保存到种子池中,开始下一轮模糊分析。
B.多玩家多臂老虎机模型(MPMAB)
该模型解决了自适应选择目标组合和根据选择的目标组合分配能量两个问题。

表1 MPMAB模型中变量的名称和定义
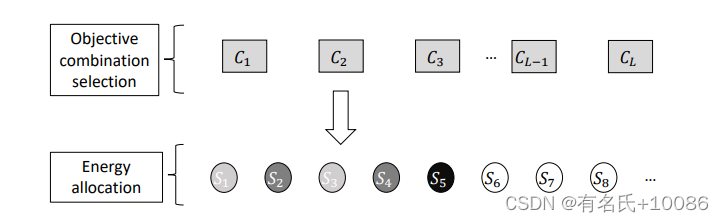
图2 MPMAB模型的演示。矩形表示目标组合。圆圈表示种子。彩色形状的奖励是众所周知的。种子颜色的深浅表明所分配的能量。
1) MPMAB模型概述:表1显示了我们模型中的变量。图2显示了我们的MPMAB模型的概述。首先,该模型处理了自适应目标组合选择问题。在玩老虎机时,每个组合代表一个玩家有自己的目标。在模糊过程中,目标的数量和目标组合的数量是恒定的。例如,如果我们有3个目标要优化,那么总共有8(23)个目标组合。由于组合的数量是恒定的,每个组合的奖励都可以通过一个先锋阶段获得。然后,我们通过我们提出的算法(章节III-B2)选择最佳目标组合。
其次,MPMAB处理所选目标组合下种子的自适应能量分配。在模糊测试过程中,种子的数量在不断增加,在执行种子之前,我们无法估计奖励。因此,专注于奖励已知的种子(开发)和尝试奖励未知的种子(探索)之间的权衡并不像组合选择那样简单。为了解决这个问题,我们将模糊过程分为探索状态和利用状态。我们可以在不同的目标组合下自适应地将能量分配到不同的状态(Section III-B3)。
2)目标组合选择:在第t分钟,当前模糊回合的ID为t。随着模糊运动的进行,我们可以得到第t轮目标Oi的平均值,记为vOit![]() 。另外,我们可以计算出前t轮(第1轮,第2轮,…第t轮)的目标Oi的平均值,
。另外,我们可以计算出前t轮(第1轮,第2轮,…第t轮)的目标Oi的平均值, 
因此,我们定义在第t轮中选择目标Oi的奖励为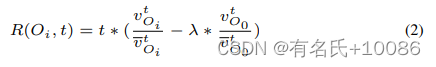
从公式中我们可以看到,vOitvOit![]() 表示当前轮与前t轮的目标值之比。当vOit
表示当前轮与前t轮的目标值之比。当vOit![]() 大于vOit
大于vOit![]() 时,奖励是大的。这鼓励选择快速增长的目标。此外,我们强调后期回合的变化[23]和奖励前的多重t。此外,模糊运动的速度对于模糊测试至关重要[24],[25],[26];我们在目标中添加了一个惩罚,这会减慢进程:- λ*vO0tv0t
时,奖励是大的。这鼓励选择快速增长的目标。此外,我们强调后期回合的变化[23]和奖励前的多重t。此外,模糊运动的速度对于模糊测试至关重要[24],[25],[26];我们在目标中添加了一个惩罚,这会减慢进程:- λ*vO0tv0t![]() (速度是第0个对象)。
(速度是第0个对象)。
当目标数为N时,目标组合数为2N。我们推断出组合Cl的奖励为
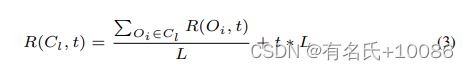
L是组合中的目标个数。这个奖励由两部分组成:首先,我们使用目标的平均奖励。其次,将t * L添加到具有更多目标的奖励组合中。
接下来,我们可以计算组合的最终得分来做出决策。UCB1[27]是MAB问题的经典答案,我们将其作为计算分数的依据
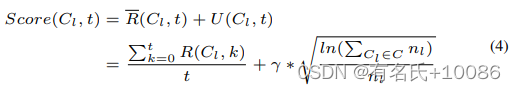
C表示所有目标组合。分数由两部分组成。R![]() (Cl,t)是前t轮中Cl的平均奖励,这使得具有更高历史奖励的组合得分更高(探索)。U(Cl,t)是Cl的上置信度界,对于nl值(组合被选择的次数)越小的组合,U(Cl,t)给的分数越高,这就是探索。在模糊化开始时,我们经历了一个先锋阶段,在这个阶段,每个目标组合被选择一次。在此阶段之后,每个组合的nl值将为1。接下来,在每轮模糊测试结束时,我们计算每个组合的得分,并选择得分最高的组合作为下一轮的目标组合。此外,γ是UCB1中的一个关键参数,它控制着探索和开发之间的平衡,我们将在第五节中讨论这个参数。
(Cl,t)是前t轮中Cl的平均奖励,这使得具有更高历史奖励的组合得分更高(探索)。U(Cl,t)是Cl的上置信度界,对于nl值(组合被选择的次数)越小的组合,U(Cl,t)给的分数越高,这就是探索。在模糊化开始时,我们经历了一个先锋阶段,在这个阶段,每个目标组合被选择一次。在此阶段之后,每个组合的nl值将为1。接下来,在每轮模糊测试结束时,我们计算每个组合的得分,并选择得分最高的组合作为下一轮的目标组合。此外,γ是UCB1中的一个关键参数,它控制着探索和开发之间的平衡,我们将在第五节中讨论这个参数。
3)能量调度:在此轮模糊测试中确定目标组合后,MPMAB模型在选择的目标组合下进行自适应能量分配。种子(手臂)的数量随着模糊活动的继续而增加,我们不能重复使用先锋阶段来获得启动模型的奖励。如上所述,我们的主要挑战是平衡探索(尝试奖励未知的种子)和开发(选择具有最大奖励的种子)。我们的目标是在选择的目标组合下,在不同的模糊状态下自适应分配能量。然而,从CGF能量分配的相关研究[1]、[10]、[28]来看,尚无多目标优化情况下的能量分配工作。基于此背景,我们首先将达到某一目标值的平均能量定义为EOit=ExecstvOit. (5)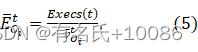 这是在t轮中执行的次数和目标值的商。我们认为它是增加目标值所需的最小能量。
这是在t轮中执行的次数和目标值的商。我们认为它是增加目标值所需的最小能量。
同样,我们可以推导出Cl在t轮中的平均能量为
EClt=Oi∈ClEOitL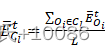 (6)
(6)
接下来,我们将模糊状态划分为不同的状态:探索状态。这种状态意味着当前存在奖励未知的种子,我们需要尝试尽可能多的新种子。我们将此状态下的最小能量分配给种子为
ESj=EClt![]() (7)
(7)
这种能量有两个特点:1)它仍然非常小。2)虽然很小,但它是达到较大目标值所需的最小期望能量。因此,我们将这个能量分配给处于这种状态的种子.
开发状态。在这种状态下,种子的所有奖励都是已知的,选择奖励最大的种子是合理的。我们定义这个状态下的能量为
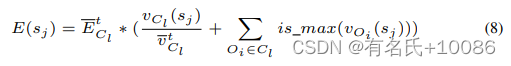
可以看出,式8是基于式7中探索状态下的能量。在式中,vCl(Sj)vClt![]() 是执行种子Sj
是执行种子Sj![]() 的目标值与组合Cl
的目标值与组合Cl![]() 平均值之间的比值。当执行种子的目标值(vCl(Sj)
平均值之间的比值。当执行种子的目标值(vCl(Sj)![]() )大于平均值(vClt
)大于平均值(vClt![]() )时,我们分配更多的能量来鼓励它,反之亦然。此外,如果执行此种子达到某个目标的最大值,is_max()则返回1,否则返回0。如果执行此种子达到某个目标的最大值,我们根据该函数(is_max(vOi(Sj)
)时,我们分配更多的能量来鼓励它,反之亦然。此外,如果执行此种子达到某个目标的最大值,is_max()则返回1,否则返回0。如果执行此种子达到某个目标的最大值,我们根据该函数(is_max(vOi(Sj)![]() ))为分配的能量添加奖励值。
))为分配的能量添加奖励值。
C. NIC算法

1) NIC概述:为了优化所选组合中的目标并在不增加性能开销的情况下找到最优结果,我们提出了NIC算法。它是为MobFuzz中的多目标优化而设计的一种进化算法。NIC的基本过程如下:首先,选择一个规模为N的种子初始种群。然后,在初始群体中进行杂交和突变获得子代种子。其次,我们对种群中的每个种子执行目标程序,获得相关信息(算法1中的第26行),例如覆盖率信息和目标值。从第二代开始,亲本种群与子代组合进行非显性排序[12]。根据种子的非显性关系,选择目标值更新的种子(第27行)组成规模为N的新亲本群体,并利用覆盖信息更新种子库(第28 - 30行)。最后,在新的亲本群体中通过杂交和突变产生新的子代种子。这个过程不断重复,直到满足预定义的迭代次数,NIC输出Pareto边界,其中包含具有最佳目标值的种子(第32行)。
2) NIC的详细技术:自适应种群大小。在NIC算法中,种群规模是一个至关重要的因素。小种群缺乏多样性,不能产生最优结果。庞大的种群在进化过程中需要更多的计算资源。因此,在启动NIC之前,我们需要在人口规模上取得平衡。通过广泛的试验,我们确定种子数量的10%应为群体大小的适当值。每次NIC开始前,我们从种子库中随机抽取10%的种子组成初始种群,进入进化过程。
带AFL的联合突变算子。我们提出了三种有效的NIC突变技术。首先,我们将模糊有效算子集成到NIC中,例如,用整数类型的边界值替换四个字节。此外,传统的进化或遗传算法保留两个后代以保持种群的多样性。为了解决这个问题,在NIC中,两个亲本种子通过交叉和突变,我们保留了两个产生的后代。最后,由于AFL选择不同的突变算子和位置以等概率发生突变,因此不能突出不同算子和位置的重要性。此外,在多目标优化的情况下,我们需要将目标与特定的或某些突变算子联系起来。换句话说,一个目标组合应该有一个相应的突变算子组合,其中的算子应该被赋予更高的概率。为了解决这些问题,在NIC中,我们记录了在选择的目标组合中,可以增加目标组合值的算子和位置的次数。更有可能增加客观价值的那些被选择的概率更大。通过这种方法,我们可以得到所选组合的最佳突变算子或位置。
降低性能开销。进化或遗传算法通常迭代100代以上。如果我们直接将这个进程插入到模糊循环中,性能开销将是不可接受的。我们提出了几种方法来处理这个问题。例如,如第III-C1节所述,当我们对亲本群体进行交叉和突变以产生后代时,我们添加了新的覆盖监视器的过程。在NIC期间生成的覆盖新代码的种子也可以保存到主模糊测试循环的种子池中。像这种共享种子池这样的技术表明,NIC不再独立于主循环。它们是集成的。通过这种方式,在NIC中消除了通过迭代产生最佳结果的开销。另外,我们为NIC增加了一个启动条件。在我们的设计中,当我们监测到目标值的下降时,我们启动NIC算法来优化和增加它们。具体来说,我们每分钟都记录目标值。当两个连续值的梯度小于某一阈值时,启动NIC算法。根据我们的初步实验,当阈值为-0.15时,是启动NIC达到最佳性能的配置。此外,NIC将执行预定义次数的迭代(算法1中的第25行)
D.工作流程:在算法1中,MobFuzz的输入是初始种子S和我们想要优化的目标O。种子池Q初始化为第1行用户提供的种子。在配置的模糊处理超时时间(TIME_OUT)内,MobFuzz将继续对目标程序进行模糊处理.
首先,我们需要确定选择下一轮目标组合的时间间隔。根据我们的初步评估,我们以1分钟为时间间隔进行选择。因此,24小时模糊运动被分为1440(24 * 60/1)轮. 每轮模糊测试持续1分钟。在第t轮结束时,我们需要选择下一轮的目标组合。如第3 - 9行所示,如果时间间隔超过1分钟,我们将在函数obj_com_sel()中自适应地选择带有MPMAB的目标组合。该函数的参数包括obj_val(目标值)、obj_sel(目标的选择数)和t(当前模糊测试轮)。该函数输出所选目标组合Cl。当一个组合确定后,在这个时间间隔内,我们将在这个选择的组合中优化目标。第III-B2节详细说明了这一过程。
在函数pow_sch()中的第10 - 17行,我们监视模糊的当前状态(探索或利用),并根据所选择的目标组合将能量分配给种子。参数列在第10行。输出为III-B3节公式7、8所示的能量。能量的数量决定了对种子突变和执行的次数(第19行)。具体来说,我们关注的是能量调度。因此,我们继承了AFL的种子选择机制。在突变和执行之后,我们保存带来新代码覆盖的种子(第20 - 22行)。第24 - 33行显示了NIC的工作流程。NIC()的参数包括s'(从池中选择的种子)、Cl(选择的目标组合)和T (NIC的迭代次数)。第26行显示了NIC的突变和执行。目标OM的值在第27行更新。此外,NIC算法通过共享种子池(第29行)进行进化过程,并优化目标值。NIC的输出为帕累托边界[12],即目标值最优的种子集合。我们将Pareto边界作为种子添加到第35行的种子池中。综上所述,NIC具有以下功能:1)输出所选目标的最优目标值。2) NIC输出Pareto边界,这些种子保存到共享种子池中。3)同时,它保存了带来新覆盖的种子。
4 实验:
我们基于AFL实现了MobFuzz。我们修改了LLVM中的检测代码,以分别记录堆栈内存消耗的数量和满足的比较字节数。MPMAB模型和NIC算法在afl- fuzzy .c中分别实现,它们总共包含1.5k行代码。此外,我们修改了主模糊回路以与MPMAB和NIC交互。我们用MPMAB调度取代了原来的能量调度,并增加了检查NIC是否满足启动条件的代码。具体来说,当两个连续物目值的梯度小于某一阈值时,将启动NIC。这些修改包含大约0.5k行代码。
5 评估:
在我们的评估中,我们回答了以下研究问题:
•RQ1. 与基线模糊器中的单目标优化相比,MobFuzz中的多目标优化性能如何?
•RQ2. 目标组合选择在模糊化过程中如何适应?
•RQ3. 在选择的目标组合下,与基线模糊器相比,我们的能量调度性能如何?
•RQ4. NIC是否在不引入额外性能开销的情况下优化了目标值?
A.设置
选定要测试的程序。我们总共测试了12个真实世界的程序。它们包括各种用途的程序,例如,图像处理(tiff2pdf)。表2显示了这些目标程序的基本信息。它们是从最先进的论文中收集的,这些论文列在附录的表十六中。我们认为这样收集程序可以保证说服力和代表性。
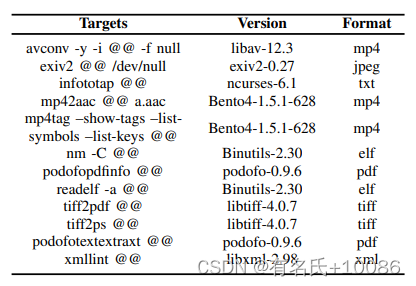
表2 目标程序
基线模糊器进行比较。AFL[7]、MemLock[8]和FuzzFactory[20]在我们的评估中用于测试真实世界的程序。根据我们在引言中的讨论,选择它们是因为我们可以将MobFuzz的多目标优化与它们的单目标优化进行比较。此外,我们选择了3个目标作为我们的评估指标,包括执行速度(AFL),堆栈内存消耗(MemLock)和满意的比较字节数(FuzzFactory)。这些模糊器使用一致的设置:确定性和havoc。(SP或Speed表示执行速度,ST或Stack表示堆栈内存消耗,CM或Cmp表示满足的比较字节数。)
我们使用AFL提供的testcase目录中的种子作为初始种子。我们的评估在一台服务器上进行了10次,24小时。
B.多目标优化的有效性:
1)目标值计算结果:表3为10次重复运行目标值的平均值。表中还列出了p值和A12![]() 值。在所有比较中,MobFuzz的值大于(36个中的33个)或等于(36个中的3个)。其中,32对比较有统计学差异(p <0.05 或 A12
值。在所有比较中,MobFuzz的值大于(36个中的33个)或等于(36个中的3个)。其中,32对比较有统计学差异(p <0.05 或 A12![]() >0.5)。具体来说,我们有10次比较,p值小于10−4,A12
>0.5)。具体来说,我们有10次比较,p值小于10−4,A12![]() 值为1.0。例如,在xmllint中,MobFuzz和FuzzFactory的比较字节数分别是1.65∗108和6.65∗107。MobFuzz的性能比FuzzFactory提高约2倍。在Average行中,我们可以看到MobFuzz的平均值大于基线模糊器的平均值。在满意比较字节数方面,我们甚至比FuzzFactory提高了100%以上。
值为1.0。例如,在xmllint中,MobFuzz和FuzzFactory的比较字节数分别是1.65∗108和6.65∗107。MobFuzz的性能比FuzzFactory提高约2倍。在Average行中,我们可以看到MobFuzz的平均值大于基线模糊器的平均值。在满意比较字节数方面,我们甚至比FuzzFactory提高了100%以上。
MOO旨在完成为所有目标生成最优值的任务。之所以对MemLock和FuzzFactory进行改进,是因为NIC算法帮助MobFuzz达到最优值。NIC一直在寻找进化过程中的帕累托种子。每次迭代都更接近最优值。最终结果最接近最优值。MemLock和FuzzFactory没有这种机制来达到目标的最优值。
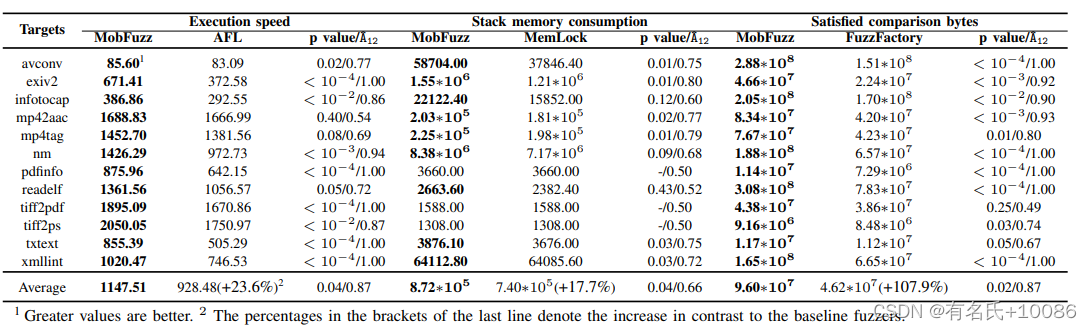
表3 针对不同目标的MoBFuzz进行评估
2)分支覆盖率和独特bug:表4显示了模糊器发现的分支覆盖率和独特bug数量。分支覆盖是评估[29]模糊测试时推荐的覆盖指标。在分支数量方面,MobFuzz在36次对比中有30次优于基准模糊器。与AFL和FuzzFactory相比,平均最多能多找到6%的分支。在寻址器(AddressSanitizer, ASAN)和gnu调试器(gnu debugger, GDB)的帮助下,从独特崩溃中手动收集独特bug。在独特bug这一列中,尽管目标程序全部为零,但MobFuzz在所有15个对比中都优于其他模糊器。MobFuzz的平均值大于竞争对手,比AFL和MemLock多3倍。
我们可以看到,MobFuzz在比较中优于3个竞争对手。究其原因,MobFuzz比其他模糊器具有更好的多目标优化能力。首先,在模糊测试过程中,MobFuzz保持了相对较快的速度。这让MobFuzz有更多机会获得更大的覆盖率并找到更多独特的bug。此外,MobFuzz的栈内存消耗比竞争对手更大,这可能导致目标程序出现更多的错误。再次,MobFuzz的满意比较字节数大于其他模糊器。满足更多的比较有助于探索更多的程序分支。基于这些原因,MobFuzz可以比基准模糊器拥有更大的程序覆盖率,并且可以发现更多独特的bug。
对RQ1的回答:MobFuzz中的多目标优化在基线模糊器中同时优于每个单目标优化。
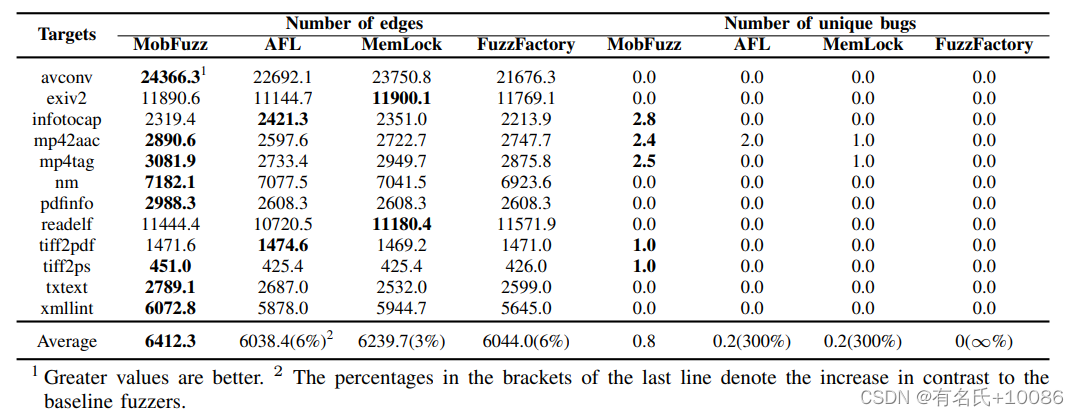
表4基于分支覆盖率和独特漏洞数的评估
C.目标组合的选择:
1)我们设置1分钟作为时间间隔进行选择。在24小时的模糊测试过程中,MPMAB模型总共做出了1440个选择(可能更少,因为在时间间隔结束时目标程序可能仍在执行)。图3显示了所选择的组合如何影响每个时间间隔内的目标值。背景颜色显示了这一分钟内选定的目标组合。这些线显示了每个目标的值。以avconv的结果为例。我们在avconv图中标记A、B和C点。首先,标记A点,以证明MobFuzz能够同时优化多个目标;在这个时间间隔内,选择的组合是speed/stack/cmp。从图中我们可以看出,在这一轮中,所有的目标值都有所增加。接下来,在B点,选择stack/cmp。我们注意到,随着堆栈和cmp的增加,速度下降,这表明了目标之间的相反影响。最后,C点显示了我们对模糊测试速度变慢的修正。在此时间间隔内,由于B点的存在,对stack和cmp目标增加一个惩罚项,并选择speed来提高模糊测试的执行速度。
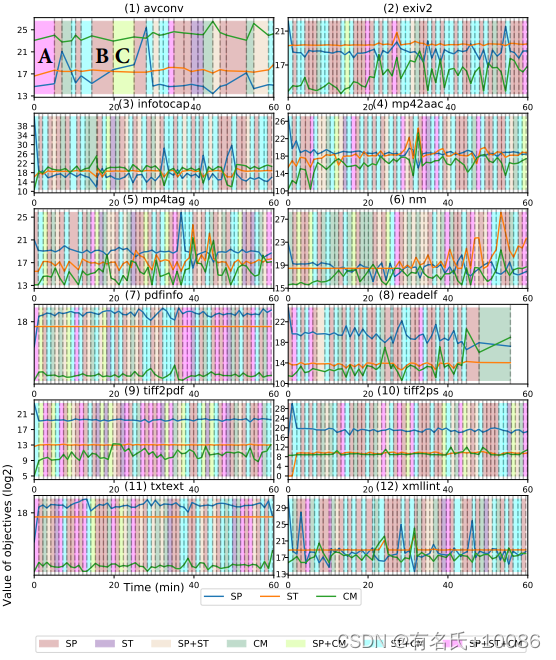
图三60分钟内的目标值和所选目标组合。这3条线表示目标的价值。背景色代表在每个时间间隔内选择的目标组合。
2)表五和图7(附录)显示选定目标的分布情况。当我们考虑3个目标(速度,堆栈和cmp)时,总共有8个目标组合。表V和图7最显著的观察是,在所有组合选择中,MPMAB模型倾向于选择速度目标的比例超过60%。我们再次阐明了与之前的工作[24]、[25]、[26]的共识:模糊测试的最高优先级是执行速度。因此,在等式2中,我们给目标添加了一个惩罚项,从而减缓了模糊测试过程。这符合我们追求速度的趋势,也可以解释表V和图7的特征。
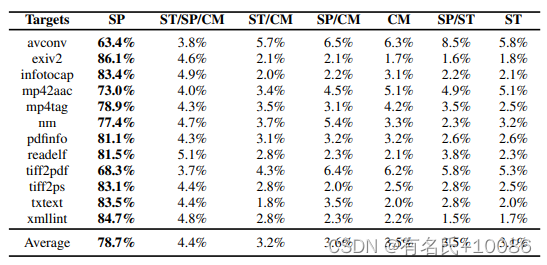
表5 所选目标组合的占比
3)最后,我们需要证明我们是否选择了最佳的目标组合。图4显示了与我们不同的策略。x轴是在所选组合中速度所占比例,不同比例表示不同的选择策略。我们设置了6种策略,包括0%、20%、40%、60%、80%和100%的速度比例。y轴显示了不同策略(v’)的目标值(v’/vM)与我们的MPMAB选择(vM)的比率。v’/vM小于1.0表示本次选择的目标值小于MPMAB选择,本次选择较差。例如,在avconv中,当速度的比例为40%时,我们用红色虚线突出显示结果。这种选择策略的速度大约是我们的80%。堆栈和cmp只占我们的90%。
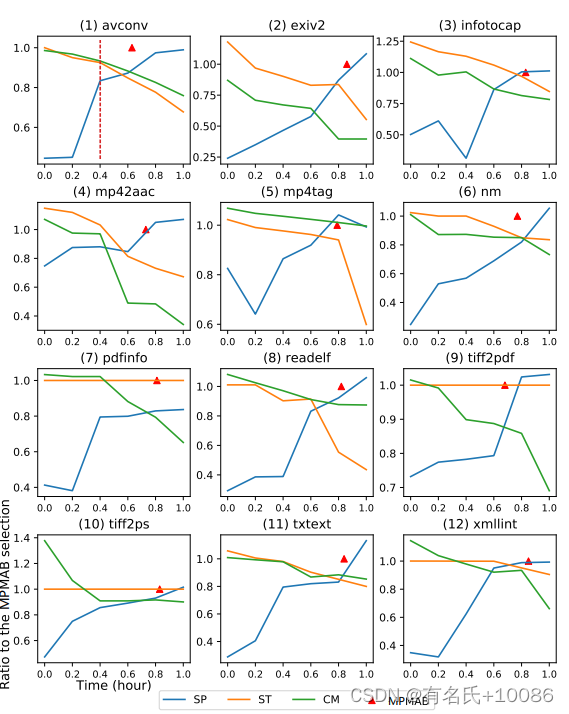
图4 x轴表示不同的选择策略。y轴是不同选择策略(v’)下的目标值(v’/vM)与我们的MPMAB选择(vM)的比率。v’/vM <1.0表示此选择的目标值小于MPMAB选择,反之亦然。
随着速度的比例增加,速度对应的目标值也不断增加。然而,正如本文前面所讨论的,通常情况下,目标之间具有相反的影响。stack和cmp的值随着速度的增加而减小。更有趣的是,我们在图中将MPMAB选择的结果标记为红色三角形。红色三角形靠近三条线的交点。总之,6种选择策略中没有一种优于MPMAB选择。我们策略的目标值都大于6个策略的目标值。从图中可以看出,我们的组合选择方法处理了多个目标之间的关系,可以选择每个组合中最合适的比例来优化所有目标。根据我们上面的讨论,我们可以回答RQ2。
•对RQ2的回答:我们的选择策略可以自适应地选择最佳目标组合。
D.能量调度
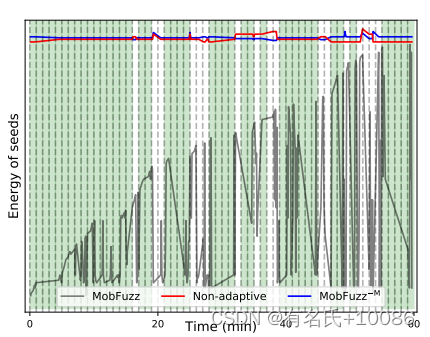
图5 在1小时内将自适应功率调度与非自适应功率调度以及没有MPMAB的MobFuzz−M功率调度进行比较。y轴显示了时间表分配的能量。绿色背景色表示在此时间间隔内,自适应调度根据所选择的目标组合进行能量调整,非自适应调度失败。
如上所述,目前尚无工作解决所选目标组合下的能量分配问题。为了证明所提出的自适应功率调度可以在选定的目标组合下为种子分配不同数量的能量,我们在图5中展示了所提出的调度、非自适应(即AFL的能量调度)和MobFuzz−M(没有MPMAB的MobFuzz)调度之间的比较。x轴表示一个小时的模糊测试过程。y轴显示了我们的自适应调度和其他分配的能量。x轴分为60分钟,每分钟代表一个选择不同目标组合的时间间隔。我们自适应调度根据所选择的目标组合自适应地分配能量,而非自适应调度在不同的目标组合下分配相同的能量对变化不敏感。在60分钟的时间里,所提出的调度在43分钟内优于非自适应调度,证明了自适应功率调度的有效性。
此外,MobFuzz−M调度的结果与非自适应调度的结果相似。这一结果表明,在没有MPMAB的情况下,MobFuzz无法自适应地选择最佳目标组合或分配适当的能量。因此,所选目标组合对应的能量分配没有变化。总之,MobFuzz和MobFuzz−M的对比实验证明了MPMAB的有效性。
为了回答我们的能量调度是否节省能源,我们进行了以下实验。表六为达到表三目标值的平均能耗。我们将其除以这些目标值的执行次数,并计算平均能量。从表中可以看出,在与基准模糊器的108对比较中,只有4对功率调度的平均能耗更高,分别是nm和pdfinfo。换言之,在96%以上的场景中,MobFuzz为目标分配的能量更少。例如,在readelf中,分配的能量比AFL少6倍(0.13 vs. 0.81)。在表格的Average行中,我们计算所有值的平均值。在所有平均值中,MobFuzz分配的能量较少。与AFL相比,在栈内存方面节省了50%以上的能耗。从上面的讨论中,我们可以回答RQ3。
•对RQ3的回答:我们的能量调度可以根据所选择的目标组合自适应分配能量,与基线模糊器相比节省更多的能量。

表6 达到模糊器目标值的平均能耗
E.NIC算法的评估:
1)好种子的结果:我们将在选定的目标组合中实现比平均值更大的目标值的种子定义为好种子。图6显示了MobFuzz和基线模糊器中生成的良好种子的百分比。从图中我们可以得出两个结论。首先,在所有12个目标程序中,MobFuzz中优秀种子的百分比大于基准模糊器;性能提升最小的是readelf,大约是2倍。如前所述,在NIC中,我们通过交叉、变异和执行来优化值。实验结果表明,MobFuzz中的NIC算法可以产生更多优于平均水平的种子,有助于优化目标。其次,在没有NIC算法的帮助下,基准模糊器的性能基本相似,良好种子所占比例较小;
此外,我们在图6中比较了MobFuzz和MobFuzz-N(没有NIC的MobFuzz)。当禁用NIC时,我们可以看到MobFuzz和MobFuzz-N之间的明显区别。MobFuzz-N中优良种子的百分比下降到未使用NIC的基准模糊器的水平。这一结果表明,在没有NIC的情况下,MobFuzz-N无法生成与MobFuzz一样多且目标值更大的优秀种子。最后,通过比较MobFuzz和MobFuzz-N,验证了NIC的有效性。
根据图5的结果,我们可以得出MPMAB和NIC之间存在协同作用: 1)p能量调度和NIC在选定的组合下执行。2) NIC输出具有最优值的Pareto种子。这些值会影响组合选择和能量调度。通过这种方式,这些部分可以相互配合。MPMAB和NIC的结合可以产生最好的效果。
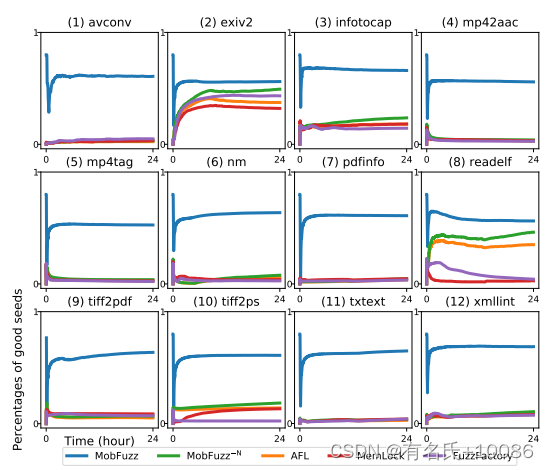
图6 在模糊测试中生成的好种子(达到大于所选目标组合平均值的种子)的百分比,值越大越好。MobFuzz−N表示不带NIC的MobFuzz。
2) 变异算子的结果:表7是NIC的变异算子与主模糊测试循环(即AFL的算子)的比较。根据表格,我们还可以得出两个结论。首先,从表中可以看出,在Time和Length列中,在24对比较中,NIC的时间消耗更少,长度也更短。对于tiff2ps目标程序,NIC比Main小13倍。在时间和长度的平均值方面,NIC也优于Main。与Main相比,时间缩短5.5%,长度缩短45.6%。实验结果表明,在该变异策略的帮助下,根据所选择的目标组合选择性能更好的算子,NIC可以实现更好的目标优化。
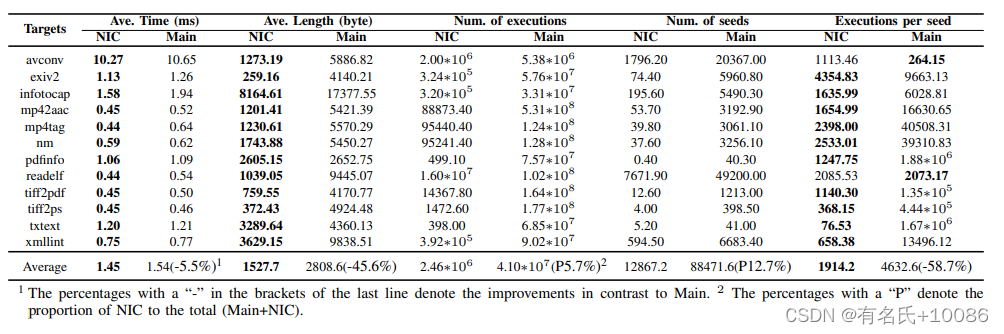
表7 主循环变异算子(main)和NIC变异算子的比较
其次,根据执行次数和种子列确定NIC的路径发现效率。Main(即主循环)和NIC的执行次数显示了每个部分中有多少种子被修改和执行。NIC的执行量占Main+NIC执行量的5.7%。如果我们禁用共享种子池机制,覆盖NIC中的新路径的输入将不会保存在种子池中,这5.7%的执行将被浪费。此外,NIC还发现了效率更高的种子节点。NIC仅用5.7%的执行生成12.7%的种子。最后两列显示了每个Main和NIC种子的执行情况。这些值表示查找新种子所需的执行次数。实验结果表明,NIC算法生成新种子节点的效率比NIC算法提高了58.7%。
3) NIC的性能开销:表给出了MobFuzz和其他两种配置的平均执行速度。MobFuzz−N表示不使用NIC算法的MobFuzz, MobFuzz−POR表示使用NIC但不减少NIC性能开销的MobFuzz。首先,在MobFuzz中启用NIC算法会给模糊测试过程带来3.3%的性能开销,这是可以接受的;虽然NIC会略微降低模糊测试的速度,但它可以产生多目标的最优结果。通过牺牲3.3%的速度,我们可以在其他目标上获得最佳结果。此外,MobFuzz的性能开销为3.3%,但仍然比基准模糊器快,如表3所示。其次,通过与MobFuzz−POR的比较,表明了NIC技术的性能提升。通过引入共享种子池等技术,模糊测试速度提高了14.3%,验证了所提技术在降低NIC性能开销方面的有效性。

表7 NIC算法的性能开销和所采用的技术对性能的改进
4)与黑盒MOO技术比较:将MobFuzz中的关键设计组件替换为NSGA-II中的现有设计,称为MobFuzzN2,与现有的黑盒MOO技术如nsgai[12]进行比较。表9给出了MobFuzz和MobFuzzN2在目标值上的比较。在第三- c节中,我们介绍了NIC中的3个方面的技术,包括自适应种群大小、共变异算子和开销减少。MobFuzzN2中没有采用这些技术。
MobFuzzN2使用固定的初始种群大小。在模糊测试开始时,这个规模对于较小的种子池来说太大了。过大的样本数量会降低模糊测试的速度,并且对提高客观值没有任何帮助。当种子池变大时,这个固定的初始种群大小不够。它缺乏多样性,不能产生最优结果。因此,我们使用自适应种群大小来处理这些问题。此外,通过在MobFuzzN2中实现自适应种群规模,使用MobFuzzN2+APS的结果来证明该技术的有效性。MobFuzzN2+APS在三个目标中取得了比MobFuzzN2更大的值。
在NIC中引入了共变异算子。NSGA-II的原始变异并不适用于模糊测试的情况。移除NSGAII中无效的变异算子。建立了目标和变异算子之间的联系。根据目标选择最佳算子。在表9中,MobFuzzN2与MobFuzzN2+CMO的比较证明了共变异算子的有效性。MobFuzzN2+CMO的所有目标值都更大。
在MobFuzzN2中,NSGA-II生成的种子独立于模糊测试主循环中的种子。只有在进化过程结束时,少量种子才保存到主种子池中。这种主模糊测试循环的独立性浪费了NSGA-II的执行,也是MobFuzzN2的主要性能开销。我们在MobFuzz中提出了一种共享种子池技术来解决这个问题。该技术将NIC连接到主模糊测试循环,并在NIC进化过程中保存种子。此外,通过降低MobFuzzN2的性能开销,MobFuzzN2+POR的速度结果远高于MobFuzzN2。这证明了减少开销技术的有效性。
- 对RQ4的回答:NIC可以在不引入额外性能开销的情况下优化目标。
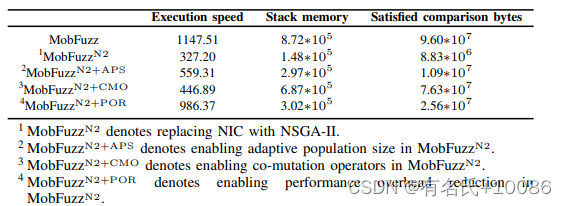
表9 与nsga-ii的目标值比较
F.MAGMA数据集
MAGMA[30]是一个新提出的数据集。它包含7个项目,19个目标项目。MAGMA是一个基于真实程序和真实bug的基准测试工具,能够对模糊测试器进行公正、准确的评估。
比较基准模糊器。实验采用AFL[7]、AFLFast[1]、AFL++[31](同时支持lto和cmplog)、FairFuzz[17]、honggfuzz[32]、MOPT[33]和SYMCC[34]。基于afl的模糊器使用一致的设置:deterministic和havoc。使用该配置可以全面测试MobFuzz与现有fuzzer相比的漏洞检测能力。
我们使用MAGMA提供的语料库目录中的种子作为初始种子。我们在3台服务器上进行了10次24小时的评估。
本小节中的实验也遵循MAGMA论文中的配置,分为两部分:1)模糊器发现的bug数量(由MAGMA工具脚本统计的独特bug结果)。表X显示了bug的结果,表11显示了结果的p值。2) bug时间(TTB结果)TTB结果如表12所示,结果的p值如表13所示。此外,每个bug的TTB结果见附录中的表18和19。
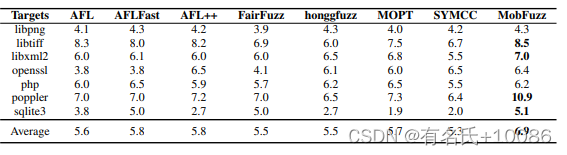
表10 模糊器发现的MAGMA bug平均数
1) Bug数量:表X显示了模糊器发现的Bug数量,表XI显示了这些结果的p值。结果显示,MobFuzz在7个测试项目中有4个测试优于所有基准模糊器。MobFuzz的平均bug数高于其他模糊器。此外,在sqlite3中,MobFuzz相对于基准模糊器的性能提升最大,大约是MOPT的3倍。MobFuzz与AFL、AFLFast、FairFuzz、honggfuzz和MOPT相比的一个优势是MobFuzz专注于令人满意的比较字节。通过满足更多的字节数,MobFuzz中的某些MAGMA bug可以更容易地被触发。例如,表19中的Bug SQL003只在满足if(!data)时触发。MobFuzz在9个小时内成功,而其他的则失败。
afl++ (cmplog启用)和SYMCC也可以解决这些比较字节。然而,MobFuzz在7个项目中仍然有6个优于afl++和SYMCC。原因是MobFuzz可以优化除比较字节之外的其他目标,而afl++和SYMCC则不能。根据上述实验可知,MobFuzz可以达到较大的栈内存消耗值。它帮助MobFuzz在MAGMA中触发这种bug。例如,Table XIX中的Bug SQL012就是一个栈缓冲区溢出Bug。MobFuzz在3.2小时内成功触发它,而afl++和SYMCC失败。
此外,MobFuzz表11中的p值均小于0.05。但是,有些结果大于0.05,例如libxml2中的FairFuzz。这说明MobFuzz的所有结果都具有统计学意义。
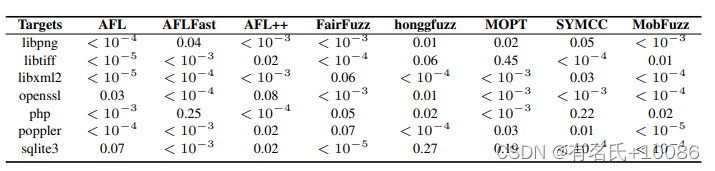
表11 表10结果中的P值
2)生成Bug时间:TTB结果如表12所示,这些结果的p值如表13所示。每个bug的详细TTB结果见表XVIII和表XIX。在7个项目中,MobFuzz有4个的性能优于所有基准模糊器。与AFLFast相比,poppler的性能提升最大,约为8倍。至于平均TTB, MobFuzz的TTB最少。原因是MobFuzz优化了执行速度并满足了比较字节数,这些目标有助于减少TTB。从详细结果来看,性能提升最大的是表19中的Bug PDF007。MobFuzz在2分钟内解决if(db→init.busy)和if(zObj == 0)问题。AFLFast在22.5小时内成功。
MobFuzz表13中的p值均小于0.05。然而,其他一些模糊器的测试结果大于0.05,例如libtiff中的AFL。这说明MobFuzz的所有TTB结果都具有统计学意义。
综上所述,在MAGMA数据集上,MobFuzz相比基准模糊器具有更好的bug检测能力,能够发现TTB更少的bug。
6. 讨论
A.超参数
根据我们在Section III-B中的设计,在我们的MPMAB模型中有两个参数。在等式2中,λ控制对目标的惩罚,从而减缓模糊测试过程。公式4中的γ决定了探索和利用之间的平衡。在本节中,我们将研究这些参数如何影响MobFuzz的性能。

表14 12个目标方案在不同λ取值下的目标平均值
表14给出了不同λ值下12个目标方案的目标平均值。我们选择5个λ来展示对MobFuzz性能的影响。在Speed列中,fuzzing的执行速度随着λ的增加而增加。理想情况下,我们可以选择最快的配置(λ = 10.00),因为正如前文所述,我们更喜欢速度。然而,当λ大于0.10时,栈内存消耗值和满足的比较字节数迅速下降,栈列减少约2倍,Cmp列减少约12倍。因此,我们平衡了目标的值,并选择0.10作为我们的λ配置。
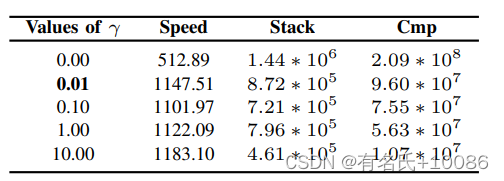
表15 不同γ值的12个目标程序目标值的平均值
表15给出了不同γ值的12个目标程序目标的平均值。在公式4中,该参数控制探索和利用之间的平衡。γ越大意味着探索越多,γ越少意味着开发越多。研究了γ的5个不同值以及γ如何影响MobFuzz的性能。当γ设置为0时,模型只考虑开发,根据公式4,具有更大历史值的目标将被分配更大的分数。在这种情况下,满意的比较字节数将获得最大的分数,因为Cmp值大于其他目标值。因此,可以达到2.09∗108的值。随着γ的增加,将有更多的探索。随着γ的增加,具有较小值的目标将被分配较大的分数。我们研究不同的γ值和目标值。我们最终选择0.01作为配置。这种配置可以通过适当的栈内存消耗值和需要比较的字节数来提高执行速度。
B.扩展到更多的优化目标
我们选择执行速度、栈内存消耗和满足的比较字节数作为本文的目标,这并不是说MobFuzz只能处理三个目标。通过对MobFuzz进行扩展,可以对3个以上的目标进行少量的优化。例如,如果我们想把有漏洞的函数调用次数作为MobFuzz的第4个目标,就需要检测源代码来记录有漏洞的函数。然后,我们需要修改MobFuzz配置中的目标数量。优化这4个目标不需要进一步修改。
C. 验证威胁
模糊测试中的随机性是影响[1],[10],[35],[17]有效性的主要因素。为了解决这个问题,我们进行了多次实验来计算平均值。我们在实验中给出了p值和A12![]() 值,以证明差异具有统计学意义。此外,我们实验的某些设置可以略有改进。例如,在图4中,我们只设置了6种比较选择策略。实验中可以引入更多的策略来丰富比较结果。
值,以证明差异具有统计学意义。此外,我们实验的某些设置可以略有改进。例如,在图4中,我们只设置了6种比较选择策略。实验中可以引入更多的策略来丰富比较结果。
7. 相关工作
A.模糊测试中的MAB模型
MAB模型处理的是我们在做出选择时,在有限的试验中优化总奖励的问题。在模糊测试中,有很多情况下我们需要最大化奖励。例如,模糊测试的最终目标是尽可能多地暴露bug。Woo等人[36]将参数配置建模为MAB问题以发现更多bug。然而,在CGF中,将更多能量分配给带有更多bug的手臂的想法将导致触发相同的bug。因此,MobFuzz的目标并不包括bug的数量。
此外,Patil等人在[37]上将分配执行到一个测试用例(能量)的过程形式化为上下文bandit问题。他们提出了一种通过策略梯度方法来控制能量的学习模型。Yue等人对该模型进行了改进,提出了一种对抗性单克隆抗体(VAMAB)模型的变体。他们将模糊测试过程的细节解释为VAMAB模型,并彻底考虑了探索和利用之间的平衡。然而,在多目标情况下,我们提出了MPMAB模型。与之前的工作相比,MPMAB模型处理了多个选择组合在一起的问题。当我们需要做出多个决策时,例如目标组合选择和能量分配,经典的MAB模型是不够的。MLMAB模型在这些多重选择场景中取得了进展。
B.模糊测试中的多目标优化问题
根据研究,现有的fuzzing工具有3种是针对多目标的。与我们的NIC算法一样,Cerebro在[12]中使用了帕累托前沿和非支配排序的思想。Cerebro和MobFuzz之间存在差异。首先,Cerebro不选择目标组合。如上所述,目标之间存在着内在的联系,这就要求我们在当前形势下选择最合适的目标。第二个区别是优化过程是否是一个进化过程。在Cerebro中,种子经过非支配排序,计算出Pareto前沿,即当前最优结果。然而,这个过程在一个模糊测试周期中只执行一次。我们认为它不能产生全局最优解。通过[12]进化过程计算Pareto前沿并达到收敛通常需要100次以上的迭代。此外,MOOFuzz[38]与Cerebro有类似的想法。因此,我们认为它也不能产生全局最优解。
与现有模糊测试器MOO相比,MobFuzz能够根据测试状态选择目标组合,并在不引入额外开销的情况下将进化过程融入到模糊测试中。基于此,可以在不浪费时间的情况下得到多个目标的全局最优解。对于FuzzFactory (two-objective mode)[20],它在处理多目标时更加不成熟。它使用两个连续的if语句来确定哪个更好,这可能会产生问题。例如,它通过if(AX > AY){if(BX > BY){prefer X}} 或者
if(BX > BY){if(AX > AY){prefer X}}.。将目标A放在B之前或将B放在目标A之前都会导致错误的目标优化。相比之下,MobFuzz通过进化过程产生最优值,不会陷入上述不正确的情况
C.能量调度
CGF的能量调度控制一个种子上的突变和执行的数量。AFL原能量调度分配的能量大于实际需要[1],[10]。AFLFast[1]是改进AFL能量调度的开创性工作。使用转移概率模型描述程序路径之间的关系。AFLFast通过能量调度和搜索策略降低了AFL的能耗。之后,Yue等人通过对抗性单抗模型的变体提出了EcoFuzz[10]来描述路径转换和种子奖励中的细节。基于该模型,将模糊测试过程划分为不同的状态,并在这些状态中分配不同的能量值。此外,Entropic[28]提出了一种基于熵的能量调度,将更多的能量分配给具有更多信息的种子。相比之下,MobFuzz利用MPMAB模型来解决两个问题,包括能量分配问题。首先,选取目标组合;然后,根据选择的种子组合自适应地为种子分配合适的能量;本文的主要贡献是将能量调度扩展到路径覆盖范围之外。AFLFast和EcoFuzz在能量分配上都强调了种子的路径发现能力,而熵中的信息熵也与覆盖率有关。本文根据所选择的目标,设计能量调度来分配能量。MobFuzz能够根据当前目标更自适应地调整能量,拓宽了CGF中功率调度的应用场景,这是与以往工作的关键区别。
D.种子选择
在模糊测试活动中,模糊测试者需要在前一轮模糊测试结束时选择一个种子进行模糊测试。根据模糊器的目标在种子池中选择最佳的种子是非常重要的。例如,AFL更喜欢执行速度更快、长度更短的种子。当一个种子被标记为受欢迎时,它将在下一轮中以更高的概率被选中。在AFL算法之后,MemLock[8]算法和FuzzFactory[20]算法分别选择内存消耗更大和满足比较字节数更多的种子算法。然而它们在选择种子时都只尝试优化一个目标。如上所述,在许多情况下,我们需要优化多个目标以找到更深层次的bug。在模糊测试中只使用一个目标无法达到需要多个触发条件的bug。相比之下,我们注意到CGF对多目标的考虑不足和处理不当。在此基础上,设计MPMAB模型对目标进行自适应选择和能量分配,并利用NIC对目标进行优化。AFLGo[39]和CollAFL[35]也有各自的选择目标。然而,它们需要复杂的程序分析才能完成任务。与它们不同的是,MobFuzz不需要额外的静态分析来优化目标。IJON[40]提出了一种标注机制来帮助分析人员选择种子并指导模糊测试过程。与之相比,MobFuzz是一种无需人工指导模糊测试过程的自动化模糊测试工具。















 3019
3019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









