









拉依达检验法(pauta)
拉依达公式:

S为样本标准差,3s水平相当于显著水平0.01,2s相当于显著水平0.05
Xp为当前检验的样本参数值,与其相减的为样本参数值的平均值。
其中:
需要注意的是,使用拉依达法则剔除一遍异常值后,需要对剔除异常值后的新样本集进行重新检验,反复循环直到不能再剔除新的异常值样本为止。而这也是该脚本设计的难点,对剔除的异常样本进行记录、对多个分类的新样本集进行判断、并重复这一过程;
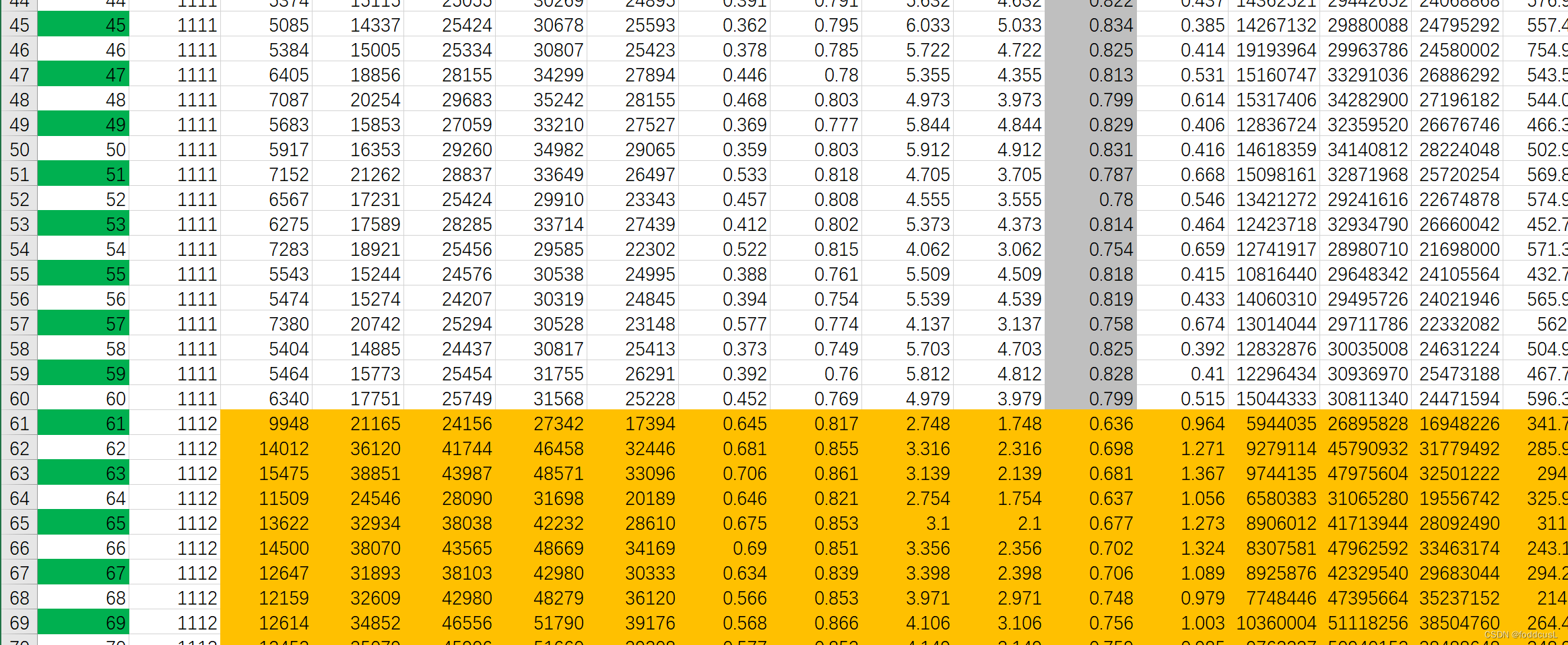
程序中输入的表格展示:
没有参数表头,第一列位样本序号,第二列为样本分类标识(每个分类只对该分类的集合做异常值检验),后续为各种参数;我在程序中设置了对参数的异常值检验到第13列(第11个参数)的参数;(我这个样本量为239,4个分类,超过17个属性参数)
程序参考:
%author foddcus Fufu email foddcus@163.com
%拉伊达检验法;不同样本在不同行,不同参数不同列
%输入 data:数据表格
%输出:Error 异常样本所在的行数,以及异常的参数内容
close all
clear all
%%输入区域
data=xlsread("D:\同步空间\备份文件\采集数据库\苹果\10月.xlsx");
%按数字标识的方法
nameNum=[1111,1112,1113,1114];%输入每个分类的数字标识(只支持数值对样本进行分类的表格)
[ys,xs]=size(nameNum);
endnum=13;%最后监测参数的位置
cnum=0;
%%
if cnum==0
n=0;
moredata=[];
nn=0;
errorF=[0,0];
[ynum,xnum]=size(data);
Compare=[ynum,ynum];
for u=1:100%上限是100次重复
k=0;
maxR=min(Compare);
for i=1:xs
indexForlist=find(data(:,2)==nameNum(1,i));
[indexR,indexL]=size(indexForlist);
for j=1:indexR%将选中的数据分开存放
if j>maxR
moredata(j-maxR,:)=[data(indexForlist(j,1),1:endnum)];
break
end
datapile(j,:,i)=[data(indexForlist(j,1),1:endnum)];%数据开头是该行数据在原本excel中的行数
end
end
for i=1:xs
Slist(i,:)=std(datapile(:,3:end,i));
Ave(i,:)=mean(datapile(:,3:end,i));
end
for i=1:xs
[indexR,indexL]=size(datapile(:,3:end,i));%计算目前数据的尺寸
for y=1:indexR
R=0;
for x=1:indexL
if (datapile(y,x+2,i)-Ave(i,x))>3*Slist(i,x)%注意datapile的第一列是标识
n=n+1;%算子n,用于基本计数
k=k+1;%算子k,用于判断中断
R=R+1;%算子R,用于矫正输出位置
if find(errorF(:,1)==datapile(y,1,i))
errorF(nn,1+R)=x;
else
nn=nn+1;%算子nn,用于矫正输出位置
errorF(nn,1:2)=[datapile(y,1,i),x];
end
end
end
end
end
if k==0
break%如果本次没有监测到误差,退出循环
end
%%删除异常样本,方便重新计算
data=[];
[yx,xx]=size(errorF);
indexS=[0];
for i=1:xs
enum=0; %先删光某个处理的异常样本,好赋值
for j=1:yx
if find(datapile(:,1,i)==errorF(j,1))
indexS(enum+1,1)=find(datapile(:,1,i)==errorF(j,1));
enum=enum+1;
end
end
idata=datapile(:,:,i);
if indexS~=0
ASort=sort(indexS(:));%让其从小到大排列
for e=1:enum
idata(ASort(e)+1-e,:)=[];
end
end
%%三维矩阵必须保持每个层积的大小一致,所以这里要取巧,就取最小样本的处理做最大的判断范围
data=[data;idata];%返回值
[Compare(1,i),no]=size(idata);
end
data=[moredata;data]%返回未检验的量
moredata=[];
clear datapile
end
end
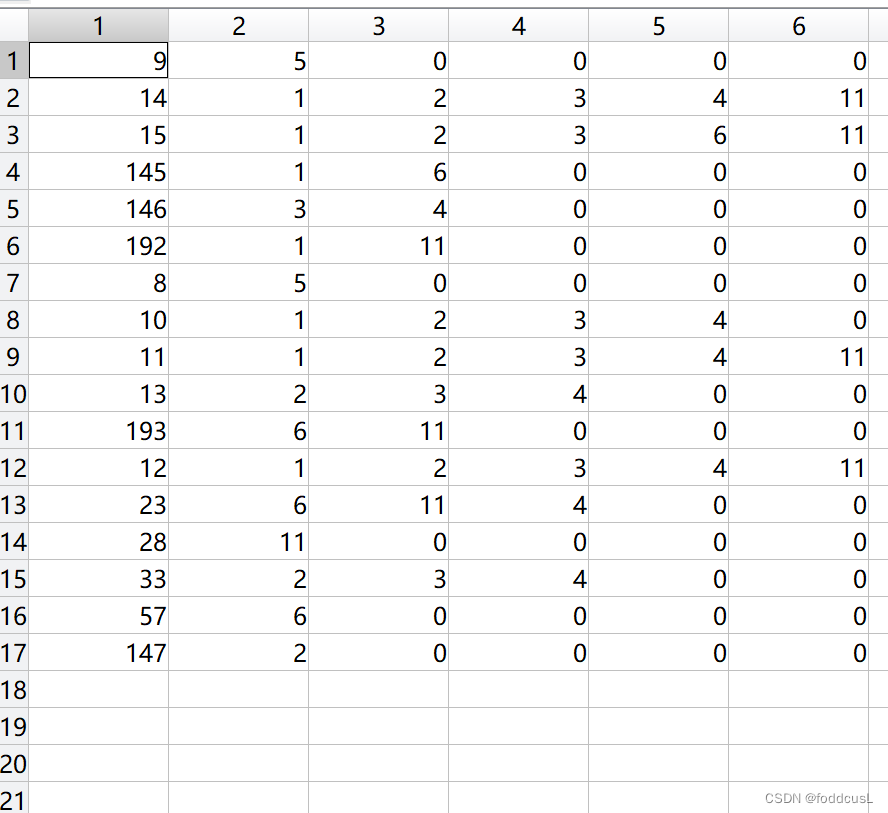
errorF输出:
输出参数errorF:第一列为异常值所在行数,后面的值是该所在行数的对应的第几个参数是被当作异常值检验出来的。如第一行:说明序号9的样本出现了异常值,出现异常值的参数为第5个参数;第二行:说明序号14的样本出现了异常值,出现异常值的参数为第1、2、3、4、11个参数。
函数形式的代码段参考
%author foddcus Fufu email foddcus@163.com
%拉伊达检验法;不同样本在不同行,不同参数不同列 类别名称因在第2列,第一列为序号
%输入 data:数据表格 nameNum名称矩阵即名称代号如[111,112,113] cnum开关 0为开 endnum:检验的最后列数
%输出:Error 异常样本所在的行数,以及异常的参数内容
%%输入区域
function errorF=CKOpatua(data,nameNum,endnum,cnum)
%按数字标识的方法
[ys,xs]=size(nameNum);
%%
if cnum==0
n=0;
moredata=[];
nn=0;
errorF=[0,0];
[ynum,xnum]=size(data);
Compare=[ynum,ynum];
for u=1:100%上限是100次重复
k=0;
maxR=min(Compare);
for i=1:xs
indexForlist=find(data(:,2)==nameNum(1,i));
[indexR,indexL]=size(indexForlist);
for j=1:indexR%将选中的数据分开存放
if j>maxR
moredata(j-maxR,:)=[data(indexForlist(j,1),1:endnum)];
break
end
datapile(j,:,i)=[data(indexForlist(j,1),1:endnum)];%数据开头是该行数据在原本excel中的行数
end
end
for i=1:xs
Slist(i,:)=std(datapile(:,3:end,i));
Ave(i,:)=mean(datapile(:,3:end,i));
end
for i=1:xs
[indexR,indexL]=size(datapile(:,3:end,i));%计算目前数据的尺寸
for y=1:indexR
R=0;
for x=1:indexL
if (datapile(y,x+2,i)-Ave(i,x))>3*Slist(i,x)%注意datapile的第一列是标识
n=n+1;%算子n,用于基本计数
k=k+1;%算子k,用于判断中断
R=R+1;%算子R,用于矫正输出位置
if find(errorF(:,1)==datapile(y,1,i))
errorF(nn,1+R)=x;
else
nn=nn+1;%算子nn,用于矫正输出位置
errorF(nn,1:2)=[datapile(y,1,i),x];
end
end
end
end
end
if k==0
break%如果本次没有监测到误差,退出循环
end
%%删除异常样本,方便重新计算
data=[];
[yx,xx]=size(errorF);
indexS=[0];
for i=1:xs
enum=0; %先删光某个处理的异常样本,好赋值
for j=1:yx
if find(datapile(:,1,i)==errorF(j,1))
indexS(enum+1,1)=find(datapile(:,1,i)==errorF(j,1));
enum=enum+1;
end
end
idata=datapile(:,:,i);
if indexS~=0
ASort=sort(indexS(:));%让其从小到大排列
for e=1:enum
idata(ASort(e)+1-e,:)=[];
end
end
%%三维矩阵必须保持每个层积的大小一致,所以这里要取巧,就取最小样本的处理做最大的判断范围
data=[data;idata];%返回值
[Compare(1,i),no]=size(idata);
end
data=[moredata;data]%返回未检验的量
moredata=[];
clear datapile
end
end后续:
考虑到当初些这个算法的时候,编程水平还比较稚嫩,脚本有一些不足的地方;后面我对该脚本进行了重新设计,新的脚本更加稳定和准确,详情请看:matlab 基于拉依达检验法(3σ准则) 实现多类别多参数的批量异常样本检验 V2.0-CSDN博客














 1354
1354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









