






摘要
将解决多目标优化的分解方法引入解决多目标进化优化的问题中。
MOEA/D将一个多目标优化问题分解成多个单目标优化问题......
然后就一些实验结果的说明,和MOGLS、NSGAII比较哪里好,以及MOEA/D自身相关的实验研究。
引言
求出所有的PS(也就是完整的PF)非常耗时,而且没必要,所以一般求出一定数量、均匀分布的PS即可。传统分解的方法有很多,例如加权求和法、切比雪夫法、边界交会法。
由于,支配没有定义目标空间中解之间的完全排序(也就是同一层非支配解之间本身是无序的,虽然在NSGA以及NSGAII中按照拥挤距离排序),并且为了产生更多具有多样性的PS,所以原先的评价和选择方法不太实用,需要改进,例如如下。

其实以上谈论的就是收敛性和多样性这两方面策略的考虑。
MOEA/D的一些技术要点以及算法特点如下。


用到的3种分解方法
加权求和法Weighted Sum Approach
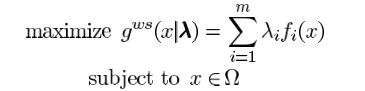
当求最小值问题时,maximize应改为minimize

切比雪夫法Tchebycheff Approach
![]()
![]()
当求最小值问题时,Zi* = min{fi(x)|x ∈ Ω}

边界交会方法Boundary Intersection (BI) Approach
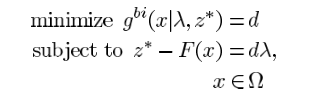
当求最小值问题时,F(x) - z* = d

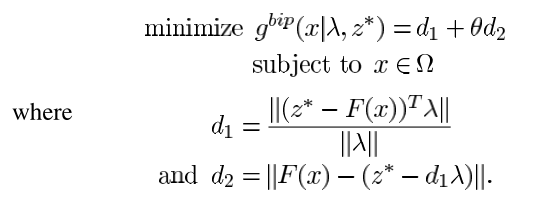
其中 > 0是惩罚因子,此时这种方法称为PBI,PBI的优缺点如下。

至于每个分解方法的优化方向、理想PS点参考【1】【2】
MOEA/D算法流程
准备工作
采取切比雪夫法对目标函数进行分解,分解成N个子问题。
除了是N个子问题,还是N个种群个体数,因为将求出每个子问题的最优解组成种群。也就是说,每随机初始化一组,可得到一个单目标优化子问题,从而得到不同的最优解(也就是不同的个体),最后组成种群。
总结算法核心:
分解方法和权重向量、交叉变异算子意味着个体的多样性,探索
选择算子、邻居子问题内进行优化子问题以更新种群意味着问题的收敛性,开发
而选择算子蕴含在哪里呢?就在Step 2.1)中,随机选择了当前子问题的两个邻居子问题的当前最优解作为父母来进行交叉,虽然不是根据适应度函数来进行评价选择,但是其实有选优这个意思。就在Step 2.4)中,一个切比雪夫的函数就相当于一个单目标函数,根据目标函数大小直接选择并替换种群。
交叉选择/选择:mating selection/selection包括形成mating pool
交叉、变异:reproduction包括crossover、mutation
环境选择/更新种群:environment selection/replacement包括fitness computation
【注】:有时即使有均匀分布的权重向量也不一定能得到均匀分布的帕累托最优解,具体能否得到还得看选择什么样的分解方法、什么样的权重向量。当然这篇论文研究重点不是分解方法,而是提供解决基于分解方法的多目标优化问题的框架。
算法流程

多的不谈,直接看代码。
实验
和MOLGS比较
和NSGAII比较
自身相关研究实验
问题
技术相关问题
1.最开始,需要初始化G、N、T、权重向量、种群,如何选择合适的初始化方法?
G
N
T
权重向量
种群
2.计算B(i)时,一定要用欧氏距离吗,不能用其他距离吗?
3.从B(i)中选择随机选择两个邻居个体和
,为何要随机选择,不能直接选择除i外距离i最近的两个邻居个体吗?
4.交叉、变异算子什么策略(包括交叉概率、变异概率)?
5.计算Z*时,为什么只要大于m中的一个分量,就可以取替换那个分量?
6.更新种群时,为什么要替换所有能替换的邻居个体,不能只替换i个体吗?
7.切比雪夫的一些细节:刚开始离直线很远时的移动方向,是上方的朝下,下方的朝左,而后来越来越靠近直线“多”的那一侧,就不满足这个规律了。
评价相关问题
1.和一般的遗传算法有哪些区别,有哪些你认为可以改进的地方?
2.该算法有哪些优缺点,请以批判的眼光评价分析。
缺点:一般来说,MOEA/D中权重向量的均匀性可以保证帕累托最优解的多样性,但当目标MOP具有复杂的帕累托前沿(例如不连续的PF,具有尖峰或低尾的PF)时,就不能工作了。
3.该算法是如何想到的,有哪些可以借鉴的地方?















 1509
1509











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









