







编写Scrapy爬虫
唉!!搬砖好累 先放个图吧 😏

-
以抓取腾讯视频热搜为例
https://v.qq.com/biu/ranks/?t=hotsearch -
创建项目
scrapy startproject qqvideohot
cd qqvideoho
scrapy genspider hot v.qq.com
- 修改settings.py
ROBOTSTXT_OBEY=False
ITEM_PIPELINES = {
'qqvideohot.pipelines.QqvideohotPipeline': 300,
}
- 增加items.py字段
program_title = scrapy.Field()
program_url = scrapy.Field()
- 编写爬虫
import scrapy
from scrapy.utils.log import logger
from qqvideohot.items import QqvideohotItem
class HotSpider(scrapy.Spider):
name = 'hot'
allowed_domains = ['v.qq.com']
start_urls = ['https://v.qq.com/biu/ranks/?t=hotsearch&channel=rank/']
def parse(self, response, **kwargs):
item = QqvideohotItem()
for hot_program_xpath in response.xpath('//ul[@class="table_list"]/li')[1:]:
program_title = hot_program_xpath.xpath('div[1]/a/text()').extract_first()
program_url = hot_program_xpath.xpath('div[1]/a/@href').extract_first()
logger.info(program_title + program_url)
item['program_title'] = program_title
item['program_url'] = program_url
yield item
- 运行
scrapy crawl hot
搭建Scrapyd
-
安装Scrapyd
pip install scrapyd -
启动Scrapyd
scrapyd命令行会输出Web端访问地址
http://localhost:6800/ -
修改qqvideohot项目中的scrapy.cfg文件
# Automatically created by: scrapy startproject # # For more information about the [deploy] section see: # https://scrapyd.readthedocs.io/en/latest/deploy.html [settings] default = qqvideohot.settings [deploy] url = http://localhost:6800/ project = qqvideohot -
注册qqvideohot到Scrapyd
scrapyd-deploy -p qqvideohot --version 0.0.1 # 输出 Packing version 0.0.1 Deploying to project "qqvideohot" in http://localhost:6800/addversion.json Server response (200): {"node_name": "DESKTOP-M5396QF", "status": "ok", "project": "qqvideohot", "version": "0.0.1", "spiders": 1}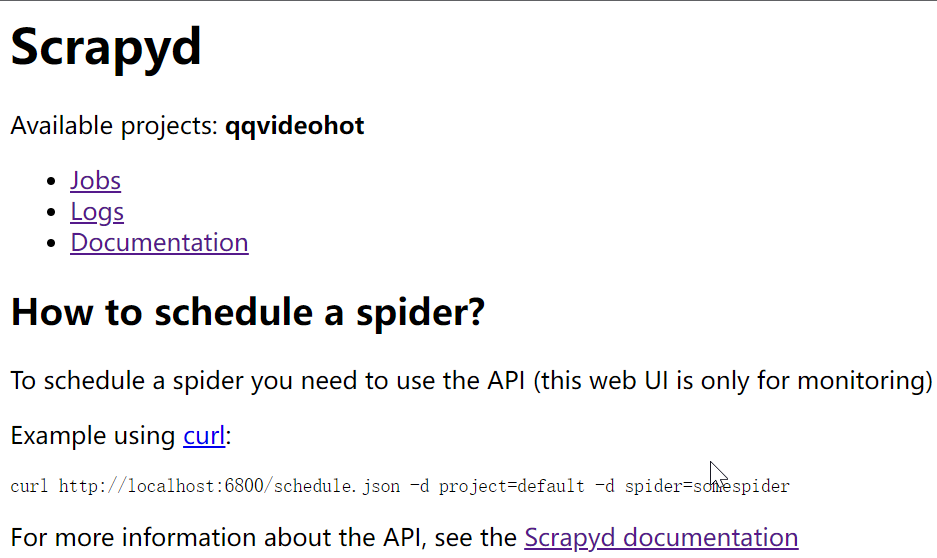
-
从Scrapyd启动爬虫
curl http://localhost:6800/schedule.json -d project=qqvideohot -d spider=hot #输出 {"node_name": "DESKTOP-M5396QF", "status": "ok", "jobid": "73abcaa2597811ecbe3370c94ed895fc"}点击Logs可以查看日志
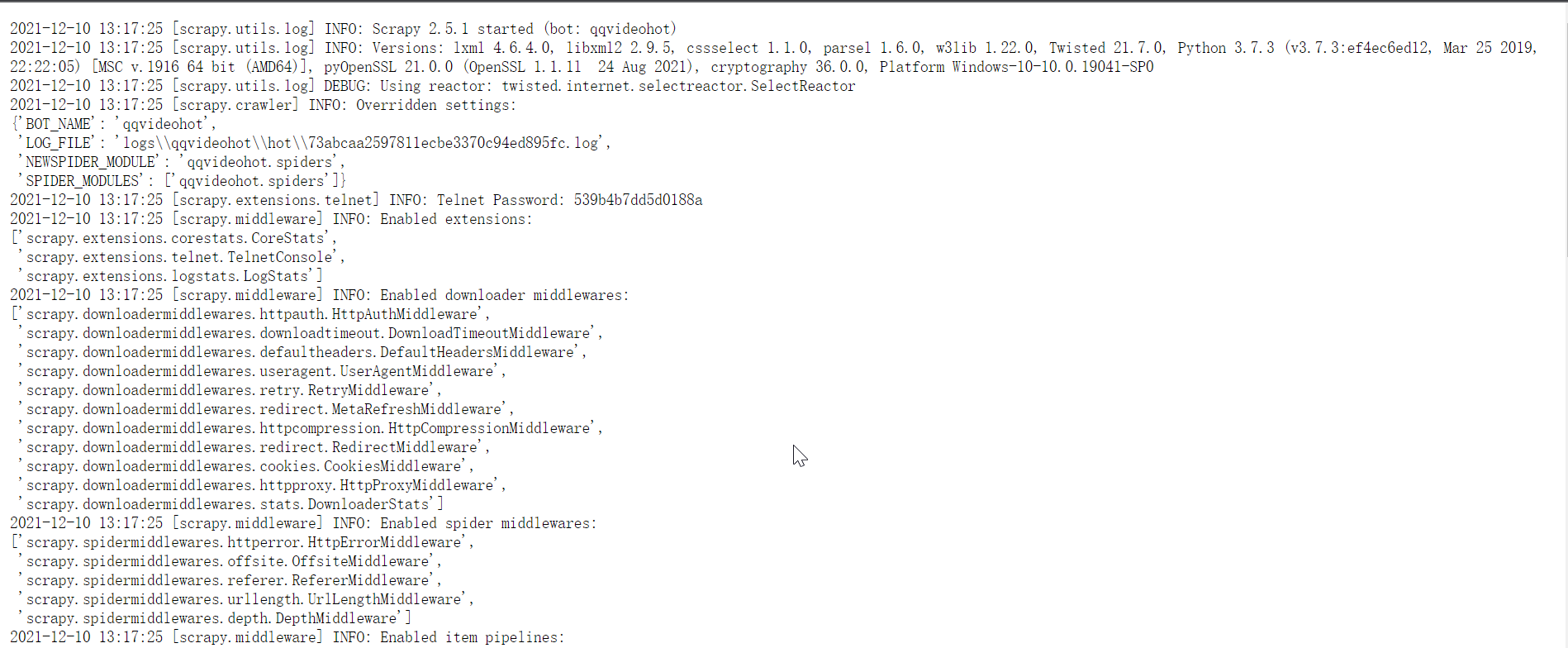
-
Scrapyd命令小结
# 创建任务并启动 curl http://localhost:6800/schedule.json -d project=<爬虫项目名> -d spider=<爬虫名> # 删除任务 curl http://localhost:6800/delproject.json -d project=<爬虫项目名> # 获取某个项目的待处理、正在运行和已完成作业的列表 curl http://localhost:6800/listjobs.json?project=<爬虫项目名> | python -m json.tool # 获取上传到此 Scrapy 服务器的项目列表 curl http://localhost:6800/listprojects.json
可视化工具搭建
-
安装包
pip install scrapyd-client spiderkeeper -
启动SpiderKeeper
spiderkeeper # 访问地址 http://localhost:5000 -
生成egg文件
cd 到爬虫项目下
scrapyd-deploy --build-egg qqvideohot.egg # 输出 Writing egg to qqvideohot.egg -
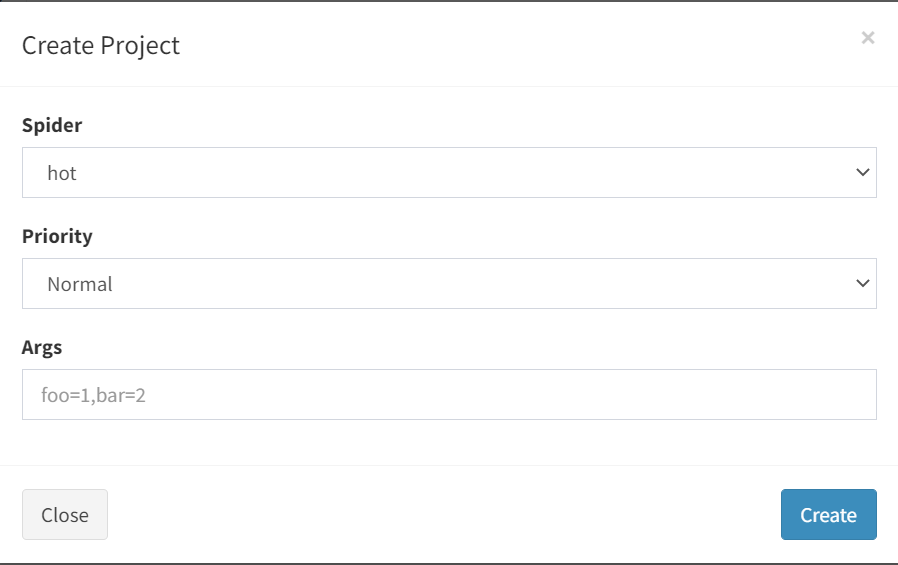
创建爬虫任务
-
点击Create Project
-
输入爬虫项目名 qqvideohot
-
上传刚才生成的
qqvideohot.egg文件
上传成功
-
-
运行
回到主页点击Run
qqvideohot项目hot爬虫已经运行完成
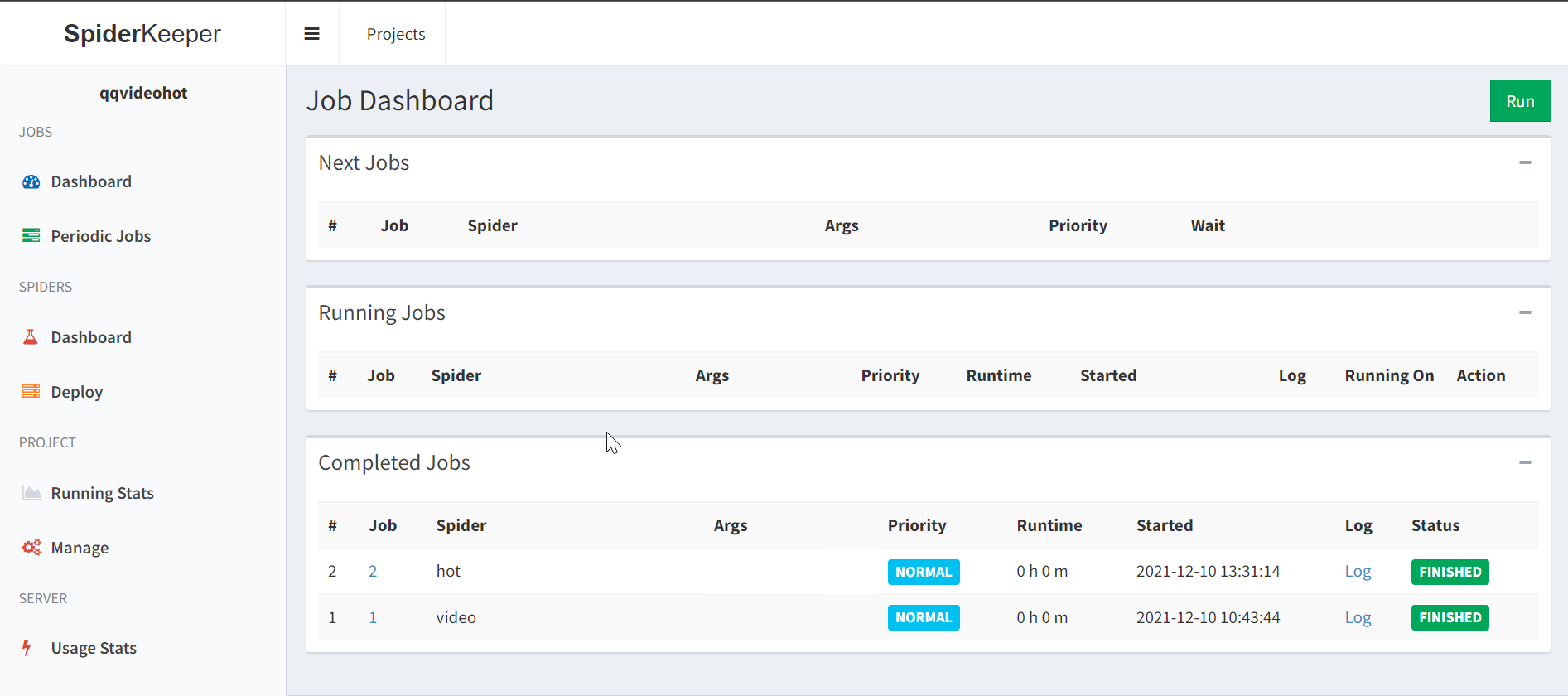
可以点击log查看日志
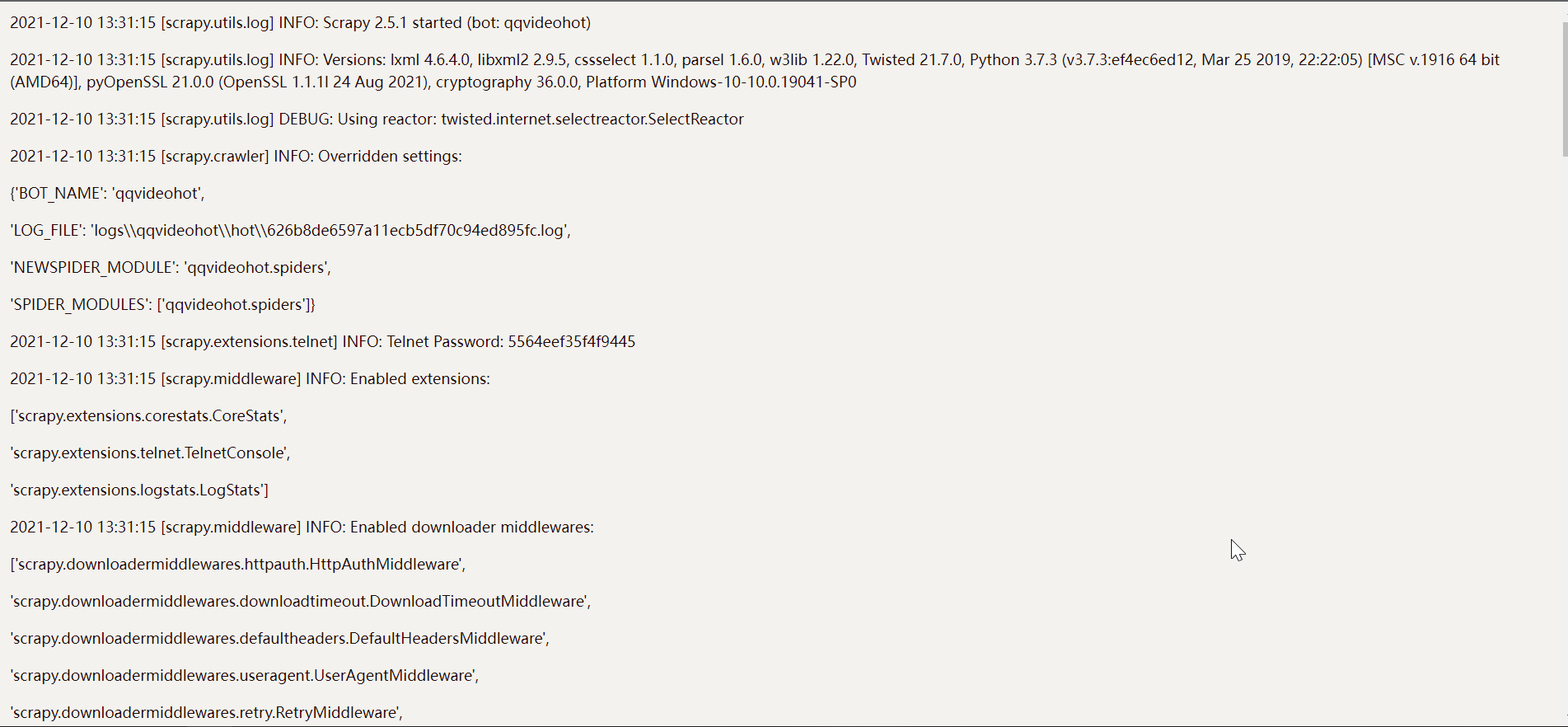
-
创建自定义爬虫任务
点击 Periodic Jobs 中的 Add Job
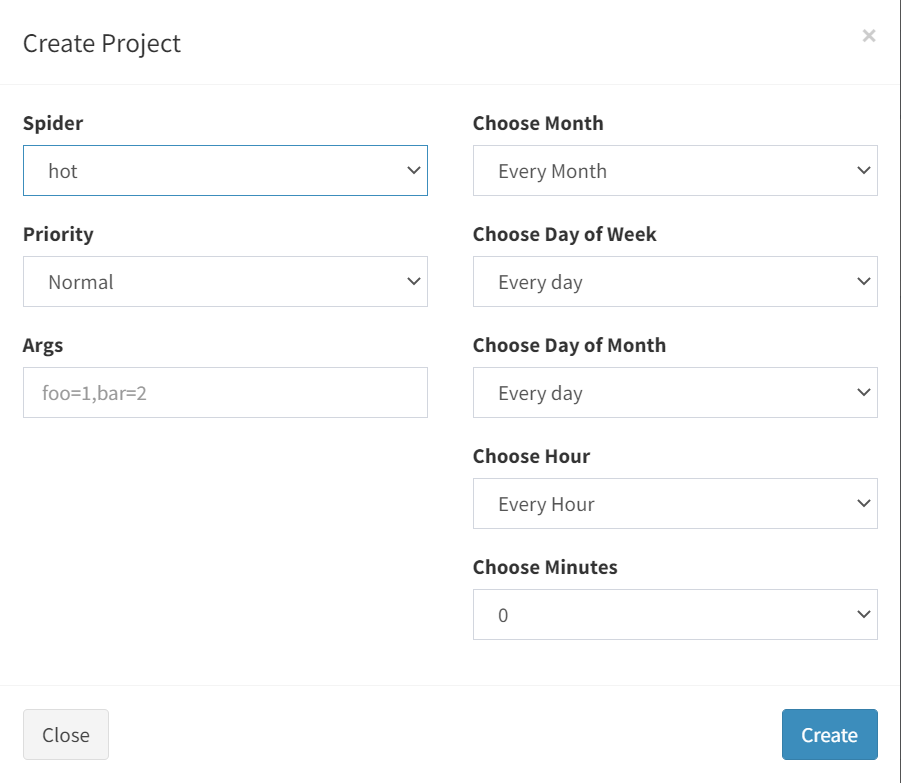
在这里可以创建自己业务需求的任务类型
-
查看运行状态
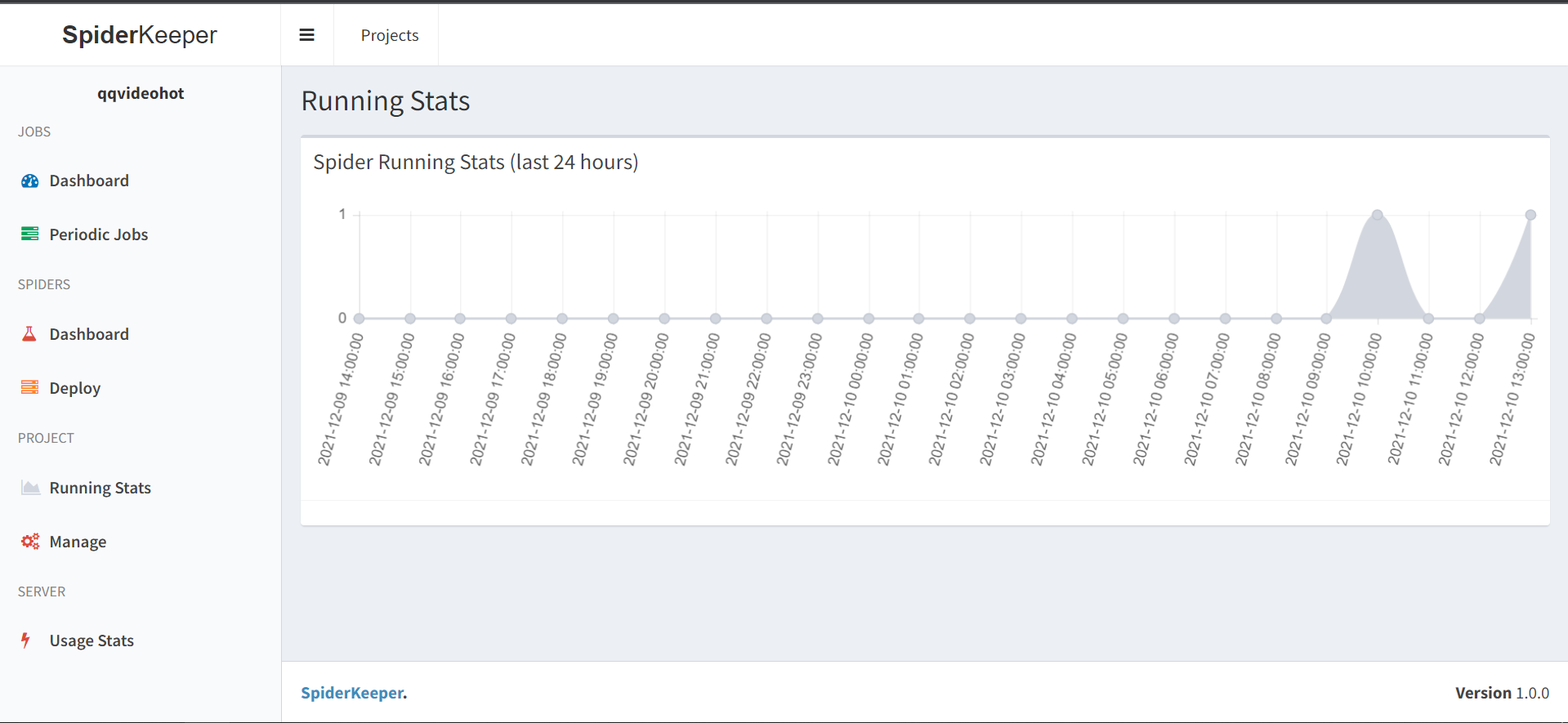
本文链接地址:https://www.cnblogs.com/gaotangshi/p/15670801.html
关于 Scrapy 可视化的学习
Gtang 2021-12-10
评论和私信会在第一时间回复。或者直接私信我。
本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!















 2752
2752











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









