







一、题目
leetcode链接:
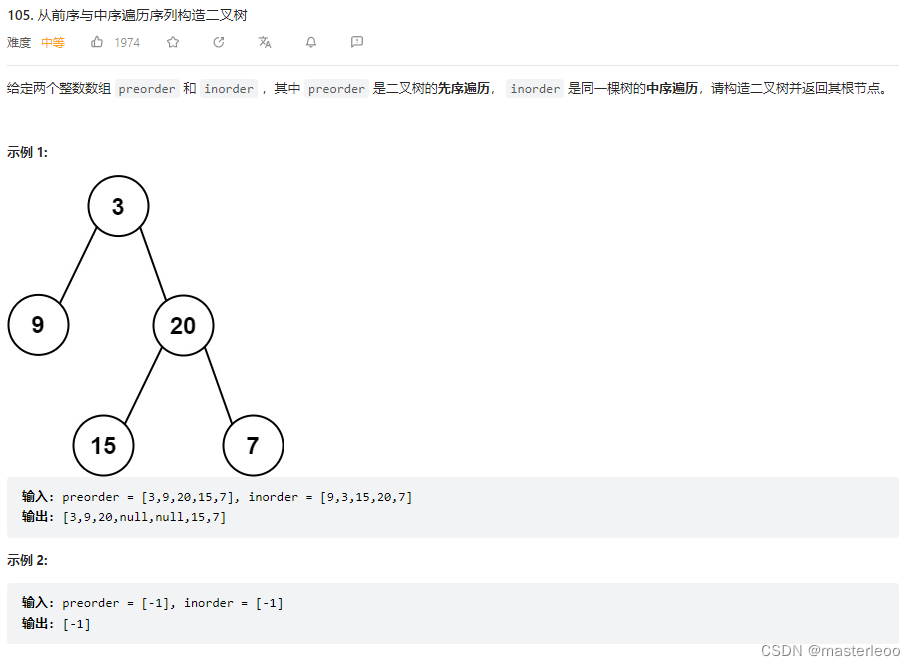
从前序与中序遍历序列构造二叉树
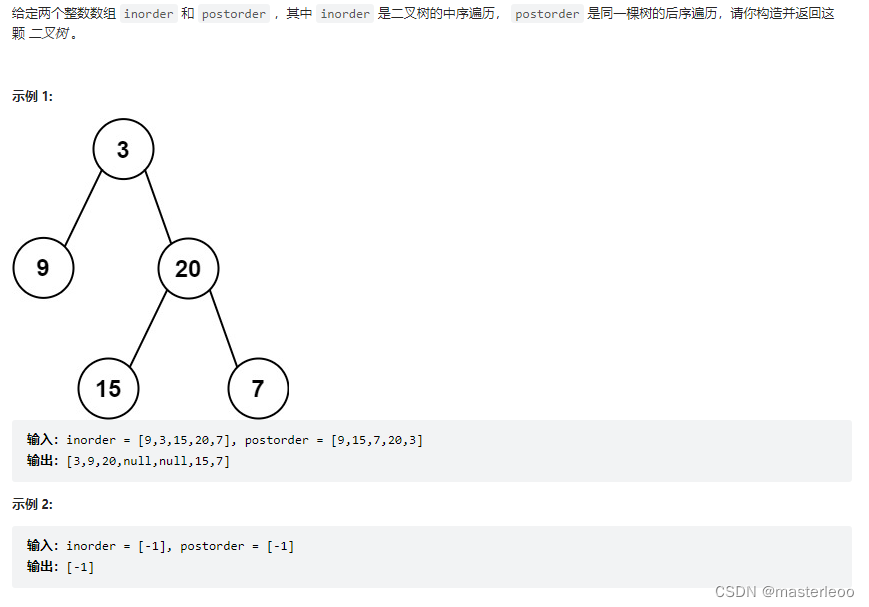
从中序与后序遍历序列构造二叉树
二叉树的前序、中序、后序、层序遍历:
前序遍历:根节点+左子树+右子树
中序遍历:左子树+根节点+右子树
后序遍历:左子树+右子树+根节点
详见该博文链接,解释的很清楚: link
二、递归解法
1、对于前序和中序遍历构造二叉树,我们可以发现一个特点就是根节点可以很容易获取,即前序数组的第一个值;
2、要使用递归解法还是需要想清楚边界条件和非边界条件;
3、非边界条件就是原问题怎么分解为子问题,要构造二叉树,那么可以先获取根节点,再获取左右子树各自的范围区间,这样起码知道了哪些区间可以再用来构造左右子树,于是子问题不就可以继续分解下去:获取根节点—>寻找左右子树的区间。而中序数组恰好提供了左右子树的区间,根节点左/右边的区间为该根节点对应的左/右子树;
4、对于非边界条件:可以这么想,子问题不断分解下去,左右子树的区间一定会变为0,此时就是边界条件,要返回空节点。
5、代码实现上有几个小细节需要注意:
- 在前序数组中获取根节点的值以后,如何快速找到中序数组中根节点的位置:可以使用哈希表in_map,保存中序数组inorder的 值和位置索引 为 key和value;
- 创建另一个函数作为递归函数,并把preleft, preright, inleft, inright作为参数传入,分别表示子树的前序左边界、前序右边界、中序左边界、中序右边界。
- 在buildsubtree的递归函数中要使用引用传参,有两个好处:将引用作为函数的参数进行传递,可以实现对实参的直接操作和修改;避免在函数内部产生参数的副本,消耗内存,可以提高程序的效率,在处理大型对象时可以节省内存和时间开销。在这里主要是第二个作用,因为如果对于in_map不使用引用&,力扣提交时会报错:“超出时间限制”
6、第二个问题:后序和中序遍历构造二叉树也类似。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
TreeNode* buildsubtree(vector<int>& preorder, vector<int>& inorder, unordered_map<int, int>&in_map, int preleft, int preright, int inleft, int inright){
//递归的边界条件:左右边界相遇说明遍历节点结束,返回空节点
if (preleft > preright || inleft > inright){
return nullptr;
}
int preroot = preorder[preleft]; //前序数组中的对应子树的根节点
int inroot_idx = in_map[preroot]; //中序数组中对应根节点的下标索引值
int leftsubtree_len = inroot_idx - inleft; //中序数组中的左子树的区间长度
TreeNode* root = new TreeNode(preroot); //建立根节点
//递归构造左子树:前序数组的范围为:左边界preleft+1 ~ preleft+左子树长度
//中序数组的范围为:左边界inleft ~ 根节点索引inroot_idx - 1
root->left = buildsubtree(preorder, inorder, in_map, preleft+1, preleft+leftsubtree_len, inleft, inroot_idx-1);
//递归构造右子树:前序数组的范围为:左边界preleft+左子树长度+1 ~ 右边界preright
//中序数组的范围为:根节点索引+1 ~ 右边界inright
root->right = buildsubtree(preorder, inorder, in_map, preleft+leftsubtree_len+1, preright, inroot_idx+1, inright);
return root;
}
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
unordered_map<int, int> in_map;
int n = inorder.size();
for (int i = 0; i < n; i++){
in_map[inorder[i]] = i;
}
return buildsubtree(preorder, inorder, in_map, 0, n-1, 0, n-1);
}
};
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
private:
unordered_map<int, int> in_map;
public:
TreeNode* buildsubtree(vector<int>& inorder, vector<int>& postorder, int inleft, int inright, int postleft, int postright){
// 边界条件为中序和后序数组中左右边界相遇
if (inleft > inright || postleft > postright){
return nullptr;
}
int post_root = postorder[postright]; // 后序数组中的右边界为根节点
int inroot_idx = in_map[post_root]; // 中序数组中根节点的索引
// 获取中序数组中右子树的长度
int rightsubtree_len = inright - inroot_idx;
TreeNode* root = new TreeNode(post_root); // 创建根节点
// 递归构造左子树:中序数组的范围:左边界inleft ~ 根节点索引值-1
// 后序数组的范围:左边界postleft ~ 右边界 - 右子树长度 - 1
root->left = buildsubtree(inorder, postorder, inleft, inroot_idx-1, postleft, postright - rightsubtree_len - 1);
// 递归构造右子树:中序数组的范围:根节点索引值+1 ~ 右边界
// 后序数组的范围:右边界-右子树长度 ~ 右边界 - 1 ,因为右边界为根节点
root->right = buildsubtree(inorder, postorder, inroot_idx+1, inright, postright - rightsubtree_len, postright - 1);
return root;
}
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
int n = inorder.size();
for (int i = 0; i < n; i++){
in_map[inorder[i]] = i;
}
return buildsubtree(inorder, postorder, 0, n-1, 0, n-1);
}
};














 1068
1068











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









