







词典编码的思路:常见的数据文件如文本文件、图像、源代码文件等,数据本身包含有重复字符这个特性。如果用一些简单的代号代替这些字符,就可以实现压缩。字符串与代号的对应表就是词典。
提出的问题:
1.词典是如何形成的?
在编码端动态生成,解码端根据索引号动态同步建立词典。编解码端预置单字符词条。
2.新词条怎么形成的,与已有词条是否有关系
以下介绍第二类词典编码——LZW:
LZW编码原理
(1)LZW的编码思想是不断地从字符流中提取新的字符串,通俗地理解为新“词条”,然后用“代号”也就是码字表示这个“词条”。这样一来,对字符流的编码就变成了用码字去替换字符流,生成码字流,从而达到压缩数据的目的。
(2)LZW编码是围绕称为词典的转换表来完成的。LZW编码器通过管理这个词典完成输入与输出之间的转换。LZW编码器的输入是字符流,字符流可以是用8位ASCII字符组成的字符串,而输出是用n位(例如12位)表示的码字流。
(3)LZW编码算法的步骤如下:
步骤1:将词典初始化为包含所有可能的单字符,当前前缀P初始化为空。
步骤2:当前字符C=字符流中的下一个字符。
步骤3:判断P+C是否在词典中
(1)如果“是”,则用C扩展P,即让P=P+C,返回到步骤2。
(2)如果“否”,则
输出与当前前缀P相对应的码字W;
将P+C添加到词典中;
令P=C,并返回到步骤2
LZW解码原理
LZW解码算法开始时,译码词典和编码词典相同,包含所有可能的前缀根。具体解码算法如下:
步骤1:在开始译码时词典包含所有可能的前缀根。
步骤2:令CW:=码字流中的第一个码字。
步骤3:输出当前缀-符串string.CW到码字流。
步骤4:先前码字PW:=当前码字CW。
步骤5:当前码字CW:=码字流的下一个码字。
步骤6:判断当前缀-符串string.CW 是否在词典中。
(1)如果”是”,则把当前缀-符串string.CW输出到字符流。
当前前缀P:=先前缀-符串string.PW。
当前字符C:=当前前缀-符串string.CW的第一个字符。
把缀-符串P+C添加到词典。
(2)如果”否”,则当前前缀P:=先前缀-符串string.PW。
当前字符C:=当前缀-符串string.CW的第一个字符。
输出缀-符串P+C到字符流,然后把它添加到词典中。
步骤7:判断码字流中是否还有码字要译。
(1)如果”是”,就返回步骤4。
(2)如果”否”,结束。
实验步骤
1.首先调试LZW的编码程序,以一个文本文件作为输入,得到输出的LZW编码文件。
(1)以下为输入的文本文件:

输入命令行参数,调试程序
可得输出的LZW编码文件:

2.以实验步骤一得到的编码文件作为输入,编写LZW的解码程序。
int DecodeString( int start, int code){
int count; //count标记数组下标
count = start;
while (0 <= code) //code为-1时,到达树根节点,循环结束
{
d_stack[count] = dictionary[code].suffix; /*将下标为code节点中的新字符放置于数组相应位置*/
code = dictionary[code].parent; //节点上移至母节点处
count++; //数组下标增加1
}
return count;//返回字符串长度
}
void LZWDecode( BITFILE *bf, FILE *fp)
{
int character; //新或旧编码的第一个字符
int new_code, last_code; //new_code为码流中下一个码字(新码字),last_code为上一个解码码字(旧码字)
int phrase_length; //输出字符串长度
unsigned long file_length; //输入文件长度
file_length = BitsInput(bf, 4 * 8); //读取输入的待解码文件大小
if (-1 == file_length) file_length = 0;
InitDictionary(); //初始化词典,预置0~255单字符词条
last_code = -1; //初始时上一个解码码字为空
while (0 < file_length) {
//解完最后一个码字后退出循环
new_code = input(bf); //读入新码字
if (new_code >= next_code) {
// 新码字不在词典中
d_stack[0] = character; //character为上一个码字对应字符串的第一个字符,将其放入d_stack栈数组顶部d_stack[0]中
phrase_length = DecodeString(1, last_code);//遍历上一个码字last_code所在树,将last_code对应的字符串放入d_stack栈数组中,返回字符串长度
}
else {
//新码字在词典中
//遍历新码字new_code所在树,将new_code对应字符串放入d_stack栈数组中,返回字符串长度
phrase_length = DecodeString(0, new_code);
}
character = d_stack[phrase_length - 1];//若新码字在词典中,character为新码字对应字符串的第一个字符;若新码字不在词典中,character为上一个码字对应字符串的第一个字符
while (0 < phrase_length) {
//若新码字在词典中,输出新码字对应字符串;若新码字不在词典中,输出上一个码字对应的字符串+上一个码字对应字符串的第一个字符
phrase_length--;
fputc(d_stack[phrase_length], fp);
file_length--;//待解码文件长度-1
}
if (MAX_CODE > next_code) {
/*当新码字在词典中,将上一个码字对应的字符串 + 新码字对应字符串的第一个字符添加到词典中;
当新码字不在词典中,将上一个码字对应的字符串 + 上一个码字对应字符串的第一个字符添加到词典中*/
AddToDictionary(character, last_code);
}
last_code = new_code;//新码字变为上一个码字
}
}
将步骤一得到的编码文件作为输入,得到解码文件如下:

可看出解码后的文件与编码前的原始文本文件一样。
说明当前码字在词典中不存在时应如何处理并解释原因:
当前码字不在词典中只有一种情况:在编码端新词条刚写入就用上了,解码端还没跟上。所以在解码时遇到当前码字不在词典中的情况时,该码字对应的字符串也即是解码的结果应为上一码字对应的字符串+上一码字对应字符串的第一个码字。将该结果作为新词条写入词典中,并输出字符流。再将该码字作为上一个码字,继续解码下一码字。
用PPT上的例子进行测试:

编码后词典增加的词条如下:
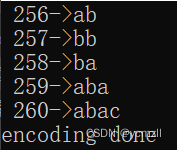
以编码后的文件为输入,进行解码,解码端词典新增的词条为:
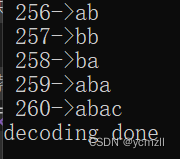
可验证上述情况。
3.选择至少十种不同格式类型的文件,使用LZW编码器进行压缩得到输出的压缩比特流文件。对各种不同格式的文件进行压缩效率的分析。

对以上文件使用LZW编码器进行压缩得到输出的压缩比特流文件如下:
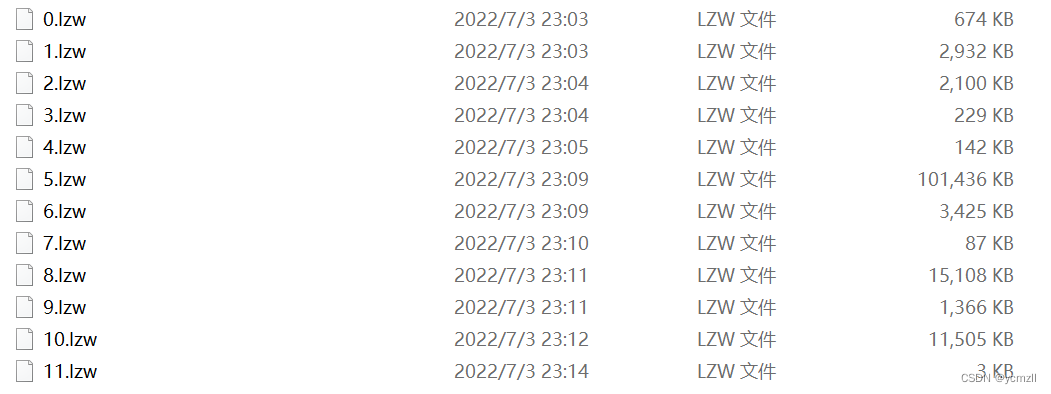
比较压缩前后文件大小,计算压缩比:
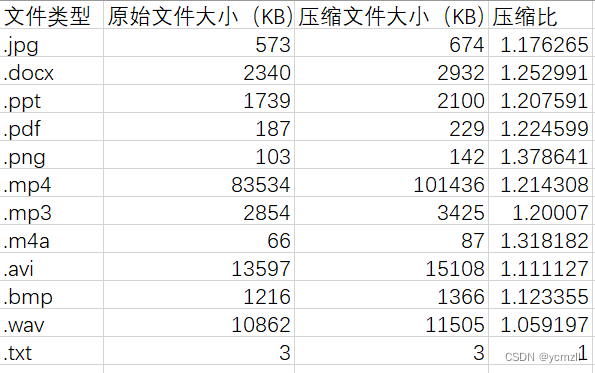
由上可以看出,除了txt文件,其他文件经过lzw编码器编码后反而更大了。lzw编码是用码字去替换字符流,如果文件数据中有较多的重复字符,可以达到较好的压缩效果且形成的词典也较小,比如txt文件。而上述的其他文件可能因为文件中重复字符较少,形成的词典较大,反而达不到文件压缩的效果。
附件:总代码
lzw.c:
/*
* Definition for LZW coding
*
* vim: ts=4 sw=4 cindent nowrap
*/
#define _CRT_SECURE_NO_WARNINGS
#include <stdlib.h>
#include <stdio.h>
#include "bitio.h"
#define MAX_CODE 65535
struct {
int suffix;
int parent, firstchild, nextsibling;
} dictionary[MAX_CODE+1];
int next_code;
int d_stack[MAX_CODE]; // stack for decoding a phrase
#define input(f) ((int)BitsInput( f, 16))
#define output(f, x) BitsOutput( f, (unsigned long)(x 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1220
1220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









