




 本文介绍了如何加载经典的鸢尾花数据集,并使用pandas进行数据整理,包括为特征列命名和添加类别标签,以便于数据可视化和后续的机器学习分析。通过这些步骤,数据变得更加直观易读。
本文介绍了如何加载经典的鸢尾花数据集,并使用pandas进行数据整理,包括为特征列命名和添加类别标签,以便于数据可视化和后续的机器学习分析。通过这些步骤,数据变得更加直观易读。

Iris 鸢尾花数据集是一个经典数据集,在统计学习和机器学习领域都经常被用作示例。
数据集内包含 3 类共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:
花萼长度、花萼宽度、花瓣长度、花瓣宽度
可以通过这4个特征预测鸢尾花卉属于(iris-setosa, iris-versicolour, iris-virginica)中的哪一品种。
1、加载鸢尾花数据集
from sklearn import datasets
from pandas import DataFrame
import pandas as pd
x_data=datasets.load_iris().data #特征集
y_data=datasets.load_iris().target #标签集
print("鸢尾花特征数据集:\n",x_data)
print("鸢尾花标签数据集:\n",y_data)
运行如下:
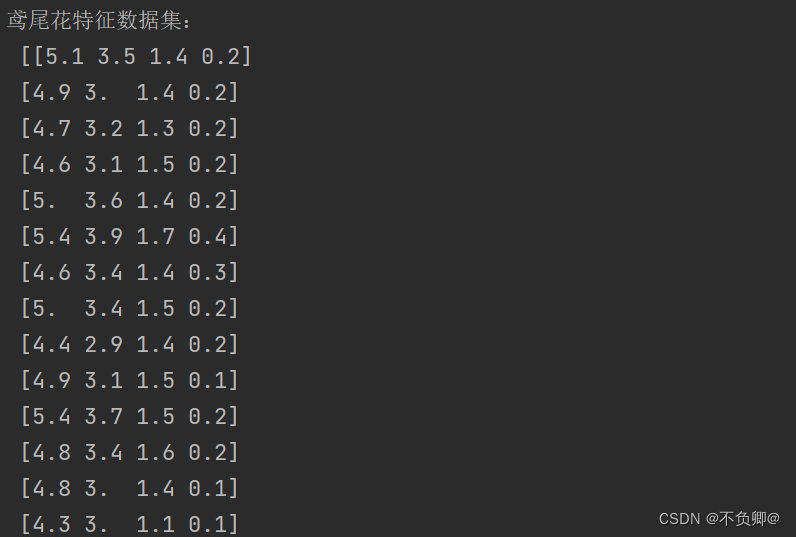
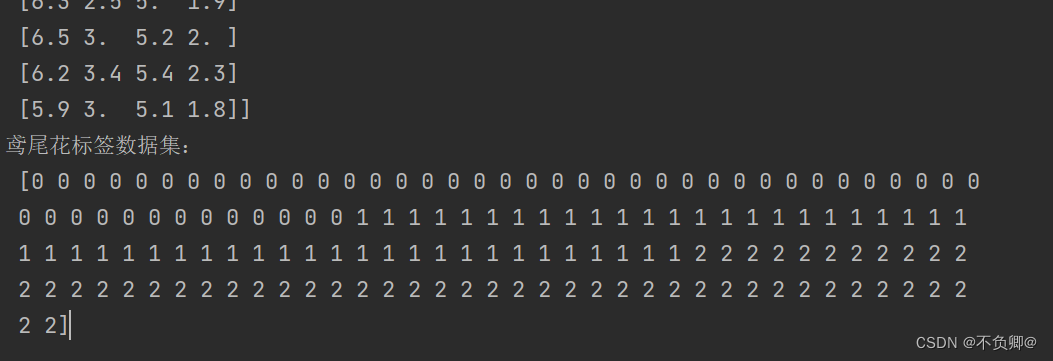
可以看到加载成功,但是,显然对我们小白不太有好,我们把每一列加个名字
2、为每一列数据增加一个名字
修改上面代码为:
from sklearn import datasets
from pandas import DataFrame
import pandas as pd
x_data=datasets.load_iris().data #特征集
y_data=datasets.load_iris().target #标签集
print("鸢尾花特征数据集:\n",x_data)
print("鸢尾花标签数据集:\n",y_data)
#下面是新增代码
x_data=DataFrame(x_data,columns=['花萼长','花萼宽','花瓣长','花瓣宽'])
pd.set_option('display.unicode.east_asian_width',True) #设置列明对齐
print("鸢尾花特征数据集:\n",x_data)
运行结果:
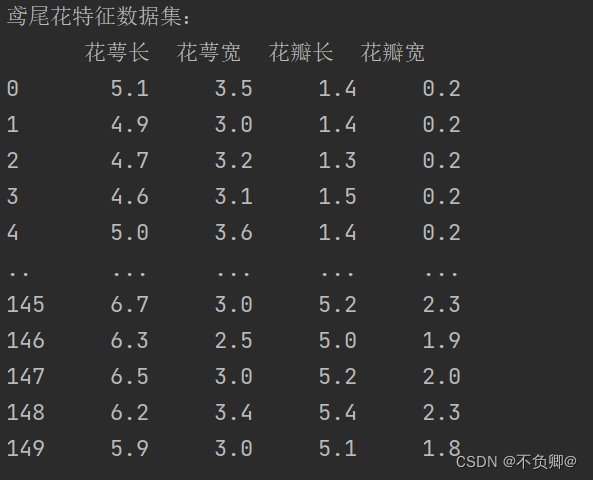
3、为了更直观的预览数据,给每一行数据合并标签
修改上面代码为:
from sklearn import datasets
from pandas import DataFrame
import pandas as pd
x_data=datasets.load_iris().data #特征集
y_data=datasets.load_iris().target #标签集
print("鸢尾花特征数据集:\n",x_data)
print("鸢尾花标签数据集:\n",y_data)
x_data=DataFrame(x_data,columns=['花萼长','花萼宽','花瓣长','花瓣宽'])
pd.set_option('display.unicode.east_asian_width',True)
print("鸢尾花特征数据集:\n",x_data)
#下面是新增代码
x_data['类别']=y_data #在特征集上新增一列,特征,数据为 标签集 y_data
print("鸢尾花特征数据集:\n",x_data)
运行结果:
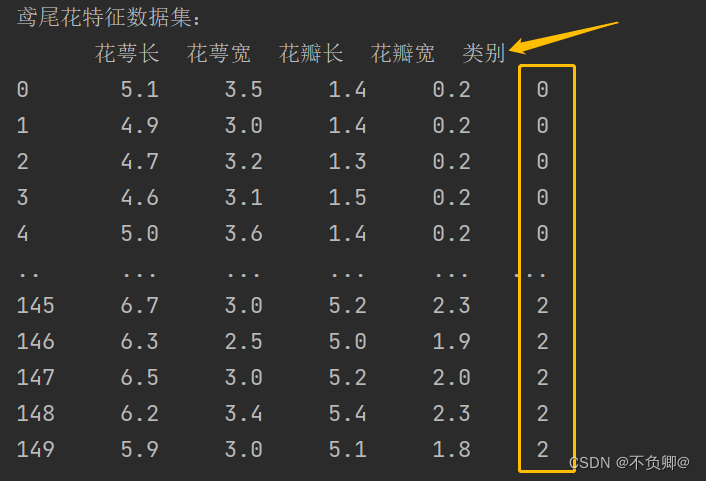




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











