







1、Income数据集
Income数据集是机器学习、深度学习实验线性回归的典型学习数据:下载Income数据集
它主要有两类数据,受教育年限和对应的收入情况
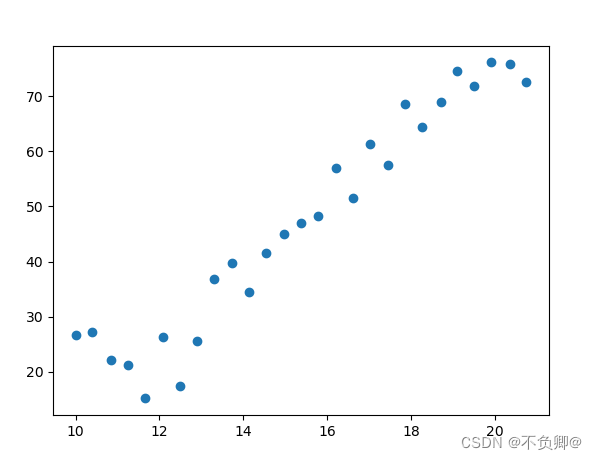
通过散点图可以观察到,明显呈线性关系
数据预览:
散点图:
2、创建模型
2.1导入数据、定义特征和标签
import tensorflow as tf
import pandas as pd
import matplotlib.pyplot as plt
data=pd.read_csv("./Income.csv")
# 定义输入特征x 和对应标签y
x=data.Education
y=data.Income
2.2创建模型
#顺序模型:只有一个输入和一个输出。tf.keras.Sequential()就是一个顺序模型
model=tf.keras.Sequential() #初始化模型
model.add(tf.keras.layers.Dense(1,input_shape=(1,))) #添加层
model.compile(optimizer='adam',loss='mse') # 配置训练项 mse均方差 梯度优化Adam
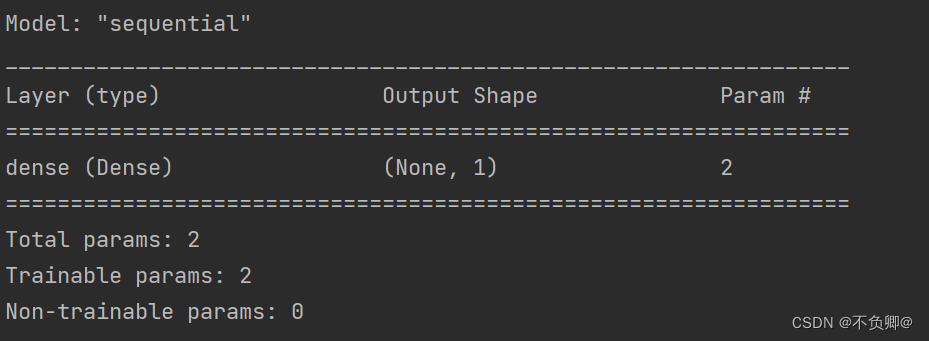
通过:model.summary()函数查看一下模型
3、训练模型
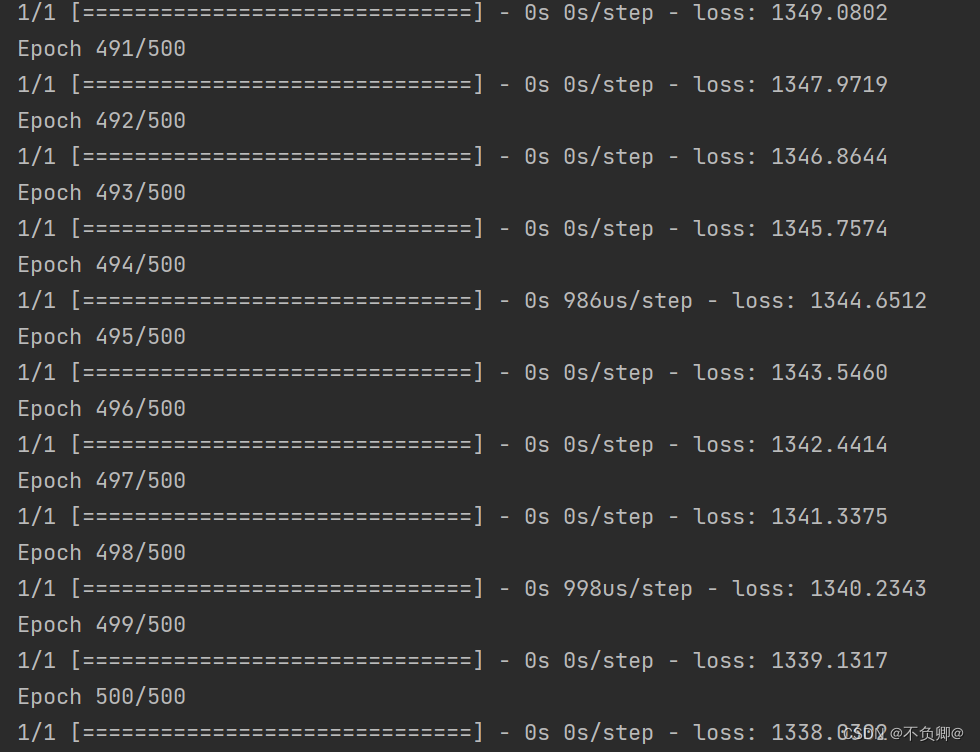
model.fit(x,y,epochs=500)
#x y 喂入上面定义的数据特征和标签 epochs是训练迭代次数
训练结果:
4、完整代码
import tensorflow as tf
import pandas as pd
import matplotlib.pyplot as plt
data=pd.read_csv("./Income.csv")
x=data.Education
y=data.Income
model=tf.keras.Sequential()
model.add(tf.keras.layers.Dense(1,input_shape=(1,)))
model.summary()
model.compile(optimizer='adam',loss='mse')
h=model.fit(x,y,epochs=500)
















 1351
1351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











