






一.学习知识点概括
这章节主要了解了几个重要的模型,包括逻辑回归模型,树模型与集成模型,并对这三种模型进行对比,了解到了模型的评估方法和评价结果,最后学习到了三种调参方法。这次的学习收获多多。但是今天因为在家太懒惰了,很晚才开始学习…
二.学习内容
下面的内容都是根据别人的文章节选过来学习的T-T
1.逻辑回归模型
逻辑回归是应用非常广泛的一个分类机器学习算法,它将数据拟合到一个logit函数(或者叫做logistic函数)中,从而能够完成对事件发生的概率进行预测。

下图中X为数据点肿瘤的大小,Y为观测结果是否是恶性肿瘤。通过构建线性回归模型,如hθ(x)所示,构建线性回归模型后,我们设定一个阈值0.5,预测hθ(x)≥0.5的这些点为恶性肿瘤,而hθ(x)<0.5为良性肿瘤。

但很多实际的情况下,我们需要学习的分类数据并没有这么精准,比如说上述例子中突然有一个不按套路出牌的数据点出现,如下图所示:

现在再设定0.5,这个判定阈值就失效了,而现实生活的分类问题的数据,会比例子中这个更为复杂。
数据在空间下的分布代码如下:
from numpy import loadtxt, where
from pylab import scatter, show, legend, xlabel, ylabel
#load the dataset
data = loadtxt('/home/HanXiaoyang/data/data1.txt', delimiter=',')
X = data[:, 0:2]
y = data[:, 2]
pos = where(y == 1)
neg = where(y == 0)
scatter(X[pos, 0], X[pos, 1], marker='o', c='b')
scatter(X[neg, 0], X[neg, 1], marker='x', c='r')
xlabel('Feature1/Exam 1 score')
ylabel('Feature2/Exam 2 score')
legend(['Fail', 'Pass'])
show()
得到的结果如下:

2.决策树模型
ID3算法
ID3算法的核心是在决策树各个结点上对应信息增益准则选择特征,递归地构建决策树。具体方法是:从根结点(root node)开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子节点;再对子结点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有特征可以选择为止,最后得到一个决策树。ID3相当于用极大似然法进行概率模型的选择。
递归创建决策树时,递归有两个终止条件:第一个停止条件是所有的类标签完全相同,则直接返回该类标签;第二个停止条件是使用完了所有特征,仍然不能将数据划分仅包含唯一类别的分组,即决策树构建失败,特征不够用。此时说明数据纬度不够,由于第二个停止条件无法简单地返回唯一的类标签,这里挑选出现数量最多的类别作为返回值。
3.GBDT模型
CART回归树
GBDT是一个集成模型,可以看做是很多个基模型的线性相加,其中的基模型就是CART回归树。
CART树是一个决策树模型,与普通的ID3,C4.5相比,CART树的主要特征是,他是一颗二分树,每个节点特征取值为“是”和“不是”。
回归树生成
一个回归树对应的输入空间的一个划分,假设已经将输入空间划分为M个单元R1,R2,R3…Rm,并且每个单元都有固定的输出值cm,其中I为判别函数。
当输入空间确定时,可以用平方误差来表示回归树在训练数据上的预测误差:
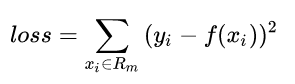
则知道单元Rm上的最优输出值就是Rm内所有样本xi对应yi的均值。
回归树剪枝
剪枝的损失函数可以如下表示:
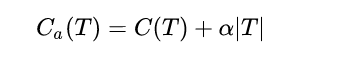
其中C(T)为对训练数据的误差,|T|为树的节点数量,其中alpha类似于一个turning parameter,调节的是到底要精准度还是要模型的简单性。(过拟合与欠拟合)
GBDT模型
GBDT模型是一个集成模型,是很多CART树的线性相加。
GBDT模型可以表示为以下形式,我们约定ft(x)表示第t轮的模型,ht(x)表示第t颗决策树,模型定义如下:
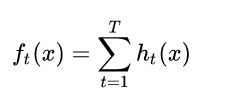
提升树采用前向分步算法。第t步的模型由第t-1步的模型形成,可以写成:
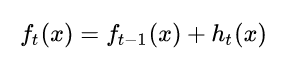
损失函数自然定义为这样的:
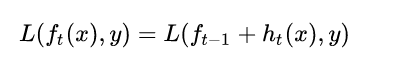
4.模型对比与性能评估
逻辑回归
优点
a.训练速度较快,分类的时候,计算量仅仅只和特征的数目相关;
b.简单易理解,模型的可解释性非常好,从特征的权重可以看到不同的特征对最后结果的影响;
c.适合二分类问题,不需要缩放输入特征;
d.内存资源占用小,只需要存储各个维度的特征值;
缺点
a.逻辑回归需要预先处理缺失值和异常值【可参考task3特征工程】;
b.不能用Logistic回归去解决非线性问题,因为Logistic的决策面是线性的;
c.对多重共线性数据较为敏感,且很难处理数据不平衡的问题;
d.准确率并不是很高,因为形式非常简单,很难去拟合数据的真实分布;
决策树模型
优点
a.简单直观,生成的决策树可以可视化展示
b.数据不需要预处理,不需要归一化,不需要处理缺失数据
c.既可以处理离散值,也可以处理连续值
缺点
a.决策树算法非常容易过拟合,导致泛化能力不强(可进行适当的剪枝)
b.采用的是贪心算法,容易得到局部最优解
要来不及了,今天就学习到这吧!!剩下的明天找时间再把它学完!!
三.学习问题与解答
今天的学习是关于机器学习的,并且给了我们很多很好的参考文章,文章写的很详细,也给出了代码和简单的例子让我们上手。
四.学习思考和总结
本次的机器学习让我学习到了几个基础的简单模型,并且给我们解释了不同模型的优缺点,简单的上手了一下。收获很多!















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









