






 文章详细解释了P值在假设检验中的作用,指出P值低于特定阈值可表明数据存在空间自相关性。Z得分用于判断空间聚集,而莫兰指数则分析空间正/负相关。当P值小于0.1或0.01时,通常认为存在空间关联;Z值大于1.65或小于-1.65表示聚集或离散分布。此外,文章还提到了AnselinLocalMoransI用于聚类和异常值分析。
文章详细解释了P值在假设检验中的作用,指出P值低于特定阈值可表明数据存在空间自相关性。Z得分用于判断空间聚集,而莫兰指数则分析空间正/负相关。当P值小于0.1或0.01时,通常认为存在空间关联;Z值大于1.65或小于-1.65表示聚集或离散分布。此外,文章还提到了AnselinLocalMoransI用于聚类和异常值分析。
仔细看完下面两个链接绝对可以明白。写的非常清晰。
个人理解:P值决定了数据有没有显著性,数据能不能用的问题。z值解决了在空间上是否有聚集的问题。莫兰值解决了再空间上是正/负相关的问题。
他人理解:
p值是假设检验的值。
假设检验的原假设是:研究内容不存在空间自相关性或者说是随机的。
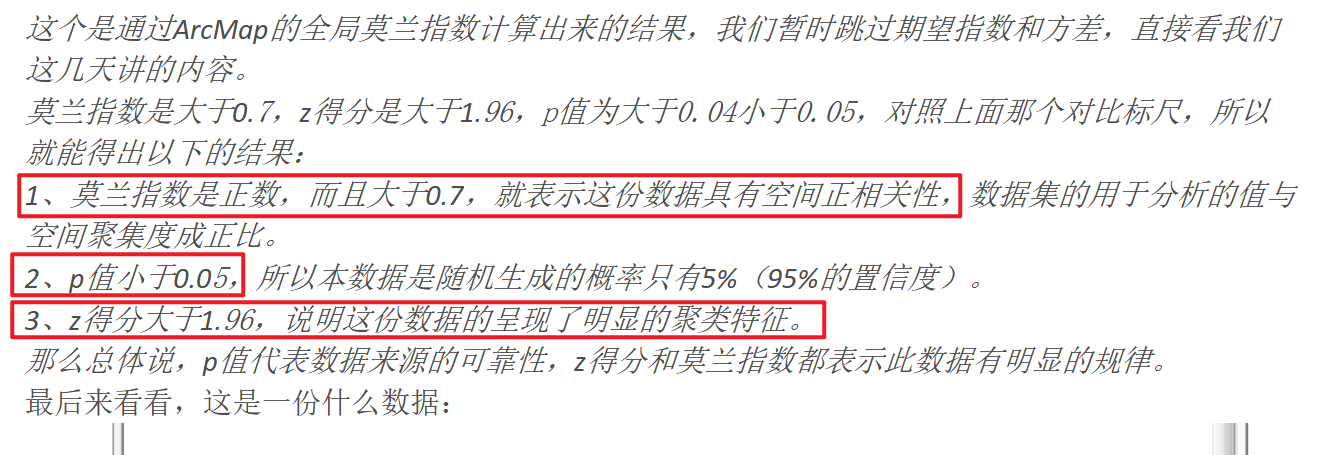
当p<0.1时表示在90%的置信区间上拒绝原假设,当p<0.01时表示在99%的置信区间上拒绝原假设,也就是说,研究内容存在空间自相关性;当p>0.1时,接受原假设,说明研究内容不存在空间自相关性。
z值,z>1.65时呈现聚集分布,z<-1.65时呈现离散分布,z值在-1.65 ~ 1.65之间时,呈现随机分布。(注:这里说的1.65是临界值,只要z值在-1.65 ~ 1.65之间,就可以说明不存在空间自相关性了)
关于moran’s I本身来说,只要p值过了检验,莫兰指数值可以是比较小的,这只能说明具有空间效应。而当moran’s I的值大于0.2或者小于-0.2时,可以说具有明显的空间效应了。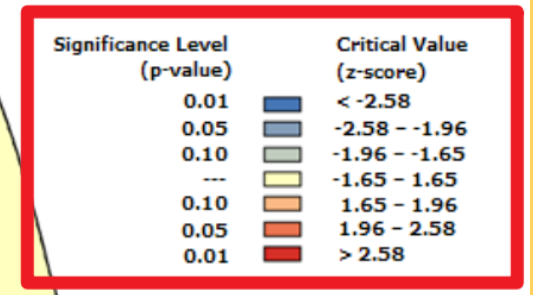

p值(P-Value,Probability,Pr),代表的是概率。它是反映某一事件发生的可能性大小。在空间相关性的分析中,p值表示所观测到的空间模式是由某一随机过程创建而成的概率。
arcgis的空间关系概念化选择应该据实际要求进行选择。
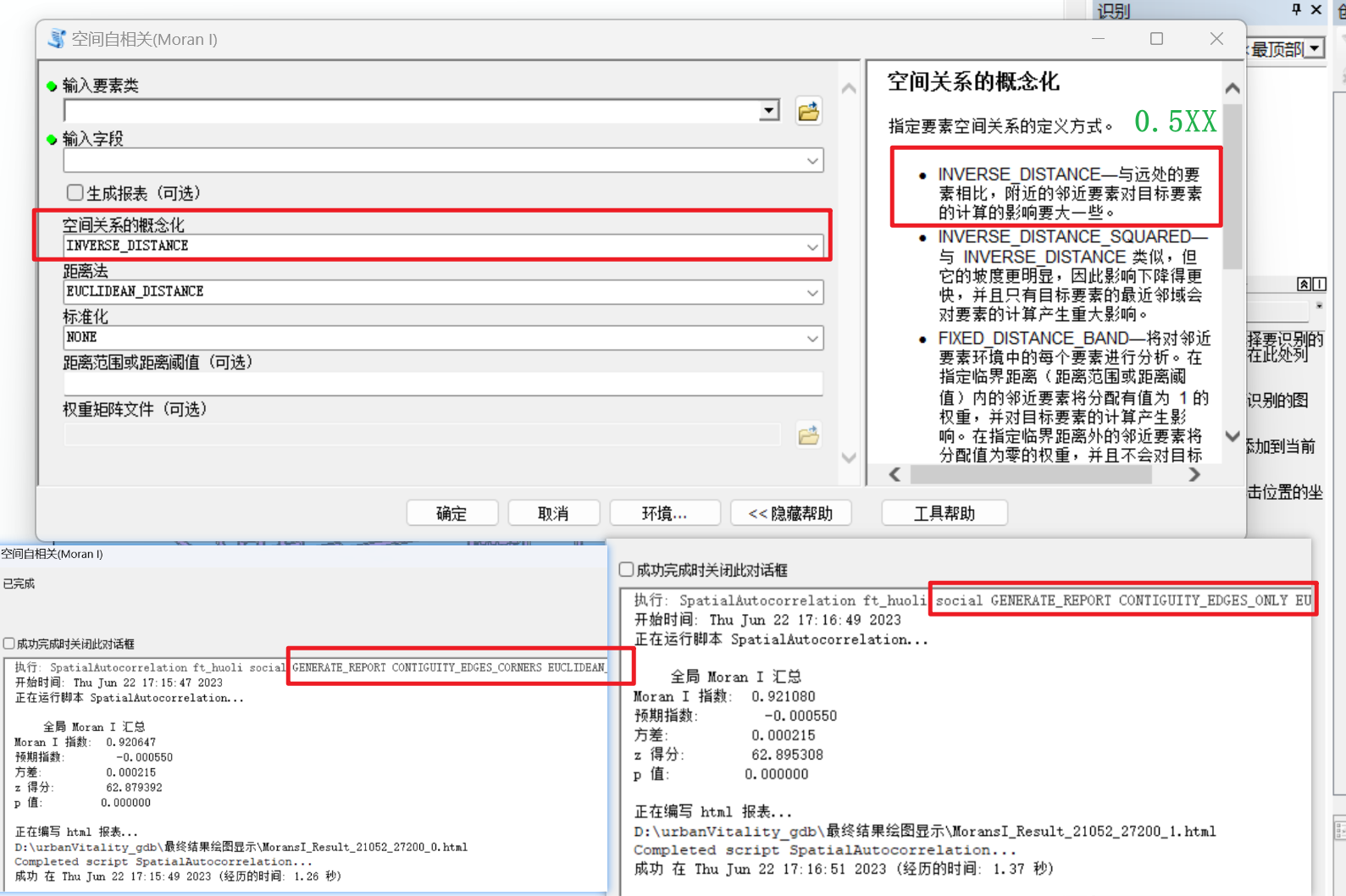
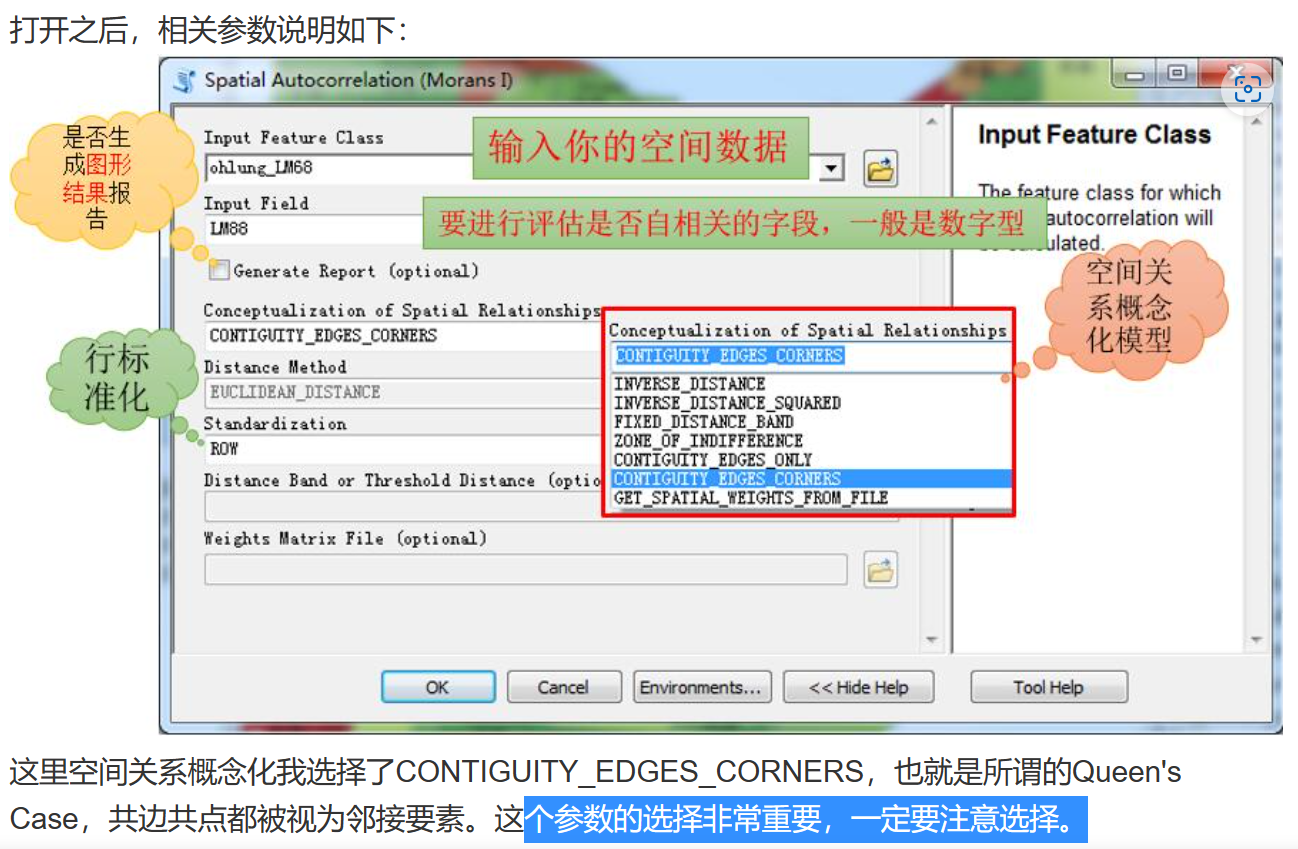
参考虾神的文章。http://t.csdn.cn/kQfi3
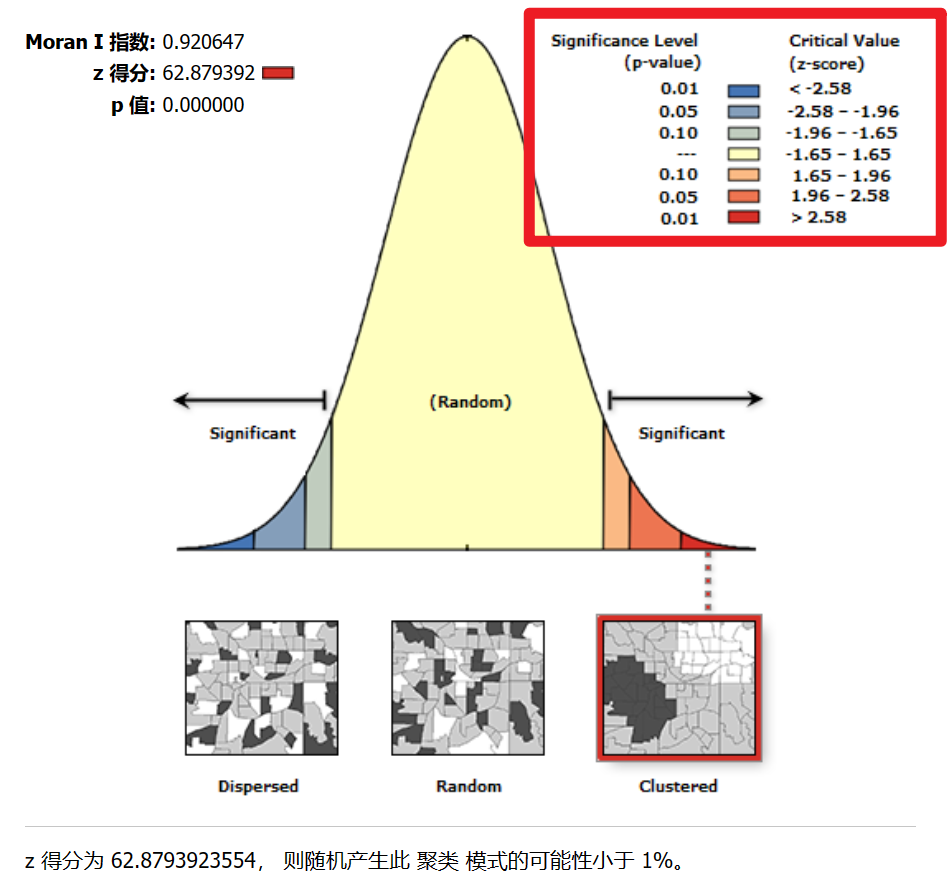
如果你计算出来的p值和z得分,被分布在了两端,就说明你的数据出现随机模式的概率非常低了。

分析的是否有问题???





















 6389
6389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











