



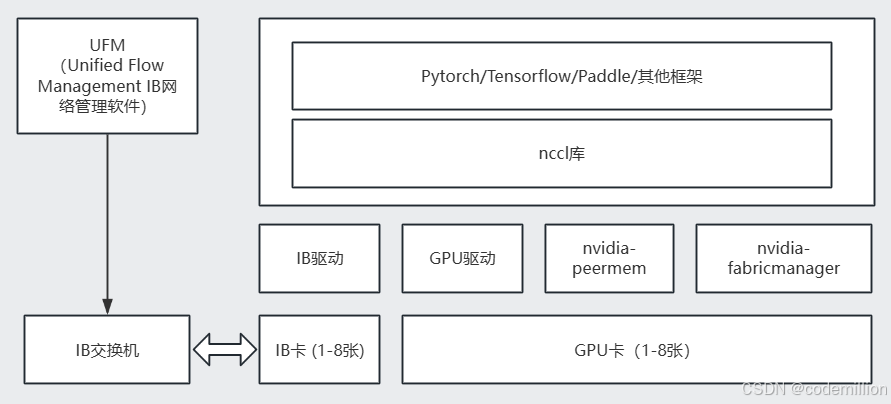
什么是IB:
InfiniBand(直译为“无限带宽”技术,缩写为IB)是一个用于高性能计算的计算机网络通信标准,它具有极高的吞吐量和极低的延迟,用于计算机与计算机之间的数据互连。InfiniBand也用作服务器与存储系统之间的直接或交换互连,以及存储系统之间的互连。
1、IB是一类特殊的网卡,硬件上包括网卡,连接线,交换机都是由nvidia收购的mellanox定制的
2、IB从字面理解就知道是超高带宽的连接技术,属于一种RDMA技术中的一种
3、IB常用在智算场景,用于GPU间夸节点交换数据,可以将数据直接发送到IB卡;也可以作为高速存储的通道
IB硬件
IB卡:

服务器(已满配8张200Gb IB卡为例):
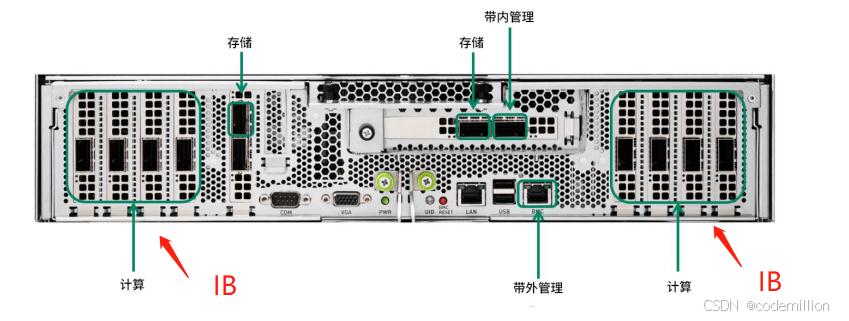
从服务器上查询IB卡信息:

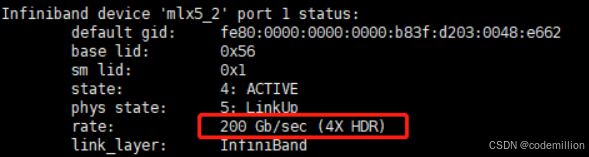
从查询信息上也可以看出IB卡是Mellanox网卡一种,一张IB卡的性能有几种规格100Gb/200Gb/400Gb,本文主要以200Gb规格为例
IB交换机QM8790:

QM8790有40个接口,每个接口可以支持200Gb带宽,交换机整机交换量为16Tb,这里注意一个细节,交换加整机交换量是 40口*200Gb的两倍,完全可以支持每个接口满载还有富余。
IB的组网:
IB组网以SU为单元,一个SU内能最多能接入20台插有8张IB卡的服务器;再以SU为单元进行扩展,最多可以支持140台插有8张IB卡的服务器组网;
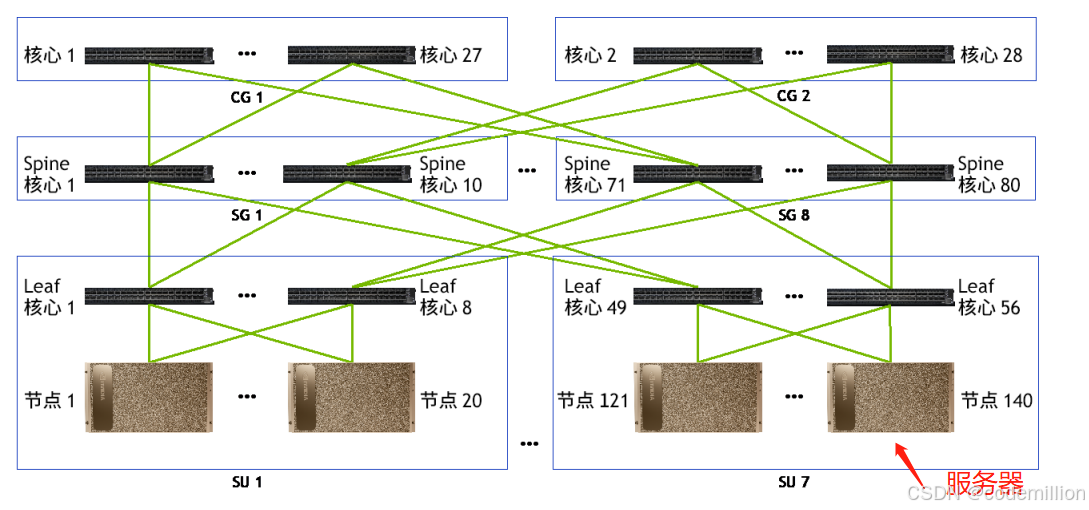
从图中可以看出,一个SU内的一台服务器上的8张IB卡会分别接到8个交换机的下行口。这种接线结构是经过导轨优化后最优的接线方式。从各级交换机的数量*交换带宽,也能看出完全可以满足140台服务器的交换量
IB驱动安装:
IB驱动安装要先于GPU驱动和Cuda安装,否则会影响性能
下载IB驱动,根据自己的系统类型到以下链接选择下载驱动:
可以选择5.8的LTS版本
驱动下载后进行解压,执行解压目录下的安装命令:./mlnxofedinstall --all
安装完重启机器
重启后执行 /etc/init.d/openibd restart
IB驱动安装后在linux系统上除了用ifconfig命令可以看到网卡,也可以用ibdev2netdev命令看到网卡和IB卡名称间的映射关系
最后通过命令检查IB卡状态:ibstat
IB常用命令:
| 命令 | 说明 | 命令格式 |
| ibstat | 端口信息和链路运行状态 | ibstat |
| ibstatu | 跟ibstat类似,信息更精简 | ibstatu |
| ibdev2netdev | 查看网卡和IB卡名映射关系 | ibdev2netdev |
| iblinkinfo | 查看IB网络拓扑信息 | iblinkinfo –C mlx1_0 iblinkinfo –C mlx1_0 -S <SWITCH GUID> |
| ibping | 检测联通新 | ibping -C mlx1_0 -S ibping –C mlx1_0 < server LID> |
| ib_write_bw | 检测联通性,简单测带宽 | b_write_bw -d mlx1_0 -a -F #server端 ib_write_bw -d mlx1_0 -i 1 <ip> -n 1000 -a -F #client端 |
| ibdiagnet | 诊断 | ibdiagnet |
| sharp_hello | 验证sharp功能是否正常 | sharp_hello -d mlx1_0 |
IB性能压测:
IB性能压测建议使用nvidia提供的nccl_test工具
nccl_test可以完成单节点内GPU卡检测测试,如果要连带测试IB性能要使用夸节点测试,依赖mpirun命令,要确保各测试节点都安装了nccl_test 和mpi_run测试命令可以参考一下:
#主节点
export LD_LIBRARY_PATH=/usr/lib:/usr/local/mpi/lib:/nccl-test/build/lib:/usr/local/cuda-11.7
mpirun -np 2 -H ip1,ip2,ip3...... -mca plm_rsh_args '-p 31000' -mca btl_openib_allow_ib true -mca orte_base_help_aggregate 0 -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0,ib0,ib1 /nccl-tests/build/all_reduce_perf -b 128 -e 8G -f 2 -g 6
#ip1,ip2,ip3 代表要加入测试的各节点ip
#-p 31000 代表mpirun协商的端口
#NCCL_DEBUG=INFO 环境变量,打开NCCL调试信息价
#NCCL_SOCKET_IFNAME=eth0,ib0,ib1 nccl_test能用的网卡和IB卡信息
#/nccl-tests/build/all_reduce_perf -b 128 -e 8G -f 2 -g 8 最终执行的测试命令
#-b:从128B包长起步测试
#-e:到8GB包长结束测试
#-f:每次测试包长为上一次值*2
#-g:代表GPU数据这里是8ib_write_bw代码实现:
ib最直接的使用代码可以参考以下链接
GitHub - linux-rdma/perftest: Infiniband Verbs Performance Tests
从代码中可以看出使用了很多rdma的接口,代码这块我们可以再开一篇文章单独介绍
在Pytorch中使用IB卡:
可以用一个简单的Pytorch DDP多机例子验证:
下载工程:https://github.com/tingshua-yts/BetterDL.git
先安装好pytorch工程,也可以考虑直接用镜像透传gpu,测试用例需要两台1卡GPU机器,或者两个带1张GPU卡的容器
docker run --gpus all --rm -it --net host nvcr.io/nvidia/pytorch:21.03-py3 /bin/bash将代码BetterDL拷贝到两台机器或者容器上
cd到目录:BetterDL/test/pytorch/DDP
在机器1上对脚本稍作修改后执行:run_node0_plain.sh
export NCCL_DEBUG=INFO #这个参数帮助打出NCCL信息,能看到是否识别到IB卡
export MASTER_PORT=1234
export MASTER_ADDR=192.168.9.17 #这个IP根据实际情况给出机器1的IP
export WORLD_SIZE=2 #两个实例
export LOCAL_WORLD_SIZE=1 #本机1个实例,占用一张GPU卡
export RANK=0 #本机实例编号,根据多机总实例数进行编号
export LOCAL_RANK=0 #本机内部实例编号
export LOGLEVEL="DEBUG"
python trian_multi_node.py在机器2上对脚本稍作修改后执行:run_node1_plain.sh
export NCCL_DEBUG=INFO
export MASTER_PORT=1234
export MASTER_ADDR=192.168.9.17 #修改为机器1的IP协商用
export WORLD_SIZE=2 #共2个实例
export LOCAL_WORLD_SIZE=1 #本机1个实例
export RANK=1 #本机实例编号,根据多机总实例数进行编号
export LOCAL_RANK=0 #本机第0个实例
export LOGLEVEL="DEBUG"
python trian_multi_node.py程序启动后nccl输出以下日志,代表nccl已识别并使用了IB卡



















 2424
2424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











