







目录
1、了解文件基本概念
1.1、什么是文件?
文件是存放在外部介质 (如硬盘、U盘) 上的一组完整信息的集合。这些信息可为各种文字、
图形、图像、电影、音乐,甚至包括病毒程序等。
1.2、两种重要的文件类型
•
文本文件(Text File)
。文本文件是可直接阅读的,使用记事本打开即可看到文件的内
容。
•
二进制文件(Binary File)
。这类文件将数据按照它的进制编码的形式存储。如BMP。由
于这类文件内容是二进制编码,使用记事本打开是显然是乱码,BMP可用图片查看器解
码。
1.3、文本文件与二进制文件的优缺点
| 文件读取形式 | 优点 | 缺点 |
| 文本 | 输出内容友好,不需要手动转换 |
一个字符占一个字节,文件占用的存储空间
较多,
读写时需要转换(内存->显示)
,
访问的时效率不高
|
| 二进制 |
二进制文件中的数据与数据的内存中的
表现形式一致。二进制文件在存储数据
时非常紧凑,
占用存储空间较少
;在
读
写时不需要进行转换
,具有较高的时间
效率
|
二进制文件
无法直接以字符形式输出
,必须
要经过一个转换过程
|
无论什么类型的文件,在硬盘或者内存中都是以二进制存放
1.3.1、当文本中,中文多的话可以使用gbk存储
在uft-8中,一个中文字符是3到4个字节,一般来说是三个字节。gbk中是两个字节
>>> "中".encode("utf8")
b'\xe4\xb8\xad' 三个字节
>>> "中".encode("GBK")
b'\xd6\xd0' 两个字节;b表示bytes类型,也就是二进制
>>> "中".encode("gbk").decode('gbk')
'中' # 用什么加码就用什么解码 ⭐⭐⭐
python2的编码是ascii码,python3的默认编码是utf81.3.2、如何查看unicode(万国码)?
[root@fttsaxf ~]# python3
>>> ord('中')
20013
>>> ord('国')
22269
1.4、python3中的字符串类型
bytes()和str()
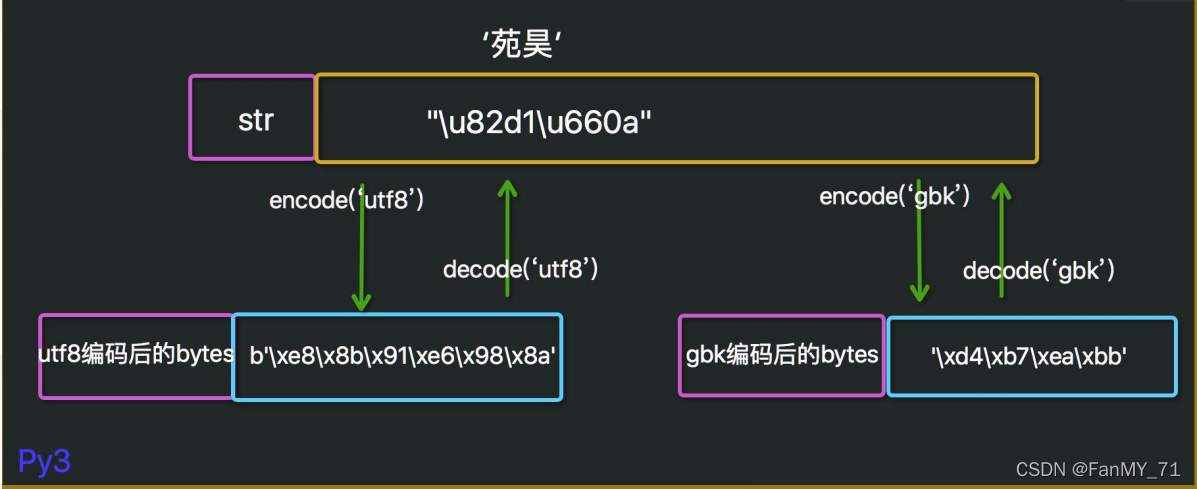
注意:encode编码时可指定任何合适的编码方式,但decode解码时,一定需要对应的编码方式
1.5、文件的缓冲机制
读操作:
不会直接对磁盘进行读取,而是
先打开数据流
,将磁盘上的文件信息
拷贝到缓冲区
内,然后程序再
从缓冲区中读取
所需数据
写操作:
不会马上写入磁盘中,而是
先写入缓冲区
,只有在缓冲区已满或“关闭文件”时,才会将数
据写入磁盘

1.5.1、文件缓冲区
计算机系统为要处理的文件
在内存中单独开辟出来的一个存储区间
,在读写该文件时,做为数据交换的临时“存储中转站”。
1.5.2、缓冲机制的好处
能够有效地减少对外部设备的频繁访问,减少内存与外设间的数据交换,填补内、外设备的速度差异,提高数据读写的
效率
。
2、文件的基本操作
2.1、访问文件操作过程
打开文件、读取文件(将信息读到内存中)、写入文件、关闭文件(保存文件并释放空间)
2.2、打开文件
open(file, mode='r', buffering=-1, encoding=None, erroes=None, newline=None,closedfd=True, opener=None)
file,是要打开的文件名或者路径;mode,是打开的方式;encoding,是文件的编码方式;buffering,是缓存方式;
2.3、encoding
为什么需要编码?
对于计算机来说,所有信息都是由0和1组成的二进制。 人类无法仅用二进制就来完成计算机的各种操作;字符编码解决人与计算机之间的沟通问题。
2.3.1、常见编码

# bash查看文件编码方式
[root@fttsaxf rough_book]# vim utf-8.txt
[root@fttsaxf rough_book]# file utf-8.txt
utf-8.txt: UTF-8 Unicode text
#这是将utf编码文件转化为gbk
[root@fttsaxf rough_book]# iconv -f utf-8 -t gbk utf-8.txt > gbk.txt
[root@fttsaxf rough_book]# ls
find gbk.txt phone phone.patch phone_v2 utf-8.txt
[root@fttsaxf rough_book]# file gbk.txt
gbk.txt: ISO-8859 text
读取这些文件
Python 3.6.8 (default, Nov 16 2020, 16:55:22)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> fp = open("utf-8.txt")
>>> fp.read()
'这是utf-8\n'
>>> fp2 = open("gbk.txt")
>>> fp2.read() # 因为使用了pyhon3默认的编码方式,utf
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib64/python3.6/codecs.py", line 321, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd5 in position 0: invalid continuation byte
>>> fp2 = open("gbk.txt",encoding = "gbk") # 指定编码方式为"gbk"
>>> fp2.read()
'这是gbk.tx\n'
#用python看文件编码方式
>>> fp = open("utf-8.txt","rb")
>>> print(chardet.detect(fp.read()))
{'encoding': 'utf-8', 'confidence': 0.7525, 'language': ''}
>>> fp2 = open("gbk.txt","rb")
>>> print(chardet.detect(fp2.read()))
{'encoding': 'ISO-8859-5', 'confidence': 0.4388398420352105, 'language': 'Russian'}
2.4、打开文件
文件打开类型,是文本类型,还是二进制类型。
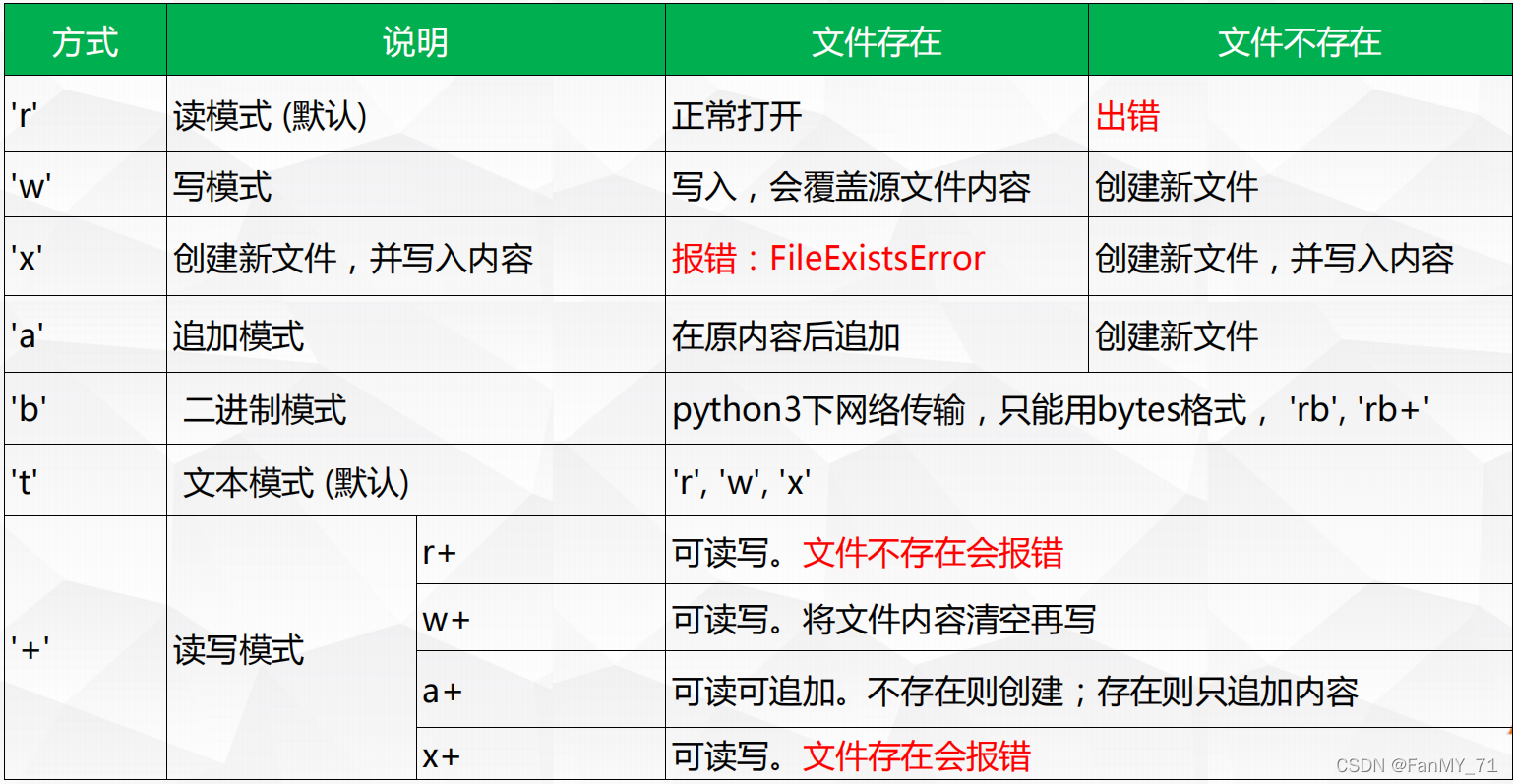
>>> fp = open("utf-8.txt","w")
>>> fp.write("YOU ARE SB!\n")
12 # 这里的是字符
>>> fp.write("你好\n")
32.4.1、with管理语句
with语句体里的内容执行完毕,会自动关闭fp的连接

import random
from collections import Counter
with open("test.txt","a+") as fp:
fp.truncate(0) # 清空文本的内容
i = 0
while i < 100:
i += 1
lucky = random.randint(1,255)
fp.write(f"172.25.254.{lucky}\n")
fp.seek(0)
biglst = fp.readlines()
counter = Counter(biglst)
most_arr = sorted(counter.items(), key=lambda pair: (-pair[1], pair[0]))
print(most_arr[0:10])2.5、读取文件
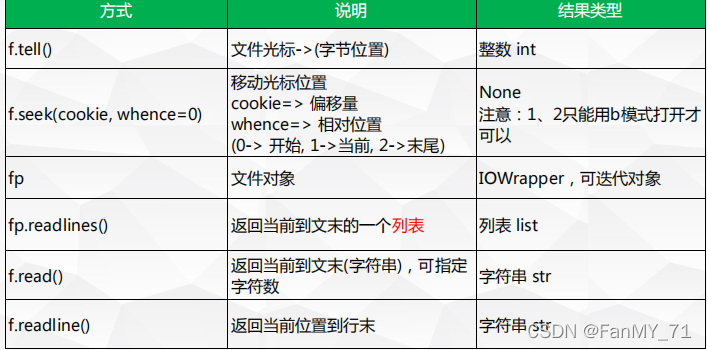
2.5.1、关于读的时候,光标的问题
[root@fttsaxf rough_book]# cat test1.txt # 编码方式为ASCII
abc
abcfdsd
abcfdsagasdd
# 所有的读只会从光标的位置往后才开始读。读过之后的光标是在末尾了,若是再次使用读,就读不到东西了
>>> fp3 = open("test1.txt","r")
>>> fp3.read()
'abc\nabcfdsd\nabcfdsagasdd\n'
>>> fp3.read()
''
#read读的是字符数,如果没有固定读多少个字节,会自动读到最后
>>> fp = open("test2.txt") # 这个编码方式为utf-8
>>> fp.read(8)
'fajagaig'
>>> fp.read(2)
'ow'
>>> fp.read(3)
'g\n中'
>>> fp.read(3)
'文字符'2.5.2、移动光标
# 使用0时
>>> fp.read()
''
>>> fp.seek(0) # 这个是字节位置
0
>>> fp.read()
'fajagaigowg\n'
# 使用1和2的时
# 移动光标位置 cookie=> 偏移量 whence=> 相对位置 (0-> 开始, 1->当前, 2->末尾)
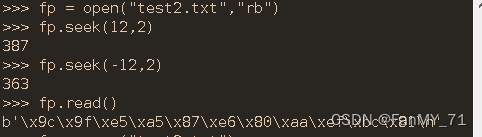
>>> fp = open("test2.txt","rb")
>>> fp.seek(-2,2)
17
>>> fp.read()
b'\xa6\n'
>>> fp.seek(-13,2)
6
>>> fp.read()
b'\xe4\xb8\xad\xe6\x96\x87\xe5\xad\x97\xe7\xac\xa6\n'
>>> fp.seek(-13,2)
6
>>> fp.read().decode("utf8")
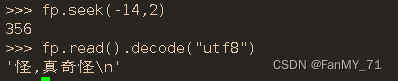
'中文字符\n' # 这个为13个字节2.5.3、readline()
#readline() 每一次都读一行
>>> fp.seek(0)
0
>>> fp.readline()
'fajagaigowg\n'
>>> fp.readline()
'中文字符\n'
>>> fp.seek(0)
0
>>> fp.read(3)
'faj'
>>> fp.readline()
'agaigowg\n'2.5.4、readlines()
大文件推荐使用readlines(n)来读取,如果用read()可能会造成一个单词缺失一半
#readlines()全部读完,每一行作为一个元素,存入列表里边去
>>> fp.seek(0)
0
>>> fp.readlines()
['fajagaigowg\n', '中文字符\n']
#3若是加入参数,光标所在字节在哪一行,把那一行的字节全部读出来
>>> fp.readlines(6)
['fajag\n', '中文字符\n']
>>> fp.seek(0)
0
>>> fp.readlines(5)
['fajag\n']
>>> fp.seek(0)
0
>>> fp.readlines(7)
['fajag\n', '中文字符\n']2.5.5、 读取文件命令总结
# fp.read() 从光标位置读到文件末尾
# fp.readline() 从光标位置读到行末
# fp.readlines() 从光标位置读到文件末尾,每一行作为一个元素放到列表里返回
# fp.seek() 移动光标的位置2.6、写操作
f.write('hello')
2.6.1、为什么不实时写入磁盘
硬盘是
慢设备
,频率读写会增大磁盘压力,
产生瓶颈
2.6.2、什么时候会写入磁盘
1、缓存区满的时候;2、进程关闭;3、强制刷新(f.fush());4、文件关闭(f.close())
# 注意 这里是在两个bash进程之间切换使用
>>> fp = open("utf-8.txt","w")
>>> fp.write("YOU ARE SB!\n")
12
>>> fp.write("你好\n")
3
# 然后我们在这边并不能够打开
[root@fttsaxf rough_book]# cat utf-8.txt
[root@fttsaxf rough_book]#
# 因为写入后,这些数据还在缓存里边。程序退出的时候,缓存的数据会放入进磁盘里;或者说缓存区满了,也会自动放进磁盘。
>>> fp.flush() # 强制刷新到磁盘上
[root@fttsaxf rough_book]# cat utf-8.txt
YOU ARE SB!
你好
# 有读缓存也有写缓存
redis是缓存。没有什么是加入中间层是解决不了的⭐⭐⭐,而这个redis就是这个中间层。



>>> fp = open("test3.txt","ab",buffering=0)
>>> fp.write(b'a')
1
#output:
"""
[root@fttsaxf rough_book]# cat test3.txt
#sf
gaj
#jhhh
ghhhhh
"""
>>> fp.write(b'\n') # 要使用"\n"换行符之后,才会写入到磁盘中
1
#output
"""
[root@fttsaxf rough_book]# cat test3.txt
#sf
gaj
#jhhh
ghhhhh
a
"""
>>> fp.write(b'xxxx')
4
>>> fp.write(b'pppppp\n')
7
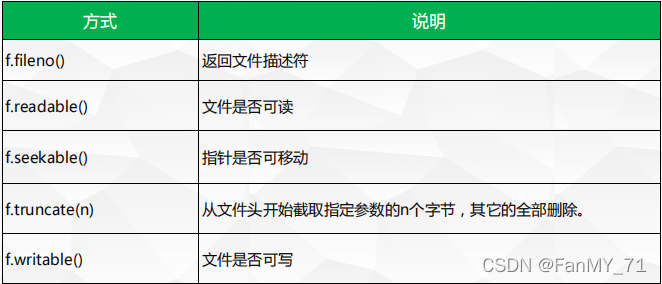
2.7、文件对象其他方法















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











