







前置环节介绍:
node1:hadoop NN DN RM NM ,hive
node2:hadoop SNN DN NM
node3:hadoop DN NM
Local模式
local模式基本原理
本质:启动一个JVM Process进程(一个进程里面有多个线程),执行任务Task、
Local模式可以限制模拟Spark集群环境的线程数量,即local[a]或local[*]
其中N代表可以使用N个线程,每个线程拥有一个cpu core。如果不指定N。则默认一个线程(该线程有一个core),通常CPU有几个core,就指定几个线程,最大化利用计算能力。
例如:local[1],表示只有一个服务器的Spark集群,local[10],表示10个线程模拟Spark环境,就和有10台服务器组成集群一样。
如果是local[*],则代表按照CPU最多的核心数设置线程数。
Local下的角色分布
资源管理:
Master:Local进程本身
Worker: Local进程本身
任务执行:
Driver:Local进程本身
Executor:不存在,没有独立的Executor角色,由Local进程(也就是Driver)内的线程提供计算能力
注意:Local模式只能运行一个Spark程序,如果执行多个Spark程序,那就是由多个相互独立的Local进程在执行
搭建
Anaconda,中文大蟒蛇,是一个开源的Anaconda是专注于数据分析的Python发行版本,包含了conda、Python等190多个科学包及其依赖项。
Anaconda就是可以便捷获取包且对包能够进行管理,包括了python和很多常见的软件库和一个包管理器conda。常见的科学计算类的库都包含在里面了,使得安装比常规python安装要容易,同时对环境可以统一管理的发行版本
为什么在Anaconda环境中运行python?
(1)Anaconda附带了一大批常用数据科学包,它附带了conda、Python和150多个科学包及其依赖项。因此你可以立即开始处理数据。
(2)Anaconda是在conda(一个包管理器和环境管理器)上发展出来的。在数据分析中,你会用到很多第三方的包,而conda(包管理器)可以很好的帮助你在计算机上安装和管理这些包,包括安装、卸载和更新包。
(3)管理环境为什么需要管理环境呢?比如你在A项目中用了Python2,而新的项目B老大要求使用Python 3,而同时安装两个Python版本可能会造成许多混乱和错误。这时候conda就可以帮助你为不同的项目建立不同的运行环境。还有很多项目使用的包版本不同,比如不同的pandas版本,不可能同时安装两个 Numpy 版本,你要做的应该是,为每个 Numpy 版本创建一个环境,然后项目的对应环境中工作,这时候conda就可以帮你做到。
Anaconda On Linux 安装 (单台服务器)
上传安装包:
上传: Anaconda3-2021.05-Linux-x86_64.sh文件到Linux服务器上
安装:
sh ./Anaconda3-2021.05-Linux-x86_64.sh





输入yes后就安装完成了.
安装完成之后退出终端,重新进入

看到这个Base开头表明安装好了.
base是默认的虚拟环境.
更改Anaconda的国内源
vim ~/.conarc
这个文件不存在,创建即可,将以下内容输入保存。这儿才理解,Anaconda类似于yum一样的东西,可以在上面下载很多相关包
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
全部配置完之后我们可以直接使用python了,基于Anaconda的python

配置虚拟环境,供后续使用
conda create -n pyspark python=3.8
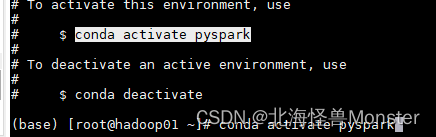
配置成功,使用conda activate pyspark可以切换到pyspark上
单机安装Spark
下载地址:https://dlcdn.apache.org/spark/spark-3.2.0/spark-3.2.0-bin-hadoop3.2.tgz
解压文件:
tar -zxvf spark-3.2.0-bin-hadoop3.2.tgz
配置Spark由如下5个环境变量需要设置
- SPARK_HOME: 表示Spark安装路径在哪里
- PYSPARK_PYTHON: 表示Spark想运行Python程序, 那么去哪里找python执行器
- JAVA_HOME: 告知Spark Java在哪里
- HADOOP_CONF_DIR: 告知Spark Hadoop的配置文件在哪里
- HADOOP_HOME: 告知Spark Hadoop安装在哪里
这5个环境变量 都需要配置在: /etc/profile中
之前我已经配置过java,hadoop,这次就只配置了下面三个
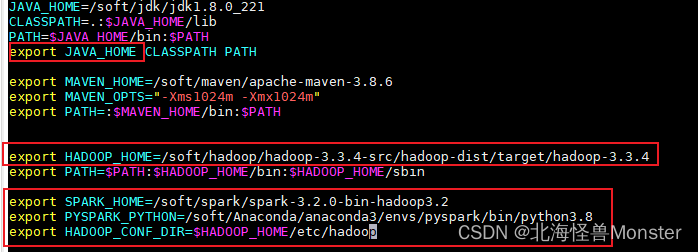
PYSPARK_PYTHON和 JAVA_HOME 需要同样配置在: /root/.bashrc中

启动Local测试
单机spark 目录解释:
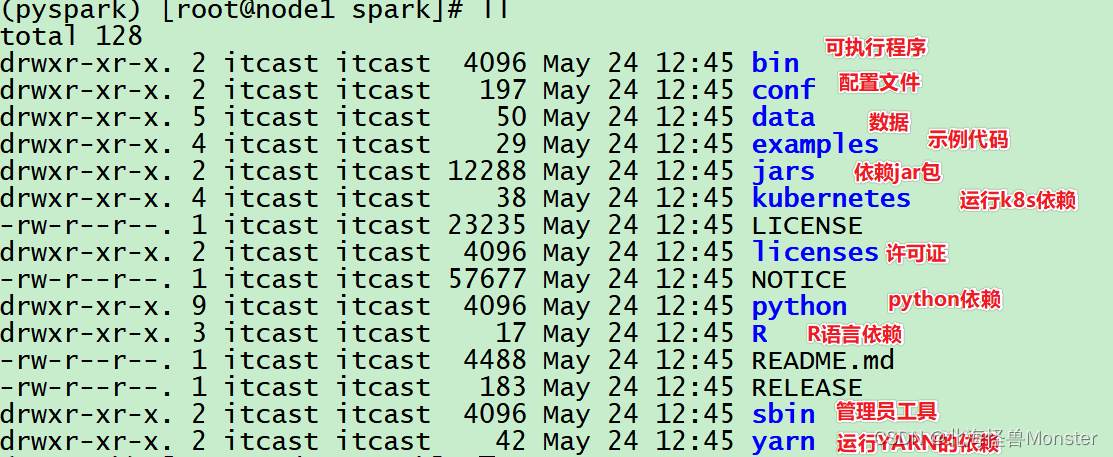
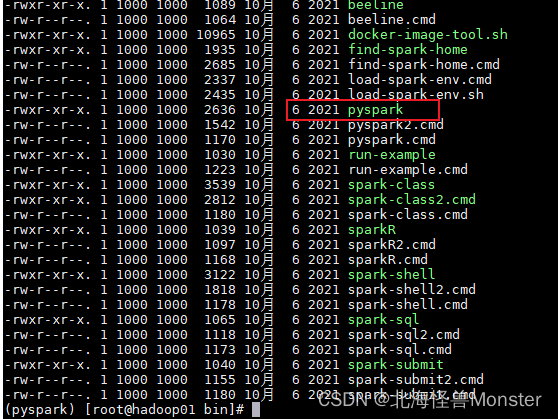
切换到bin目录:
pyspark 这个是提供的一个交互式解释器程序,可以在里面写python代码,让spark执行。
spark-shell :使用scala代码执行解释器环境
sparkR:使用R语言执行解释器环境
可以在启动的时候指定参数
pyspark --master local[*]
spark-submit 可以帮我们提交已经写好的代码到集群中运行。不会进入解释器环境,结果出现在日志中。
spark-submit /data/pi.py
单机安装成功:
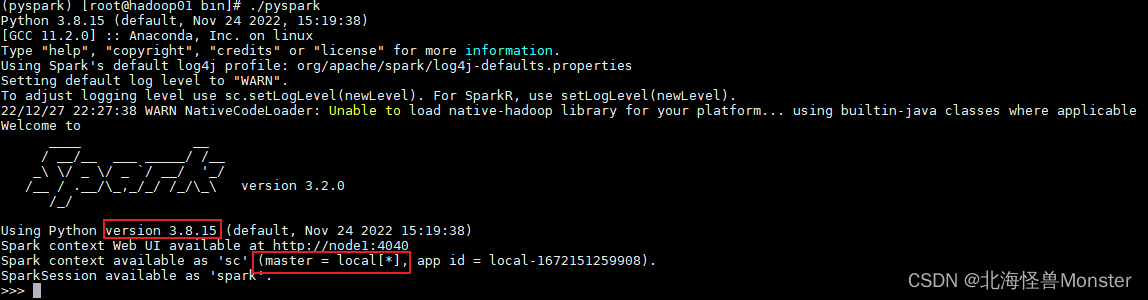
在这个环境内, 可以运行spark代码

图中的: parallelize 和 map 都是spark提供的API
sc.parallelize([1,2,3,4,5]).map(lambda x: x + 1).collect()
在红框标记的master上方有一个网址: http://node1:4040
当前模式运行的监控页面,Spark程序在运行的时候, 会绑定到机器的4040端口上.
如果4040端口被占用, 会顺延到4041 … 4042…
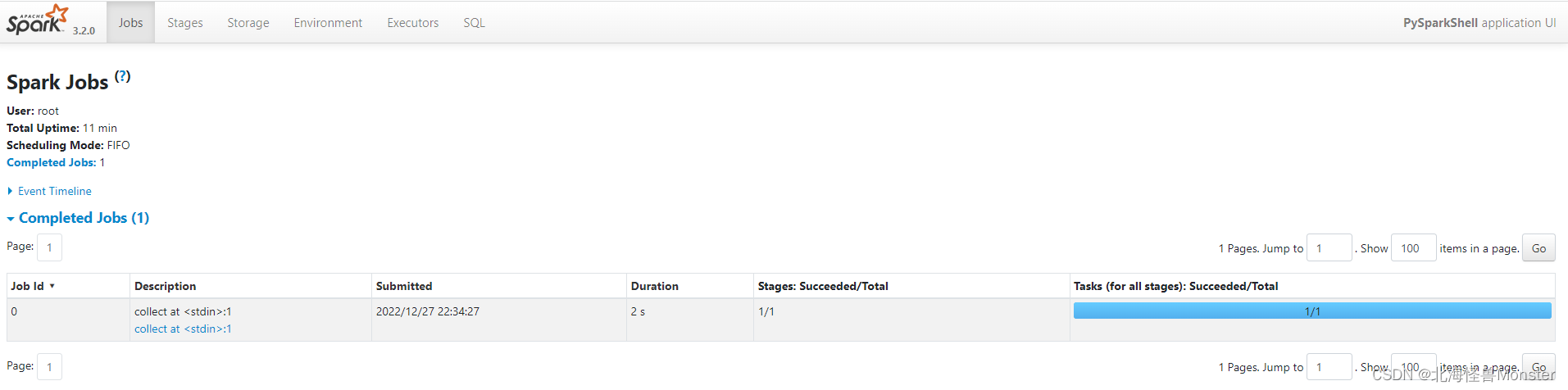
我这个虚拟机很拉,学习使用只分配了一核。














 1486
1486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









