







目录
摘要
FQIA方法既要关注到每张人脸的固有特性和可识别性
For this purpose, the FIQA method should consider both the in trinsic property and the recognizability of the face image
先前的工作是将嵌入不确定性的样本或组合间的相似程度作为质量分数,这些都只考虑了类内的部分信息。
因此本文的核心思想是一张高质量的人脸图像应该是与类内图像相似,而不相似于类间图像。

本文提出了一种人脸质量评估的相似性分布距离的无监督FIQA方法。
我们的方法通过计算类内和类间的Wasserstein距离生成质量伪标签。有了这些质量伪标签,我们能够训练回归网络进行质量预测
介绍
人脸识别在受限制的条件下可以达到很好的表现
但是在现实生活中的很多工作场景下是不受限制的(比如监控摄像头和户外镜像),所以精度和稳定性不是很好。性能受到了不可预测的环境因素的影响,比如姿势,光照,遮盖程度等。
but sometimes the performance is still affected by the unpredictable environmental factors including pose, illumination, occlusion, and so on.
因此人脸图像质量评价已应用于识别系统,为了提高识别系统的表现。
Face Image Quality Assessment (FIQA) has been developed to support the recognition system to pick out high-quality images or drop low-quality ones for stable recognition performance. [ 7 , 1 ].
现存的FIQA方法大致被分为两类
- 以分析为基础的 analytics-based:质量向量 是人类视觉系统,用于质量评价的特征是手动选择的。例如面部区域的不对称、光照强度和垂直边缘密度。
这种方法的缺点是对不同的quality degradations需要手动提取特征
Analytics-based FIQA defifines quality metrics by Human Visual System (HVS) and evaluates face image quality with handcrafted features
- 以学习为基础的 learning-based :直接从识别模型中生成质量分数,这类方法的核心是建立从图像质量到识别系统的映射函数。
The most critical part of these approaches is to establish the mapping function between image quality and recognition model此类方法的例子有:
Aggarwal等人提出了多维方法将特征空间映射到质量分数。
Hernandez等人将类内识别嵌入的欧氏距离作为质量分数
Shi等人将类识别嵌入的变化作为质量分数
Xie等人提出用PCNnet来计算质量分数,通过不断的最小化positive mated-pairs
这种方法的缺点是他们只考虑了识别模型中的部分类内相似性或特征不确定性,而忽略了类间相似性的重要信息(这是人脸图像可识别性的关键因素)
SDD-FIQA方法过程:
- 我们首先揭示识别性能与人脸图像之间的内在关系。具体来说,对于目标样本,我们使用了一种识别模型来收集其类内相似性分布(Pos-Sim)和类间相似性分布。
- 然后计算两个分布间的Wasserstein距离(WD)作为质量伪标签。
- 最后,根据Huber loss训练回归网络。我们的方法可以准确地以无标签的方式预测人脸图像质量分数。
SDD-FIQA的主要思想如图1所示

SDD-FIQA的贡献
- 第一个考虑到类内和类间识别相似性分布。
- 提出了一种新的无标签的,紧密关注识别性能的人脸图像估计框架质量。
- 第一个通过使用不同的识别模型进行评估FIQA方法的人,这更符合实际应用。
- 就基准数据集的准确性和通用性而言,SDD-FIQA优于现有技术水平。
相关工作
analytics-based FIQA
介绍了前辈做的analytics-based的FIQA方法的核心及其缺点,缺点有:只能考虑某个或某几个影响因素;基于人手动打出的质量标签,费时费力难以应用。
Learning-based FIQA
介绍了前辈做的learing-based的FIQA方法的核心及其缺点,缺点是:从未发现类内和类间相似性之间的关系
质量伪标签生成的数学过程
X,Y,F分别表示图片集、id标签集、识别特征集,构建一个三元组数据集。

质量分数的生成

FMR的门限值需要根据 (表示某个具有σ百分比的最高质量面样本的id集)来调整。
图像的质量与FNMR的梯度有关。梯度下降的越快,图片的质量越差
According to the EVRC metric, we find that the image quality can be described by the gradient of the FNMR decrement.the more sharply FNMR decreases, the lower quality of x i has.
进而提出用FNMR的差距来作为xi样本的伪标签。

可认为FNMR是【0,1】的均匀随机变量,那Q可以看成

代入(1)(2)得

由于每个样本xi都是独立于和
,所以式子(5)又可以表示成

F (·)表示三者的映射关系
基于此提出利用Wasserstein距离来测量SDD代替

且最后的得分在【0,100】间,因此最终的公式是

提高分数伪标签生成速度
如果成对的考虑整个数据集,那打标签的过程需要O(n2)的时间复杂度
因此随机选择m个正样本对和m个负样本对(m远远小于n),计算k次,取平均值
该样本的质量伪标签:
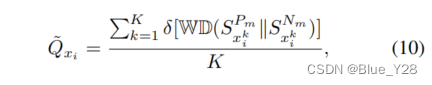
该方法的时间复杂度O(2m * K* n)=O(n)
质量回归网络
有了质量分数,就可以单独训练FIQA模型,不再依赖于识别系统输出的分数
首次在人脸识别模型中移除了嵌入层和分类层,加入了0.5可能性的dropout层来防止过拟合,增加了全连接层来输出结果。
最终采用huber losdd来训练网络
Specififically, we fifirst remove the embedding and classifification layers from a pre-trained face recognition model. Then we employ a dropout operator with 0.5 probability to avoid overfifitting during training, and add a fully connected layer in order to output the quality score for FIQA.Finally, we use the Huber loss function to train the quality regression network
实验
准备工作
数据集:识别模型和质量回归模型的训练集是 MS-Celeb-1M (MS1M)
但是作者使用的数据集有86G,建议使用其余数据集,比如作者在文中提到的LFW [11],Adience [6], UTKFace [32], and IJB-C [16](难度最大)。
不管使用哪个数据集,笔者发现一定要满足每个人都包含两张以上的图像,模型才可以跑起来。
其次,需要调整batch-size的大小,否则会出现cuda out of memory。因为模型有点大。
总结
是首个将质量评价作为识别性能评价的一部分。
其次提出了考虑类内和类间相似度,并将两者的Wasserstein metric作为质量分数
最后 降低了时间复杂度
First, we are the first to consider the FIQA as a recognizability estimation
problem. Second, we propose a new framework to map
the intra-class and inter-class similarity to quality pseudo-labels via the Wasserstein metric, which is closely related to the recognition performance. Third, an efficient implementation of SDD is developed to speed up the label generation and reduce the time complexity from O(n2) to O(n).
Compared with existing FIQA methods, the proposed SDD-FIQA shows better accuracy and generalization















 4797
4797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









