







原文地址:https://arxiv.org/pdf/1611.07004.pdf
代码地址:https://github.com/phillipi/pix2pix.
目录
摘要
现状:肯定了条件gan的适用范围广泛(图像到图像的生成),但是需要学习输入到输出的映射和调整损失函数。
These networks not only learn the mapping from input image to output image, but also learn a loss func tion to train this mapping
现在:p2p网络的提出,使得应用范围更广泛,更少的参数调整。不需要学习输入到输出的映射,不用手动设计损失函数,模型可以学习一个损失函数。
we no longer hand-engineer our mapping functions, and this work suggests we can achieve reasonable results without hand-engineering our loss functions either.
1.introduction介绍
解释了什么是image to image;
原始的解决方法是逐个像素预测
predict pixels from pixels
本文的目标是找到一个更泛化的框架解决这一类问题
Our goal in this paper is to develop a common framework for all these problems.
选用cnn作为基本网和欧氏距离为为损失函数(但欧式距离会造成生成图像的模糊)
本文的贡献:
- 认为在大部分问题上,cgan的效果比gan更好
- 证明简单的网络也能产生好的结果,并在一些重要的问题上得到验证
Our primary contribution is to demonstrate that on a wide variety of problems, conditionalGANs produce reasonable results.Our second contribution is to present a simple framework suffificient to achieve good results, and to analyze the effects of several important architectural choices.
2.related work相关工作
cgan的损失函数是学习得到的,在输出和目标有误差时会作出惩罚
The conditional GAN is different in that the loss is learned, and can, in theory, penalize any possible structure that differs between output and target
前期的论文都是为了解决某个特定的问题,用了gan;而本文的目的是想要提出一个能更泛化的结构;且网络的生成器采用unet,判别器采patchgan
Our framework differs in that nothing is application specifific.Our method also differs from the prior works in several architectural choices for the generator and discriminator.
3.method方法
3.1目标函数
输入图像x,随机噪声向量z,生成图像y,目标函数如下
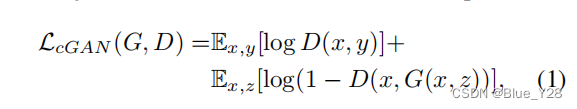
损失函数:L1
正则化:dropout
3.2网络结构
生成器和判别器都采用卷积-正则化-relu的结构,细节在下文展示。
Both generator and discriminator use modules of the form convolution-BatchNorm-ReLu
3.2.1生成器
由于输入与输出在底层结构上有关,虽然此前有提出“encoder-decoder”的结构,但是没有保留低级信息,所以提出了skip connections。
In addition, for the problems we consider, the input and output differ in surface appearance, but both are renderings of the same underlying structure. Therefore, structure in the input is roughly aligned with structure in the output. We design the generator architecture around these considerations.
To give the generator a means to circumvent the bottleneck for information like this, we add skip connections, following the general shape of a “U-Net” .
3.2.2判别器
L1损失函数关注低频信息(低频信息关注的是整体),判别器应该更关注高频信息(高频信息关注的细节),所以应该将注意力限制在图像的局部,提出了patch-gan
patch-gan的结果是输出一个矩阵,该矩阵中的每个像素对应输入图像的N*N,像素值是对这块内容的真实性的判断。
This motivates restricting the GAN discriminator to only model high-frequency structure, relying on an L1 term to force low-frequency correctness . In order to model high-frequencies, it is suffificient to restrict our attention to the structure in local image patches. Therefore, we design a discriminator architecture – which we term a Patch GAN – that only penalizes structure at the scale of patches. This discriminator tries to classify if each N × N patch in an image is real or fake. We run this discriminator convolutionally across the image, averaging all responses to provide the ultimate output of D .
3.3优化函数
采用SGD和Adam,实验中采用的batch size是在1-10之间
We use minibatch SGD and apply the Adam solver , with a learning rate of 0 . 0002 ,and momentum parameters β 1 = 0 . 5 , β 2 = 0 . 999 .
4.实验
在不同的问题和数据集上进行实验,实验结果在论文中显示,不做摘录
4.1评价方式
- 采用 “real vs. fake”的感知判定
- 用现成的系统来判别生成的景观图像是否真实,能否检测出景观图像中的目标。
Second, we measure whether or not our synthesized cityscapes are realistic enough that off-the-shelf recognition system can recognize the objects in them.
4.2目标函数分析
4.3生成器结构分析
4.4判别器分析
4.5感知评估
4.6语义分割
4.7社区驱动实验
5.结论
证明了cgan在image to image问题上是有前景的,尤其是高度图形化结构的图像。
因为可以根据数据自主习得损失,使得他们有更广泛的应用
The results in this paper suggest that conditional adversarial networks are a promising approach for many image to-image translation tasks, especially those involving highlystructured graphical outputs. These networks learn a loss adapted to the task and data at hand, which makes them applicable in a wide variety of settings.















 844
844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









