






【AI大模型开发者指南】ruozhiba数据集构建——xtuner实战
Step 1. 准备原始数据集
可以从opendatalab直接下载
https://opendatalab.org.cn/OpenDataLab/COIG-CQIA/tree/main/ruozhiba
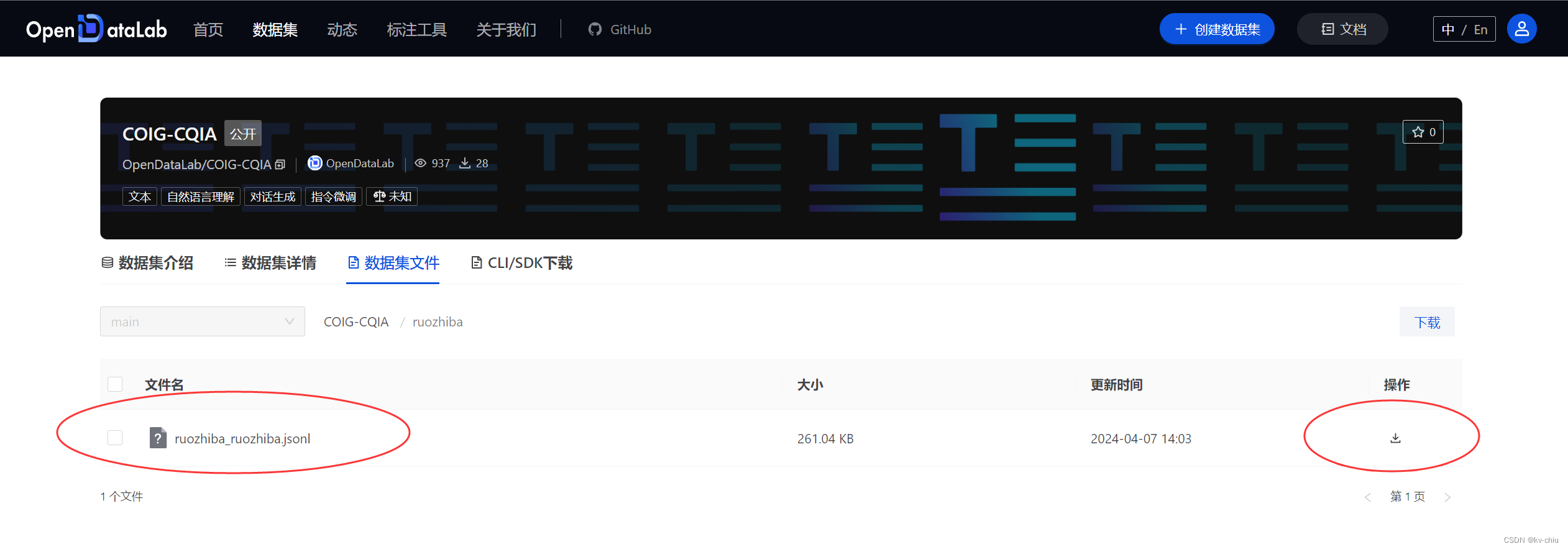
下载完成后,传输到服务器中(开发环境中)
Step 2. 准备训练用的数据集(xtuner格式)
原始格式
{
"instruction": "天下没有不散的筵席,那么我们相聚的意义又是什么",
"input": "",
"output": "尽管我们相聚的时光有限,但是相聚的意义在于创造美好的回忆和珍贵的关系。相聚让我们感受到彼此的关怀、支持和友情。我们可以一起分享喜悦、快乐和困难,互相支持和激励。相聚也可以是一个机会,让我们相互了解、学习和成长。最重要的是,相聚能够带给我们真实的人际交往和情感交流,让我们感受到生活的丰富和美好。所以,即使相聚的时间有限,我们仍然要珍惜这份意义和与彼此相聚的时光。",
"task_type": {
"major": [
"问答"
],
"minor": [
"逻辑问答",
"隐喻理解"
]
},
"domain": [
"通用"
],
"metadata": "暂无元数据信息",
"answer_from": "llm",
"human_verified": true,
"copyright": "暂无版权及作者信息"
}
xtuner格式
{
"messages": [
{
"role": "user",
"content": ""
},
{
"role": "assistant",
"content": ""
}
]
}
只需要把instruction变成user-content,output变成assistant-content即可
处理脚本非常简单,gpt就能实现
格式转换完成后,还需要划分数据集,生成test.jsonl和train.jsonl两个文件(这一步同样可以使用gpt生成脚本
Step 3. 构建工作环境
项目文件夹结构
workspace/
- model/
- config/
- train/
- huggingface/
- final_model/
- data/
- train.jsonl
- test.jsonl
其中model目录下是internlm2-chat-1_8b/*所有内容,config目录下存放我们微调所使用的配置文件,train是xtuner训练的工作空间,huggingface是模型训练完成后生成adapter的地方
一切完成后准备开始训练
Step 4. 修改配置文件
xtuner copy-cfg internlm2_1_8b_qlora_alpaca_e3 ./config/
从xtuner获取配置模板
修改关键参数
- 模型地址 pretrained_model_name_or_path
- 数据集地址 alpaca_en_path
- 评估问题 evaluation_inputs
- dataset_map_fn
- dataset
模型地址和数据集地址的修改为工作环境中的地址(如果是相对路径,需要以启动命令所在目录为根目录,假设在workspace中启动命令,则是./model和./data/train.jsonl)
预设评估问题是
[‘请给我介绍五个上海的景点’, ‘Please tell me five scenic spots in Shanghai’]
不符合本次微调场景,可以改成
[‘为什么我爸妈结婚的时候没邀请我参加婚礼’]
map_fn用于数据规范化,把数据集处理成规范格式,例如Alpaca、OpenAssistant 等等热门数据集的规范化映射函数
在alpaca_en中
我们要把默认的alpaca_map_fn改成openai_map_fn(from xtuner.dataset.map_fns import openai_map_fn)
dataset修改如下
dataset=dict(type=load_dataset, path='json', data_files=dict(train=alpaca_en_path))
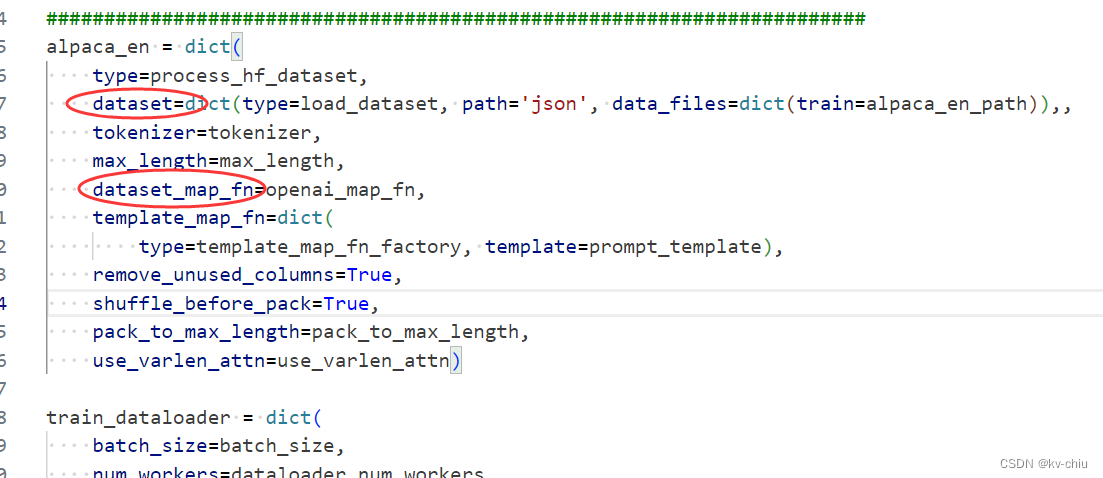
Step 5. 启动训练
xtuner train ./config/internlm2_1_8b_qlora_ruozhiba_e3.py --work-dir ./train --deepspeed deepspeed_zero2
记得修改配置文件名称,模型名_比特_微调方式_数据集_epoch数,在本次任务中是internlm2_1_8b_qlora_ruozhiba_e3.py
也就是
- 模型名:internlm2
- 比特:1.8b
- 微调方式:qlora
- 数据集:ruozhiba
- epoch数:3(e3)
训练完成后,结果可能是

Step 6. 生成adapter
之前构建工作环境时,创建了huggingface文件夹
接下来要把模型变成HuggingFace adapter,以便最终和模型合并,实现qlora
xtuner convert pth_to_hf ./train/internlm2_1_8b_qlora_ruozhiba_e3.py ./train/iter_96.pth ./huggingface
Step 7. 合并模型
adapter生成后,我们需要合并回原模型
# 如果不设置这个,可能会出现线程冲突的bug(实测不设置未遇到bug)
export MKL_SERVICE_FORCE_INTEL=1
# 进行模型整合
xtuner convert merge ./model ./huggingface ./final_model
模型整合完成后
xtuner chat ./final_model --prompt-template internlm2_chat
即可进行对话
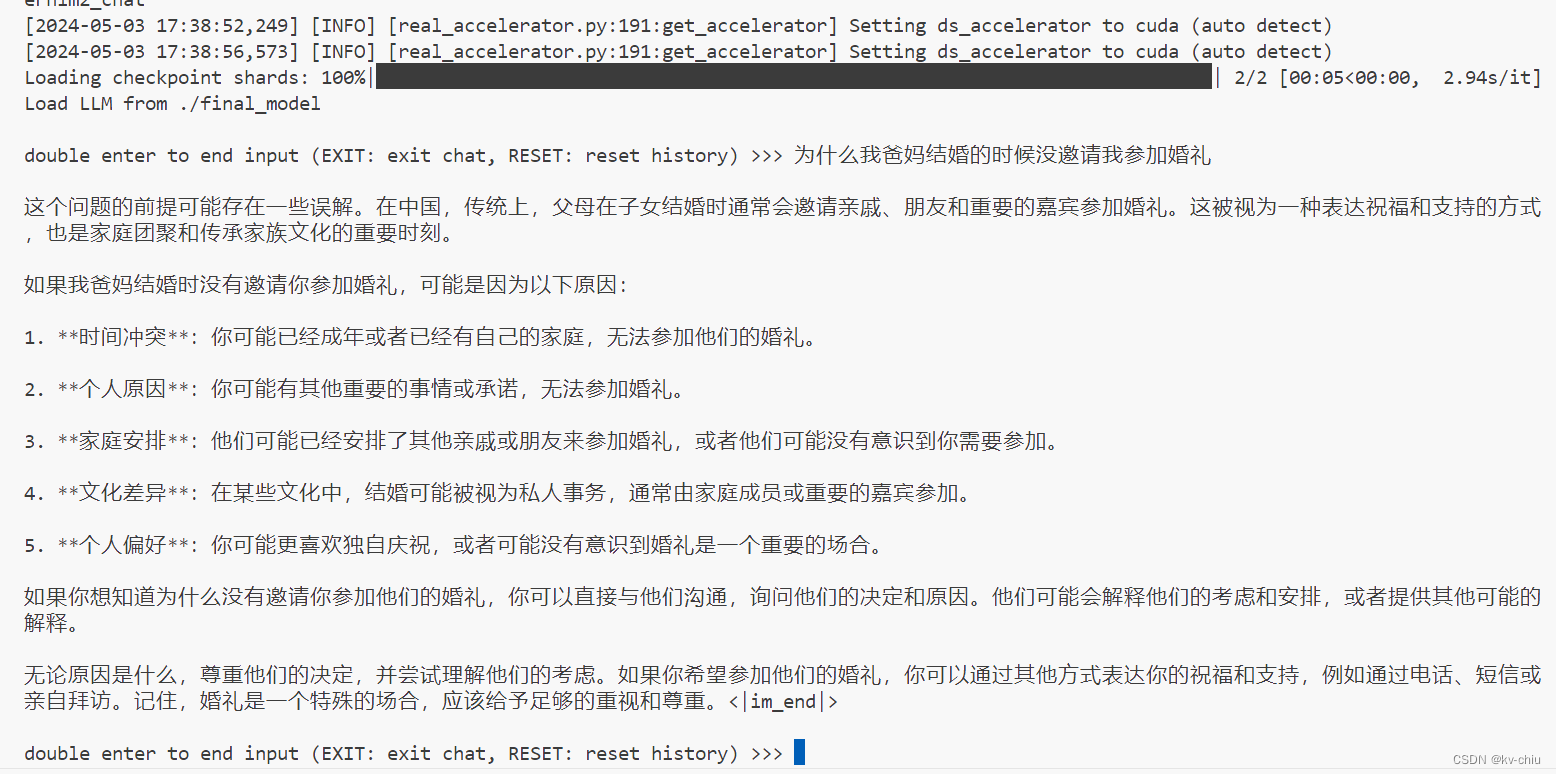
未微调前的效果
















 276
276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









