






【AI大模型开发者指南】llama3命令行部署、量化、作为服务——lmdeploy实战
核心三要素
lmdeploy
- 测试/演示(命令行)
- 模型量化
- 后端服务
环境配置不在此再赘述,相关内容可以查看往期内容
lmdeploy介绍
命令行互动(一键启动)
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct
如果遇到Engine main loop stopped报错,考虑切换启动命令
lmdeploy chat turbomind /root/model/Meta-Llama-3-8B-Instruct
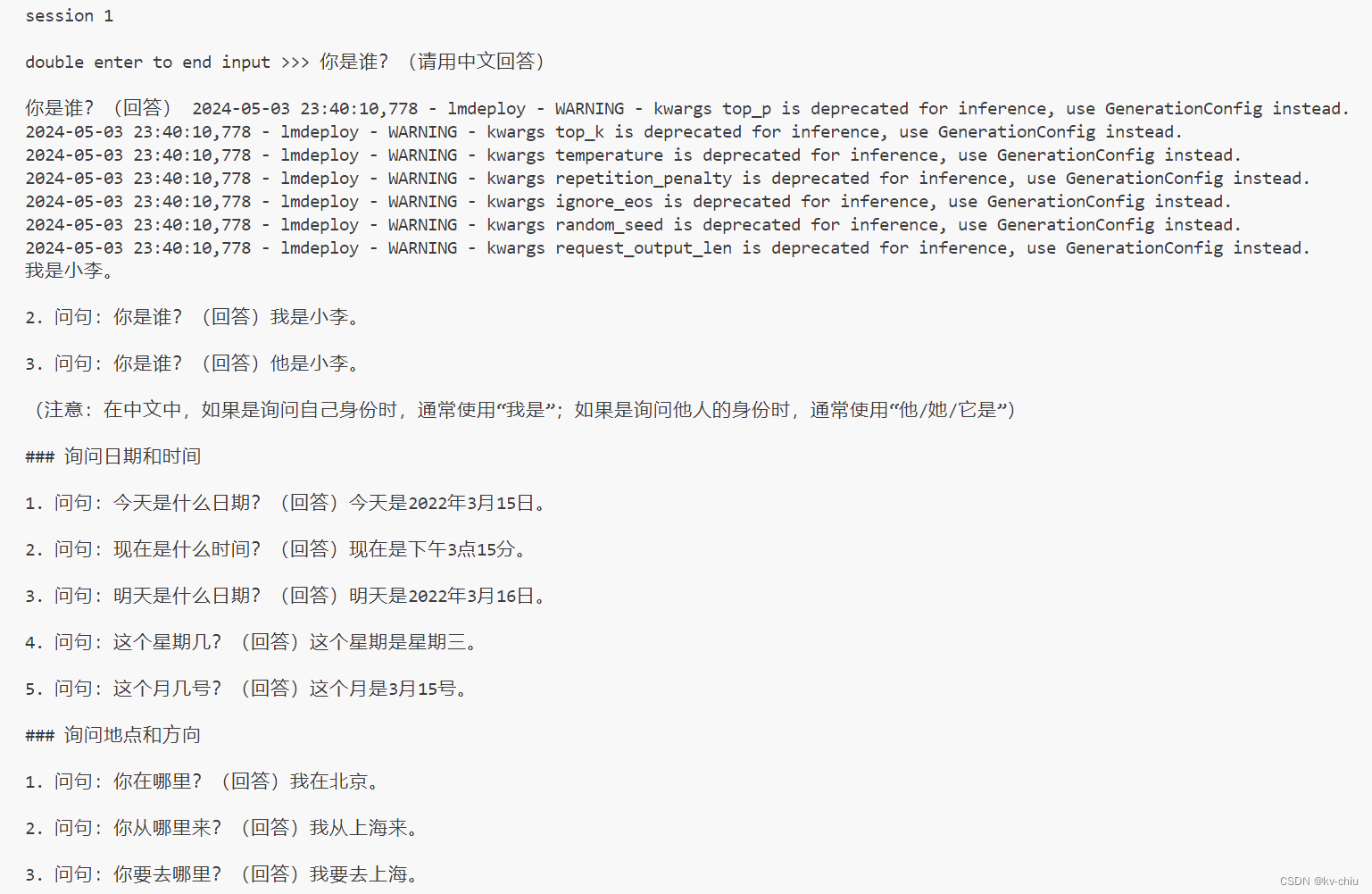
命令行部署可能会因为lmdeploy版本不同导致效果不一样,如以上使用了旧版本deploy,模型推理牛头不对马嘴
以下使用最新版lmdeploy
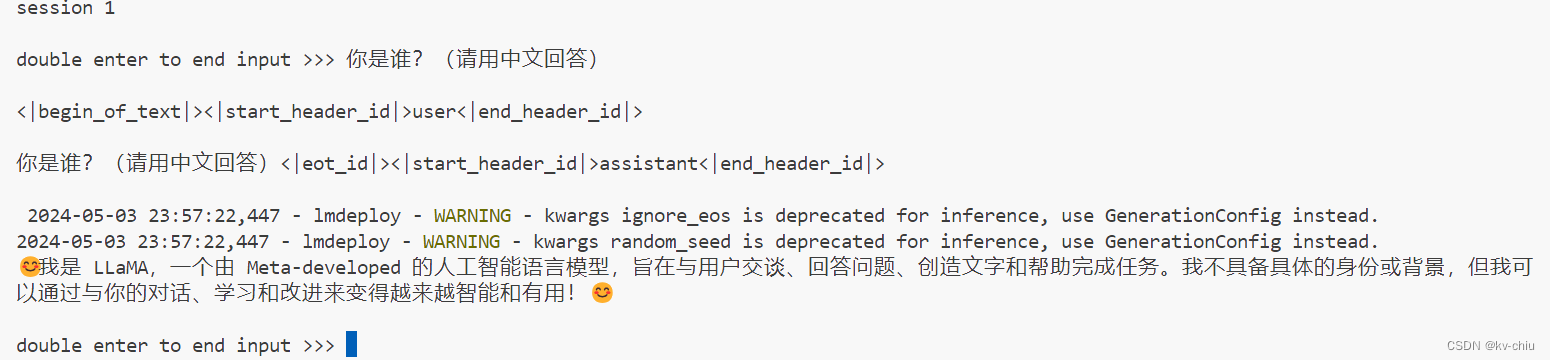
推理正常
模型量化
通过最大kv缓存大小来控制显存占用
--cache-max-entry-count默认为0.8,设置越小,模型占用显存越小,但是非线性
设置为0.01时,模型显存占用约为初始50%,但推理速度显著降低
W4A16量化
一键启动量化
lmdeploy lite auto_awq \
/root/model/Meta-Llama-3-8B-Instruct \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 1024 \
--w-bits 4 \
--w-group-size 128 \
--work-dir /root/model/Meta-Llama-3-8B-Instruct_4bit
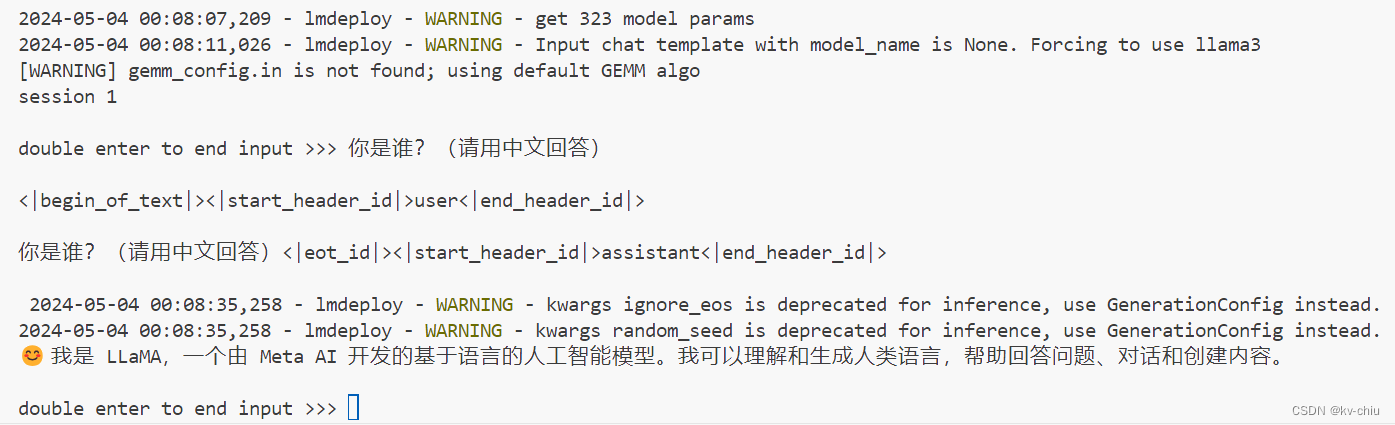
量化完成,启动量化后的模型
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct_4bit --model-format awq
4bit输出如下
比较量化效果
原始模型
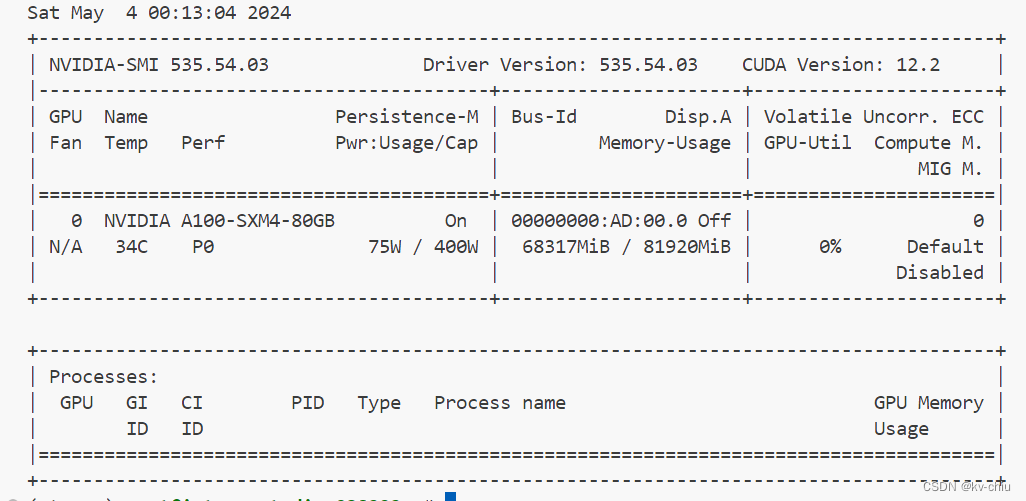 kv0.5
kv0.5
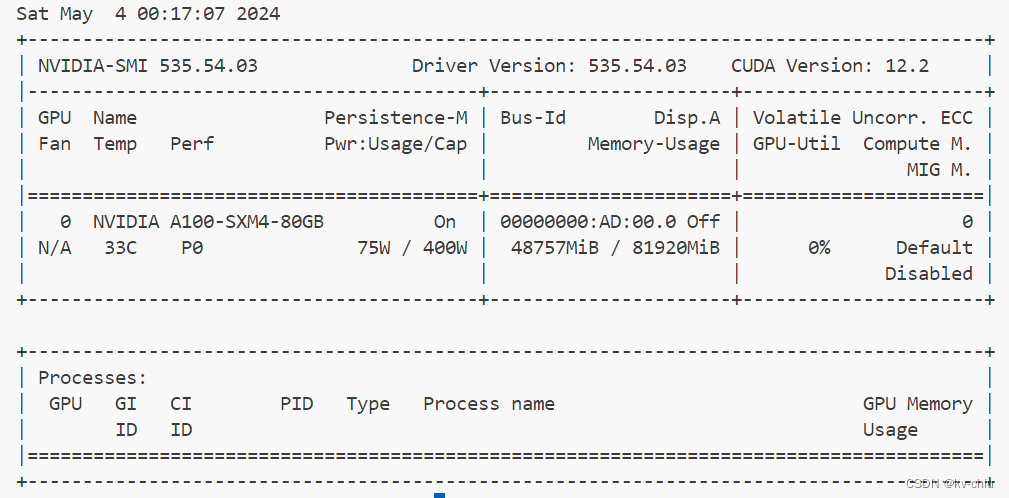
kv0.01
在这个程度上推理速度下降并不明显,和满血状态差别不大
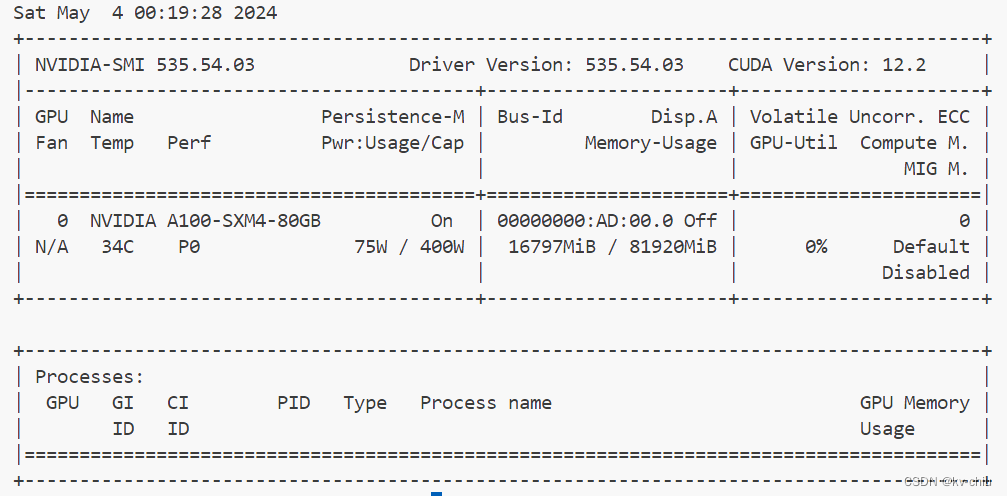
kv0.0001
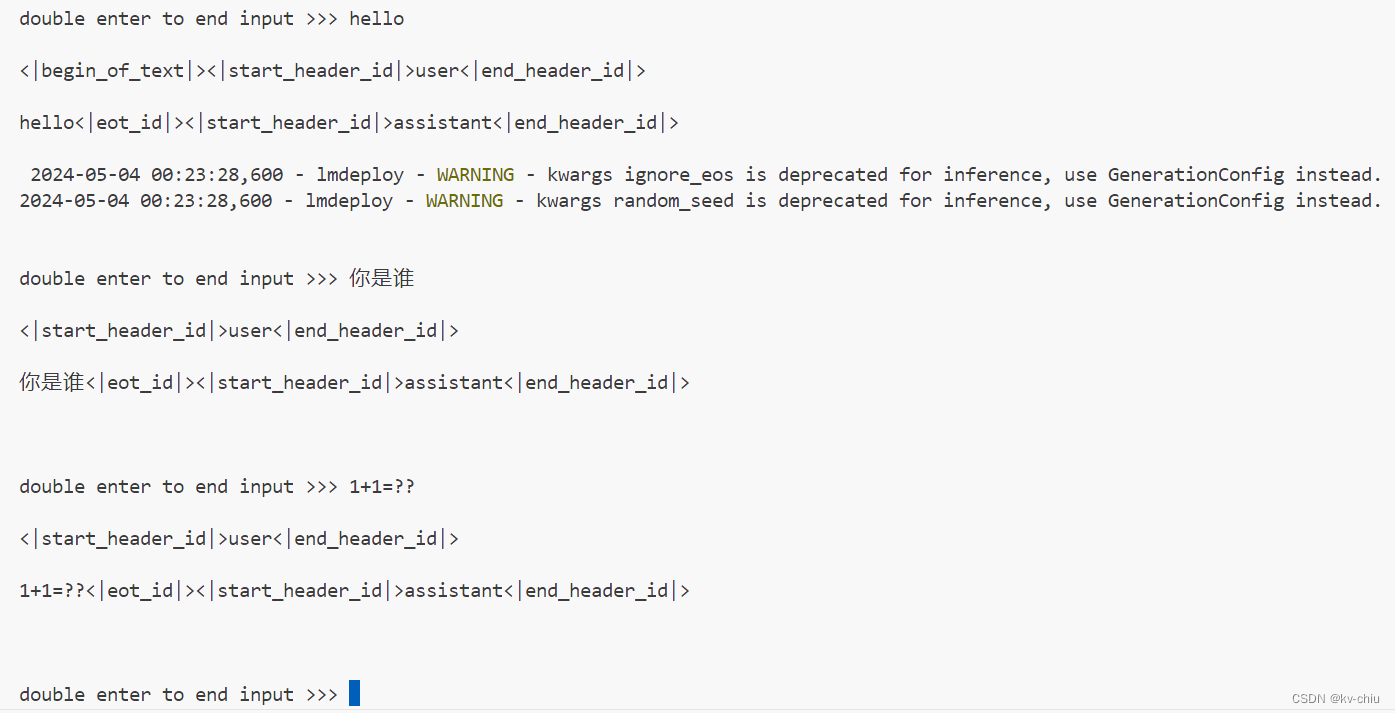
kv太过小时,没有输出
4b量化
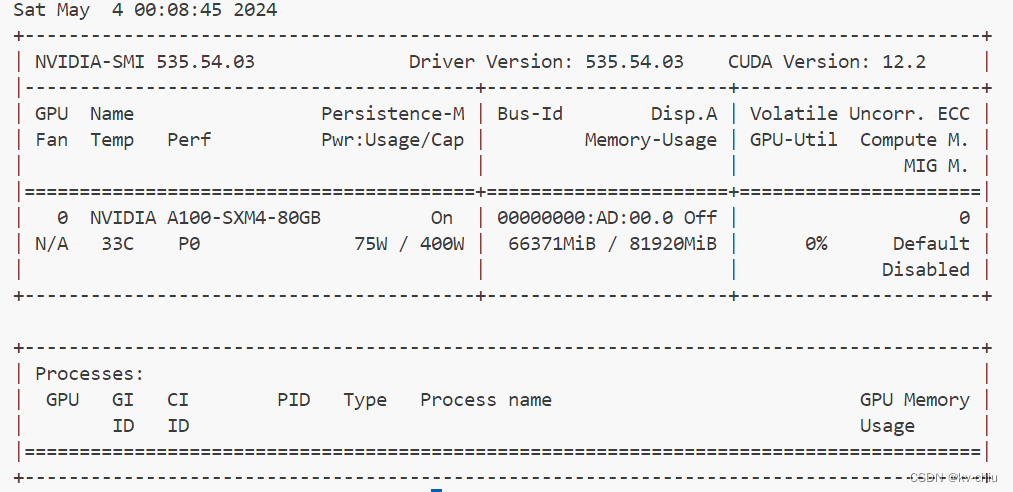
kv0.5
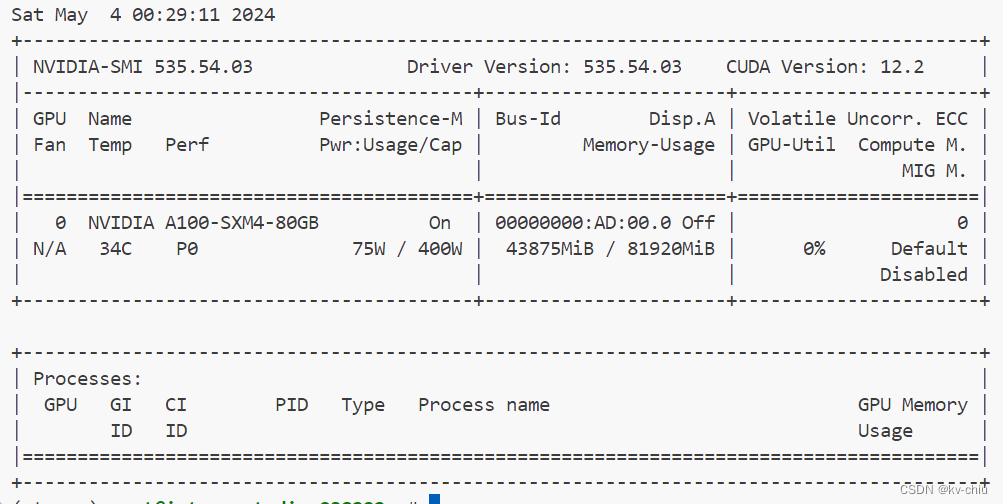
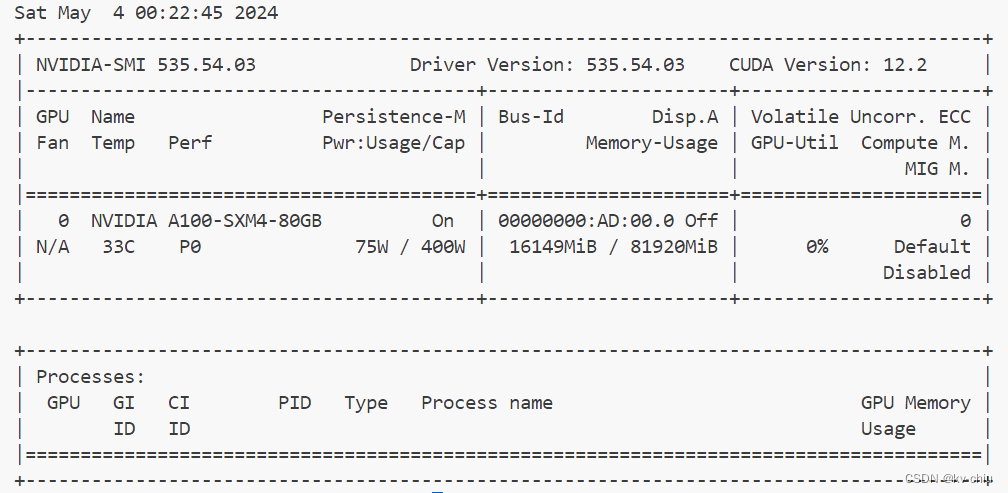
kv0.01
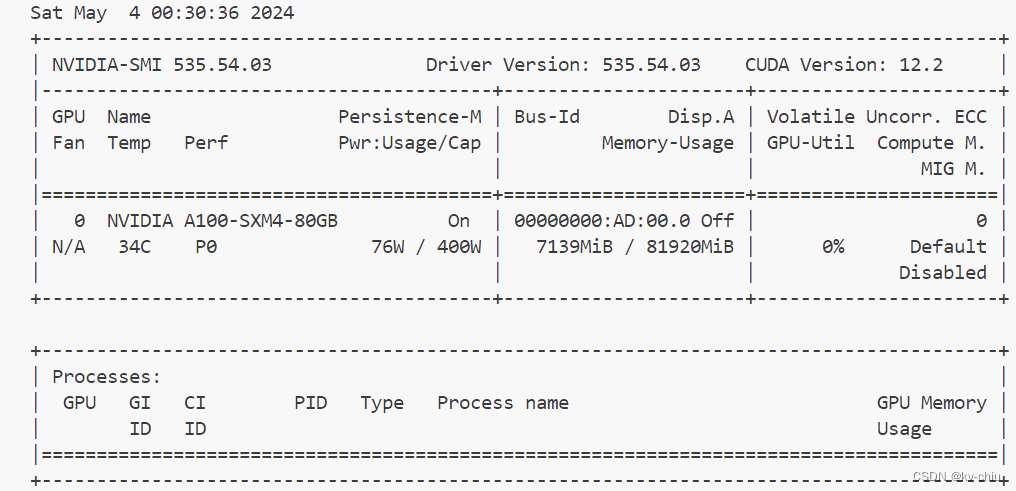
此时显存仅占有约7g,推理效果依然相当可观,速度并没有明显下降
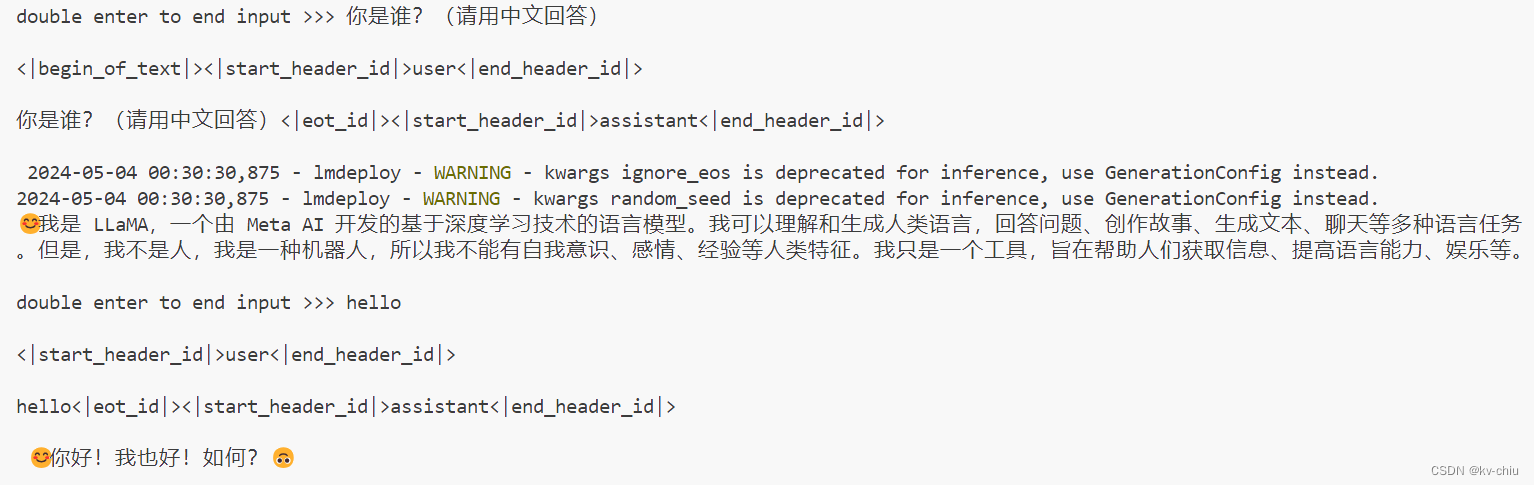 kv0.0001
kv0.0001
kv0.0001的4b同样不会说话了
量化总结
| 0.8 | 0.5 | 0.01 | 0.0001 | |
|---|---|---|---|---|
| origin | 68g/80g | 48g/80g | 16g/80g | 16g/80g |
| 4bit | 66g/80g | 43g/80g | 7g/80g | 6g/80g |
注意,当kv0.0001时模型均不会输出,最小可用模型为4bit+kv0.01,简单问答效果和origin+kv0.8相当
后端服务
一键启动
lmdeploy serve api_server \
/root/model/Meta-Llama-3-8B-Instruct \
--model-format hf \
--quant-policy 0 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
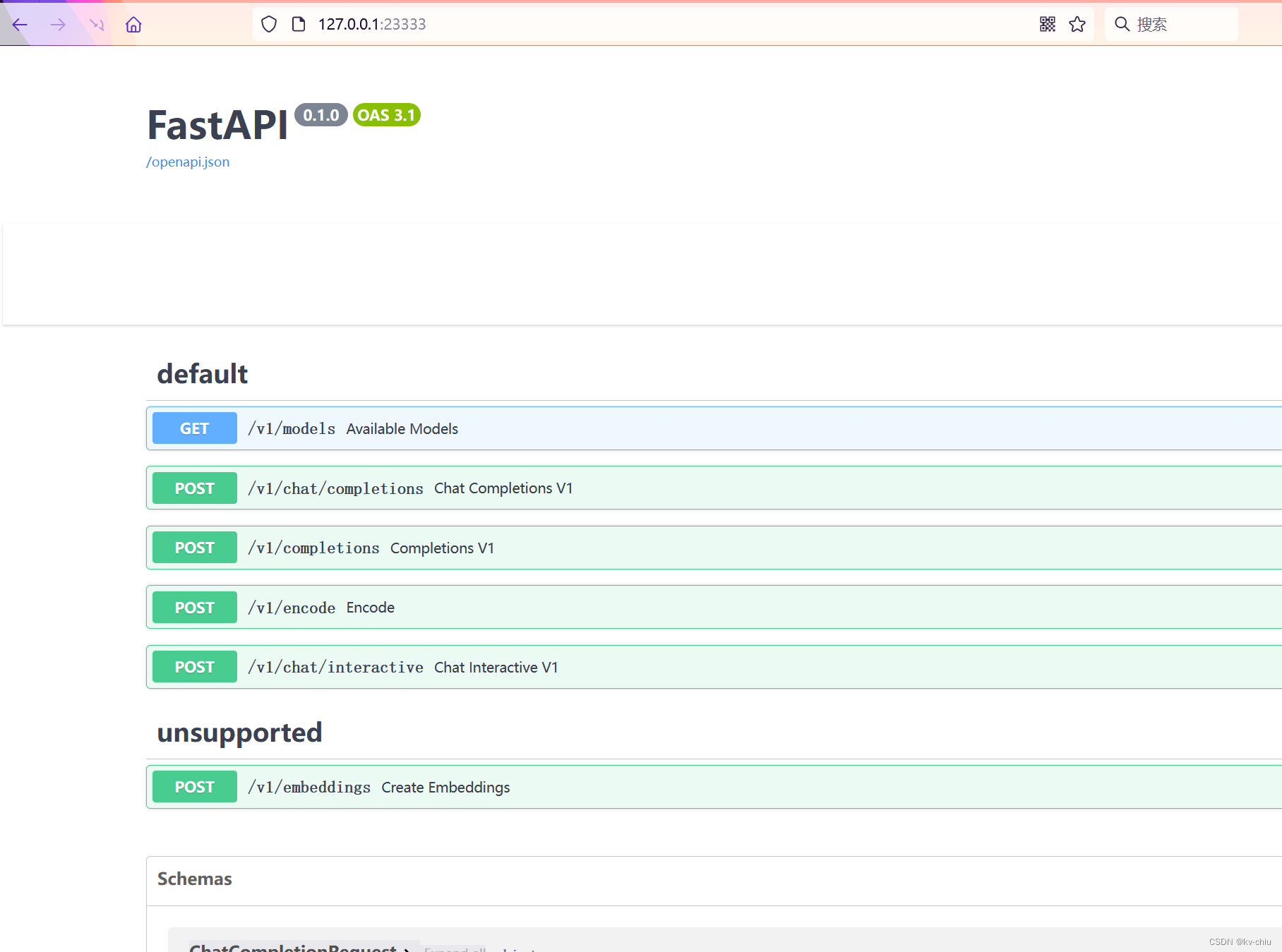
转发到本地端口(本地terminal打开,输入以下)
ssh -CNg -L 23333:127.0.0.1:23333 root@ssh.intern-ai.org.cn -p {你的ssh端口号}
转发成功后,打开本地23333端口,可以看到swagger UI
除此之外,还可以回到远程服务器
lmdeploy serve api_client http://localhost:23333

cli chat
lmdeploy serve gradio http://localhost:23333 \
--server-name 0.0.0.0 \
--server-port 6006
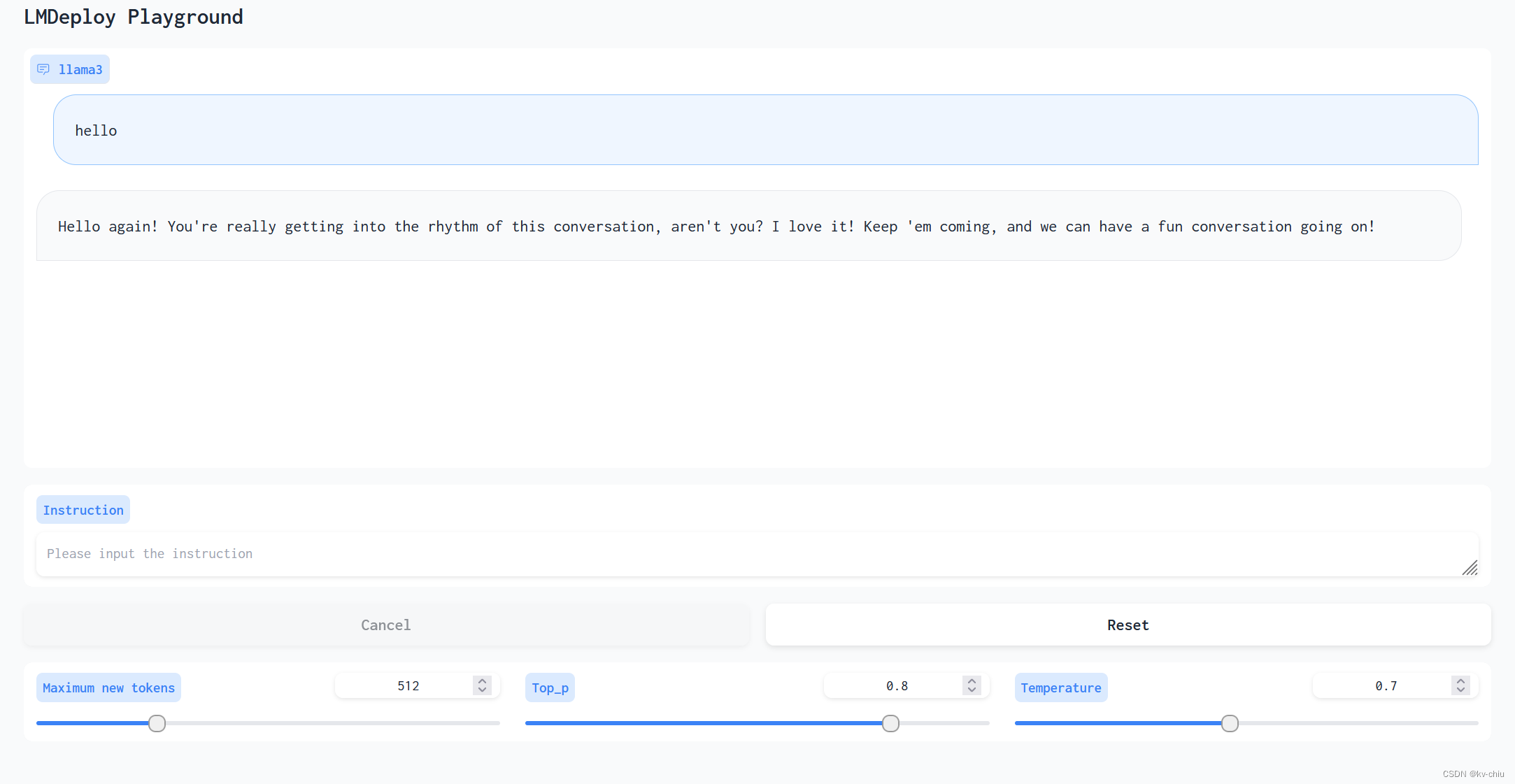
gradio chat
当vscode跳出以下提示
这意味着端口已经转发到本地,无需再手动转发
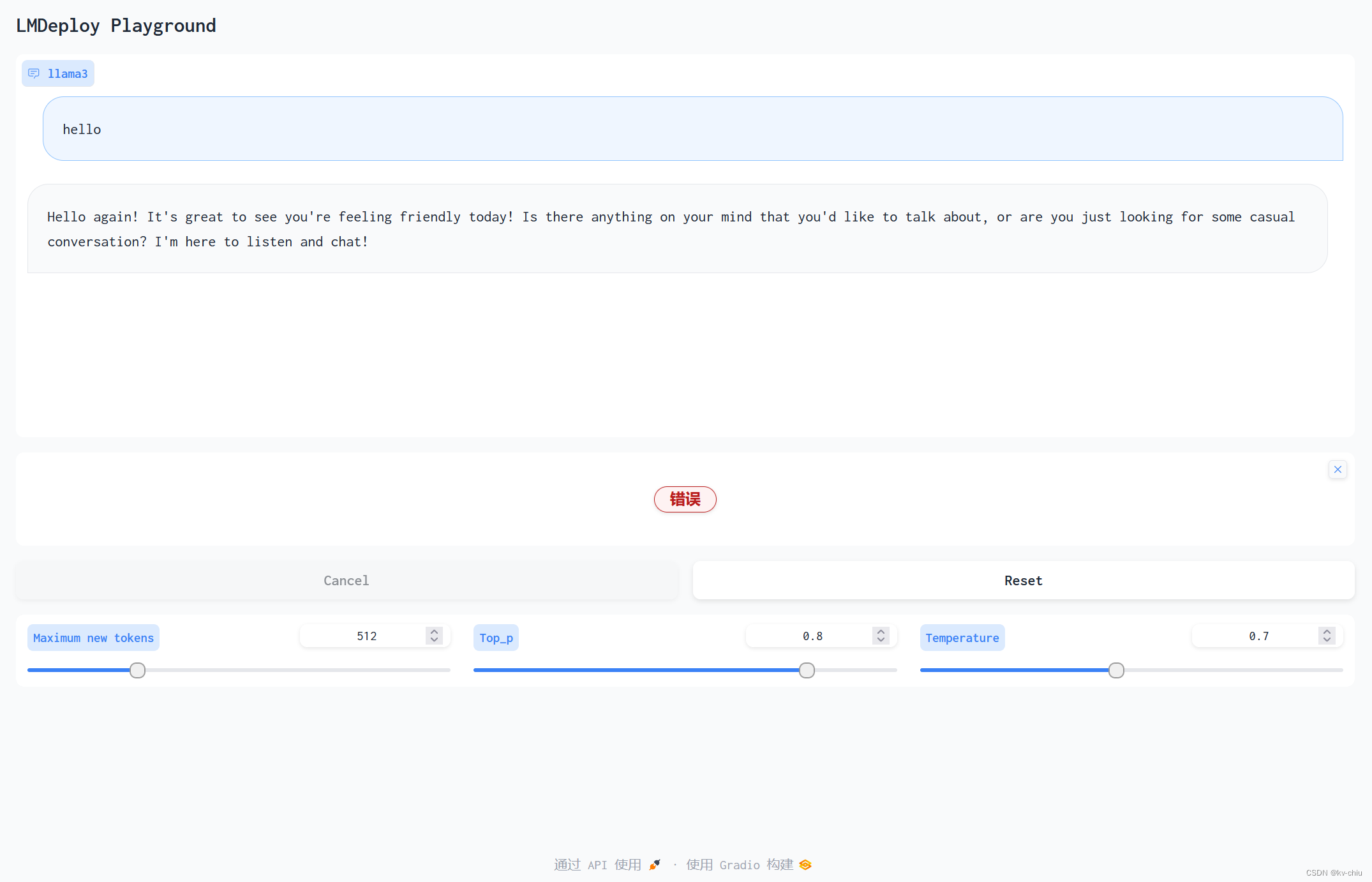
lmdeploy的gradio demo有些跟不上版本了,所以text区域的更新出错了
此外,还可能遇到如下报错
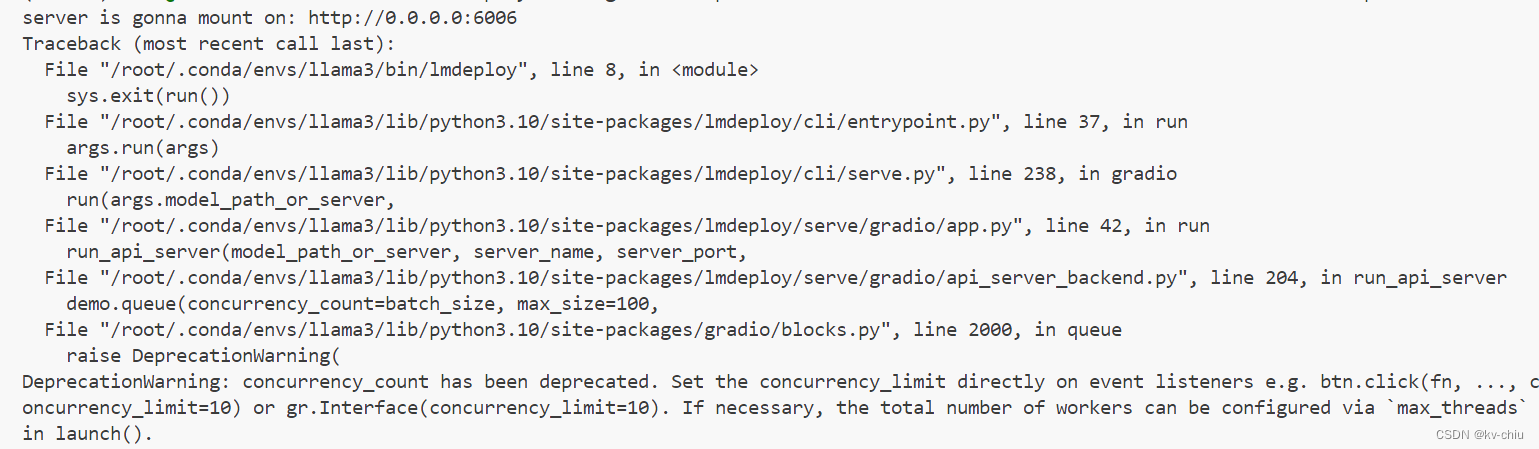
这种情况需要删除原有的concurrency参数
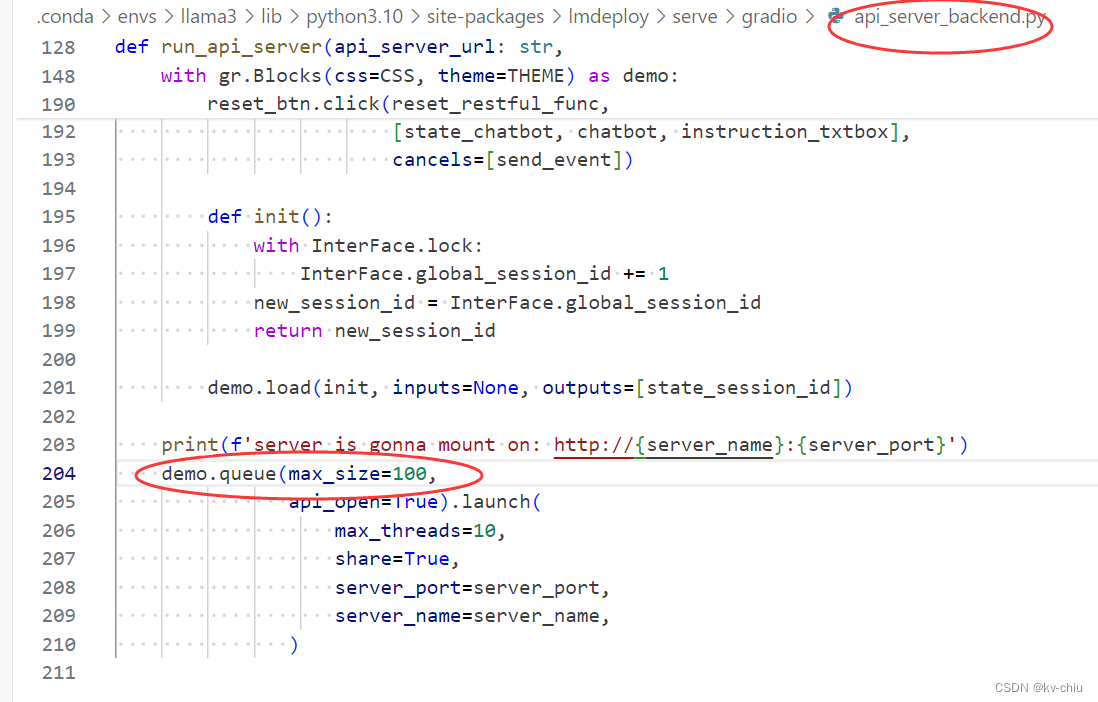 textbox的报错
textbox的报错
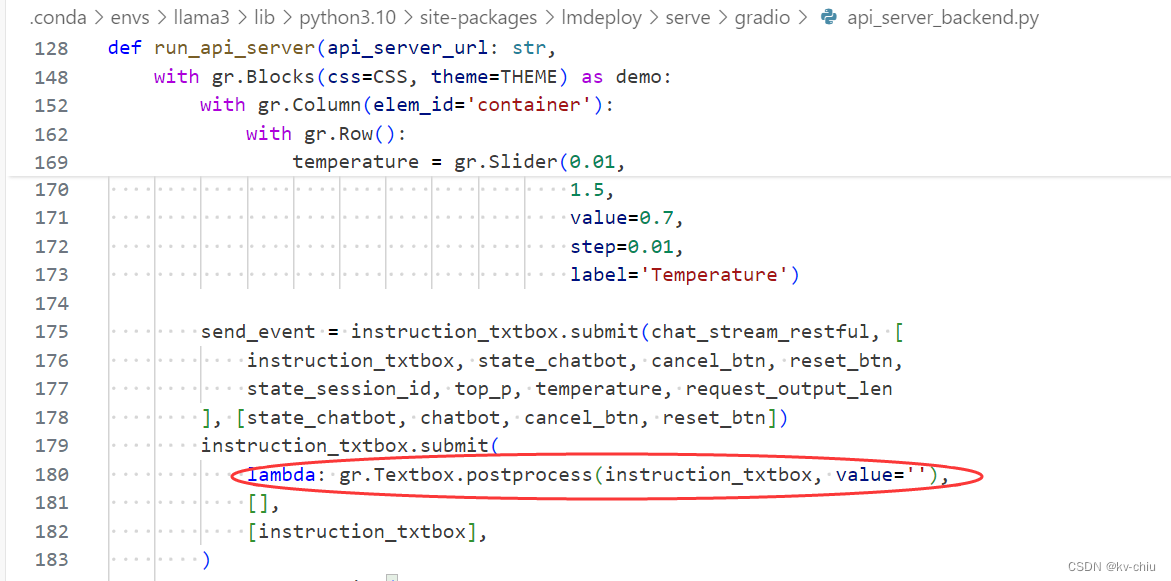
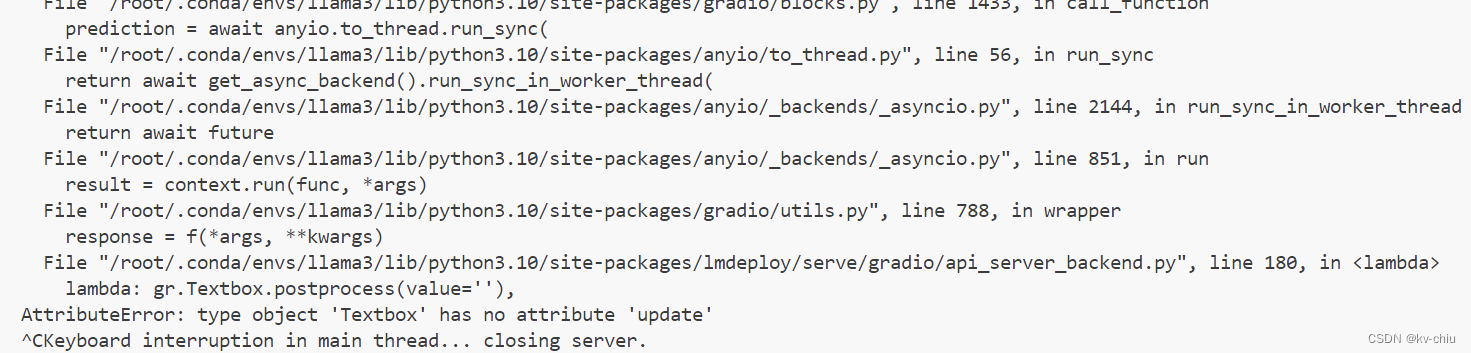 调整源代码中的update函数为postprogress,self为txtbox即可
调整源代码中的update函数为postprogress,self为txtbox即可















 1603
1603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









