






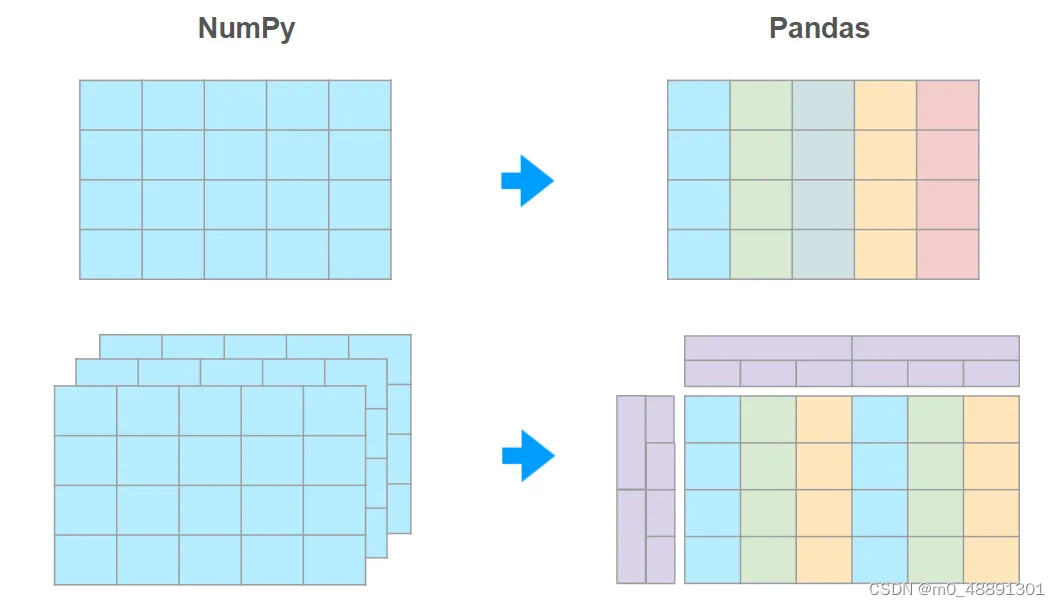
Pandas是用Python分析数据的工业标准。只需敲几下键盘,就可以加载、过滤、重组和可视化数千兆字节的异质信息。
它建立在NumPy库的基础上,借用了它的许多概念和语法约定,所以如果你对NumPy很熟悉,你会发现Pandas是一个相当熟悉的工具。即使你从未听说过NumPy,Pandas也可以让你在几乎没有编程背景的情况下轻松拿捏数据分析问题。
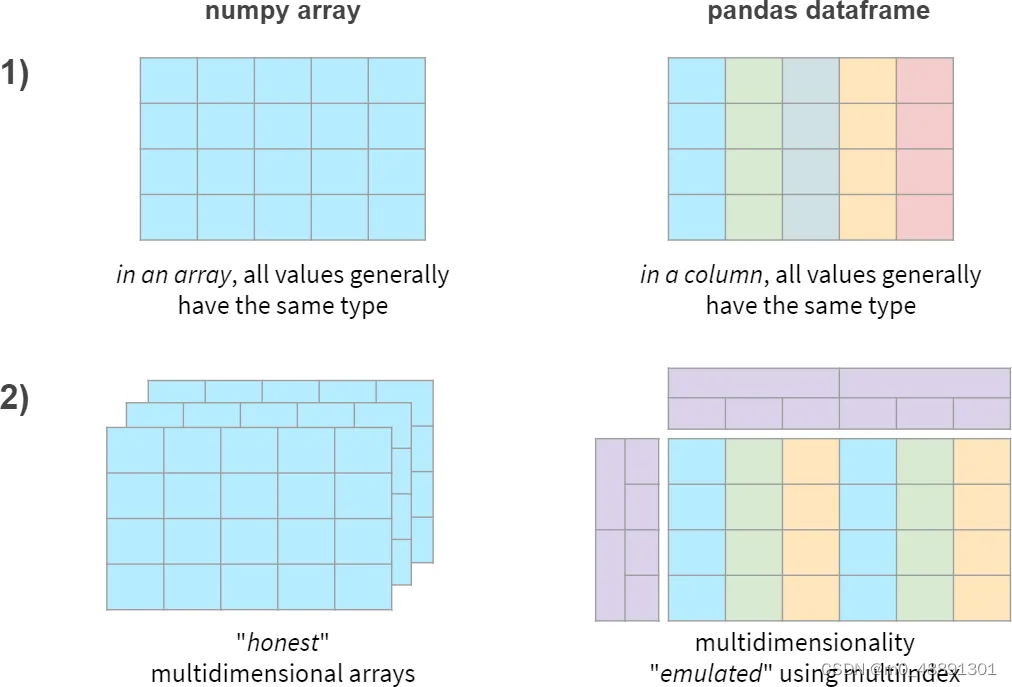
Pandas 给 NumPy 数组带来的两个关键特性是:
- 异质类型 —— 每一列都允许有自己的类型
- 索引 —— 提高指定列的查询速度
事实证明,这些功能足以使Pandas成为Excel和数据库的强大竞争者。
Polars[2]是Pandas最近的转世(用Rust编写,因此速度更快,它不再使用NumPy的引擎,但语法却非常相似,所以学习 Pandas 后对学习 Polars 帮助非常大。
Pandas 图鉴系列文章由四个部分组成:
- Part 1. Motivation
- Part 2. Series and Index
- Part 3. DataFrames
- Part 4. MultiIndex
我们将拆分成四个部分,依次呈现~建议关注和星标@公众号:数据STUDIO,精彩内容等你来~
Part 1 Motivation
假设你有一个文件,里面有一百万行逗号分隔的数值,像这样:

冒号后的空格仅用于说明问题。通常情况下,没有空格。
而你需要用NumPy对 “哪些城市的面积超过450平方公里,人口低于1000万” 这样的基本问题给出答案。
通常情况下,不推荐使用将整个表送入NumPy数组的粗暴解决方案。NumPy数组是同质类型的(=所有的值都有相同的类型),所以所有的字段都会被解译为字符串,在比大小方面也不尽人意。
虽然NumPy也有结构化数组和记录数组,允许不同类型的列,但它们主要是为了与C代码对接。当用于一般用途时,它们有以下缺点:
- 不太直观(例如,你将面临到处都是<f8和<U8这样的常数);
- 与普通的NumPy数组相比,有一些性能问题;
- 在内存中连续存储,所以每增加或删除一列都需要对整个数组进行重新分配;
- 仍然缺乏Pandas DataFrames的很多功能。
如果将每一列存储为一个单独的NumPy向量。之后可以把它们包成一个dict,这样,如果以后需要增加或删除一两行,就可以更容易恢复 “数据库” 的完整性。下面是它的样子:
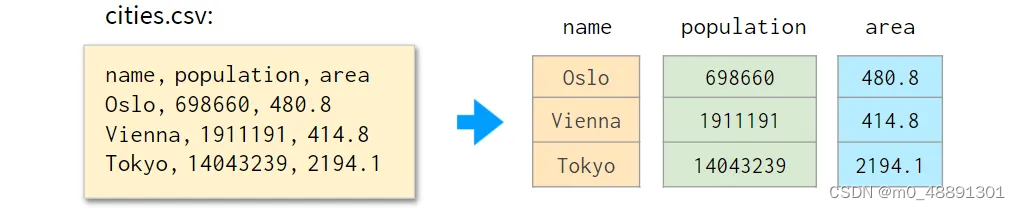
至此我们已经迈出了重新实现Pandas的第一步。
现在,下面有几个例子来说明Pandas可以做一些NumPy不能做的事情(或者需要付出巨大努力才能完成)。
Pandas Showcase
如下表所示:

它描述了一个网上商店的多样化产品线,总共有四种不同的产品。与前面的例子相比,它既可以用NumPy数组表示,也可以用Pandas DataFrame表示,效果同样不错。但来看看它的一些常见操作。
1.Sorting
用Pandas按列排序更有可读性,你可以看到如下:

这里argsort(a[:,1])计算了使a的第二列以升序排序的排列方式,然后外部的a[…]相应地重新排列a的行。Pandas可以在一个步骤中完成。
2.按columns排序
如果我们需要使用权重列按价格列打破平局进行排序,那么对于NumPy来说却有些糟糕:

如果选择使用NumPy,我们首先按重量排序,然后再按价格应用第二次排序。一个稳定的排序算法可以保证第一次排序的结果在第二次排序时不会丢失。用NumPy还有其他方法,但都不如用Pandas简单和优雅。
3.增加一列
从语法和架构上来说,用Pandas添加列要好得多:

Pandas不需要像NumPy那样为整个数组重新分配内存;它只是为新的列添加一个引用,并更新一个列名的 registry。
4.快速元素搜索
对于NumPy数组,即使搜索的元素是第一个,仍然需要与数组大小成比例的时间来找到它。使用Pandas,可以对我们预期最常被查询的列进行索引,并将搜索时间减少到On。

索引栏有以下限制:
- 它需要记忆和时间来建立。
- 它是只读的(在每次追加或删除操作后需要重新建立)。
- 这些值不需要是唯一的,但只有当元素是唯一的时候才会发生加速。
- 它需要热身:第一次查询比NumPy慢一些,但随后的查询就明显快了。
5.按列连接
如果想用另一个表的信息来补充一个基于共同列的表,NumPy几乎没有用。而Pandas更好,特别是对于1:n的关系。
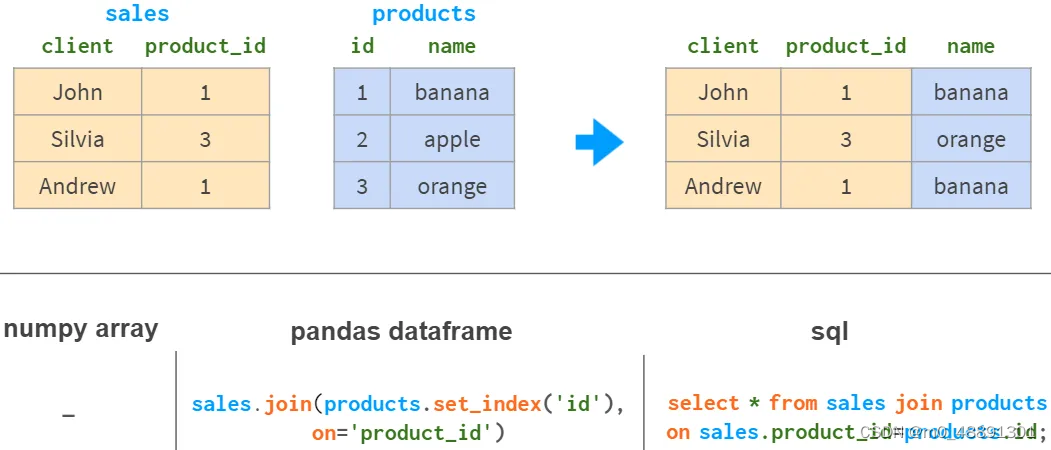
Pandas连接有所有熟悉的 inner, left, right, 和 full outer 连接模式。
6.按列分组
数据分析中另一个常见的操作是按列分组。例如,为了获得每种产品的总销售量,可以做如下操作:

除了sum,Pandas还支持各种聚合函数:mean, max,min, count等等。
7.透视表
Pandas最强大的功能之一是 pivot 表。它类似于将多维空间投射到一个二维平面。
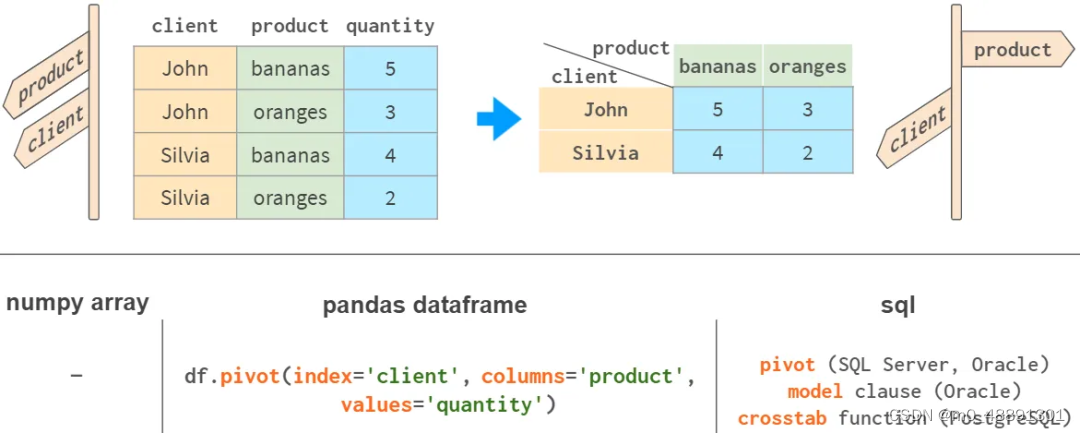
虽然用NumPy当然可以实现。而Pandas也有df.pivot_table,它将分组和透视结合在一个工具中。
说到这里,你可能会想,既然Pandas这么好,为什么还会有人使用NumPy呢?NumPy没有好坏之分,它只是有不同的使用情况:
- 随机数(例如,用于测试)
- 线性代数(例如,用于神经网络)。
- 图像和图像堆叠(例如,用于CNN)。
- 微分、积分、三角学和其他科学人员。
简而言之,NumPy和Pandas的两个主要区别如下:
现在看看这些功能是否以性能的降低为代价。
Pandas的速度
下面对NumPy和Pandas的典型工作负载进行了基准测试:5-100列;10³-10⁸行;整数和浮点数。下面是1行和1亿行的结果:

从测试结果来看,似乎在每一个操作中,Pandas都比NumPy慢!而这并不意味着Pandas的速度比NumPy慢!
当列的数量增加时,没有什么变化。而对于行的数量,二者的对比关系(在对数尺度上)如下图所示:
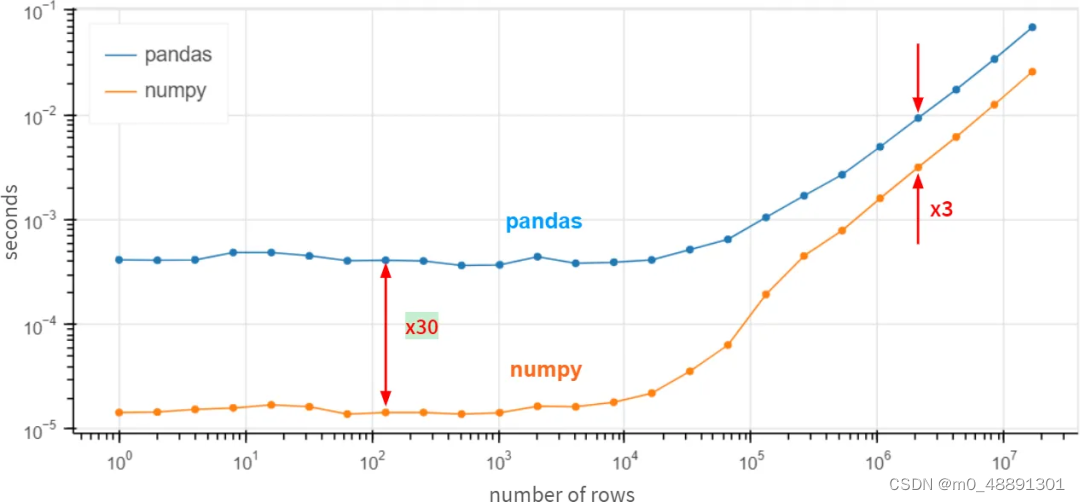
对于小数组(百行以下),Pandas似乎比NumPy慢30倍,对于大数组(百万行以上)则慢3倍。
怎么可能呢?我们提交一个功能请求,建议Pandas通过df.column.values.sum()重新实现df.column.sum()了?这里的values属性提供了对底层NumPy数组的访问,并带来了3-30倍的速度提升。
答案是否定的。Pandas 在这些基本操作上是如此缓慢,因为它正确地处理了缺失值。在Pandas中,做了大量的工作来统一NaN在所有支持的数据类型中的用法。根据定义(在CPU层面上强制执行),nan+任何东西的结果都是nan。
所以在numpy中计算求和时:
>>> np.sum([1, np.nan, 2])
nan
但使用pandas计算求和时:
>>> pd.Series([1, np.nan, 2]).sum()
3.0
一个公平的比较是用np.nansum代替np.sum,np.nanmean代替np.mean,等等。突然间…
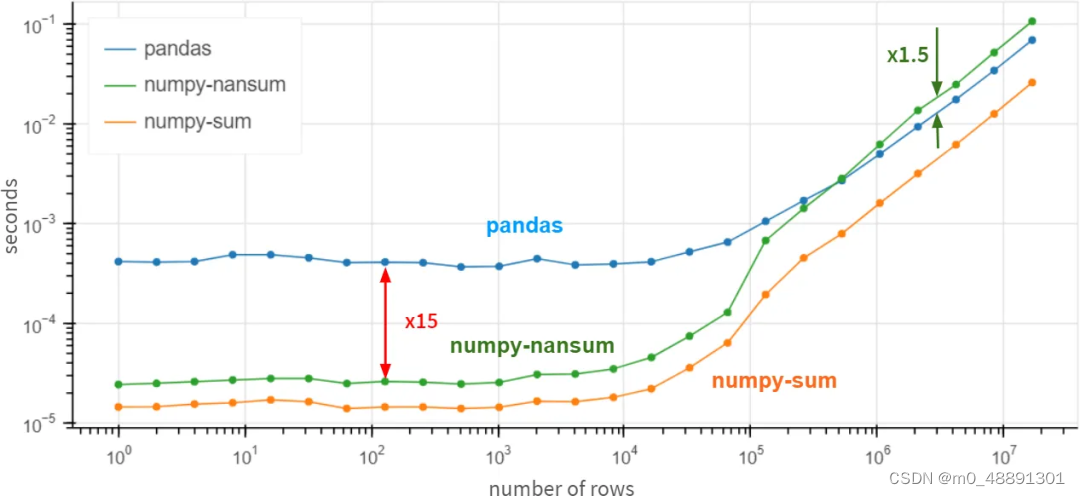
对于超过一百万元素的数组,Pandas变得比NumPy快1.5倍。对于较小的数组,它仍然比NumPy慢15倍,但通常情况下,操作在0.5毫秒或0.05毫秒内完成并不重要–反正是快了。
如果你100%确定你的列中没有缺失值,那么使用df.column.values.sum()而不是df.column.sum()来获得x3-x30的性能提升是有意义的。在存在缺失值的情况下,Pandas的速度是相当不错的,对于巨大的数组(超过10⁶个元素)来说,甚至比NumPy还要好。















 2016
2016











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









