






 文章介绍了GLM(GeneralLanguageModel),这是一种新型的预训练模型,旨在统一自回归和自编码架构的优点。GLM通过2D位置编码和自回归空白填充方法改进了预训练,能适应NLU和文本生成任务。实验表明,GLM在NLU任务上的性能优越,并且能够有效共享不同任务的参数。
文章介绍了GLM(GeneralLanguageModel),这是一种新型的预训练模型,旨在统一自回归和自编码架构的优点。GLM通过2D位置编码和自回归空白填充方法改进了预训练,能适应NLU和文本生成任务。实验表明,GLM在NLU任务上的性能优越,并且能够有效共享不同任务的参数。
深度学习:GLM(General Language Model)论文阅读笔记
Introduction
现在有很多Pretrain model 的架构, 如Bert、GPT、T5等,但是当时没有一种模型能在NLU、有条件文本生成、无条件文本生成都有很好的表现。
一般预训练模型架构分为三种:自回归(GPT系列)、自编码(Bert系列)、编码器-解码器(T5)。
作者概述了它们目前存在的问题·:
- GPT:单向的注意力机制,不能完全捕捉NLU任务中上下文词之间的依赖关系。
- Bert:编码器可以更好的提取上下文信息,但是不能直接用于文本生成。
作者提到上述框架不够灵活,之前也有人做过统一这两个架构的工作,但是自编码与自回归本质的不同,不能很好的继承两个架构的优点,于是提出了一个基于自回归空白填充的语言模型(GLM),GLM通过2D的 positional encoding和允许一个任意的predict spans 来改进空白填充预训练。同时,GLM可以通过改变空白的数量和长度对不同类型的任务进行预训练。
GLM Pretraining Framework
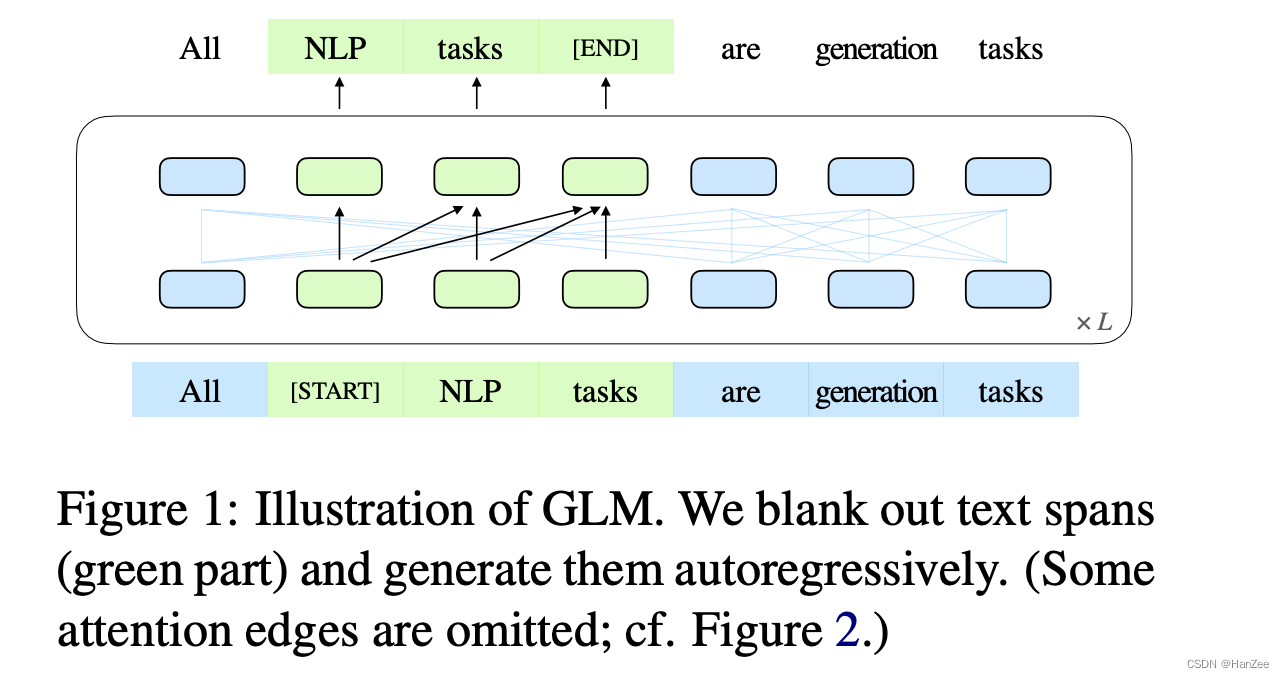
它基于一个新颖的自回归空白填充目标。GLM将NLU任务制定为包含任务描述的cloze问题,这些问题可以通过自回归生成来回答。
Autoregressive Blank Infilling

- 给定Input=[x1,x2,x3,x3,x5,x6],然后采样m个 spans。
- 把被采样的部分mask掉,得到Part A。
- random 被采样的 spans,得到 PartB。
- 把PartA与PartB拼接成一个sequence,Part A部分采用双向注意力,PartB部分采样自回归预测。为了能够自回归生成,padded 【start】和【end】。
Multi-Task Pretraining
在上一节中,GLM掩盖了短跨度,适用于NLU任务。然而,作者对预训练一个能同时处理NLU和文本生成的单一模型感兴趣,考虑以下两个目标。
-
Document-level:对单一跨度进行采样,其长度从原始长度的50%-100%的均匀分布中抽出。该目标旨在生成长文本。
-
Sentence-level:限制被mask的跨度必须是完整的句子。多个跨度(句子)被取样,以覆盖15%的原始token。这一目标是针对seq2seq任务,其预测往往是完整的句子或段落。
这两个新目标的定义与原目标相同,唯一不同的是的跨度数量和跨度长度。
Model Architecture
GLM使用单一的Transformer,并对架构进行了一些修改:
(1)重新安排了层的归一化和残差连接的顺序,这已被证明对大规模语言模型避免数字错误至关重要。
(2)使用单一的线性层进行输出token预测。
(3)用GeLU替换ReLU激活函数。
2D Positional Encoding

Experiment
略
Conclusion
GLM是一个用于自然语言理解和生成的通用预训练框架。NLU任务可以被表述为条件生成任务,因此可以通过自回归模型来解决。GLM将不同任务的预训练目标统一为自回归空白填充、混合注意力mask和新的二维位置编码。经验表明,GLM在NLU任务中的表现优于以前的方法,并且可以有效地共享不同任务的参数。



















 2797
2797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











