






GLM:带自回归空白填充的通用语言模型预训练
Zhengxiao Du∗1;2 Yujie Qian∗3 Xiao Liu1;2 Ming Ding1;2 Jiezhong Qiu1;2 Zhilin Yangy1;4 Jie Tang
代码和预训练模型可在https://github.com/THUDM/GLM上获得
我的chatglm技术交流群:762697926
目录
C Results on Other NLU Benchmarks
摘要
有各种类型的预训练架构,包括自编码模型(例如BERT)、自回归模型(例如GPT)和编码器-解码器模型(例如T5)。
然而,在自然语言理解(NLU)、无条件生成(unconditional generation)和条件生成(conditional generation)这三个主要类别的所有任务中,没有一个预训练框架表现最好。我们提出了一种基于自回归空白填充的通用语言模型(GLM)来解决这一挑战。
通过添加二维位置编码和允许任意顺序预测跨度,GLM改进了空白填充预训练,这使得在NLU任务上比BERT和T5的性能有所提高。同时,通过改变空格的数量和长度,可以对不同类型的任务进行GLM的预训练。在NLU、条件生成和无条件生成的广泛任务中,在相同模型大小和数据的情况下,GLM优于BERT、T5和GPT,并在单个BERTLarge参数为1.25倍的预训练模型上取得了最佳性能,证明了其对不同下游任务的泛化能力1
1介绍
在未标记文本上预先训练的语言模型已经大大推进了各种自然语言处理任务的技术水平,从自然语言理解(NLU)到文本生成(拉德福德等人,2018a德夫林等人,2019;杨等,2019;拉德福德等人,2018年b;拉斐尔等人,2020;刘易斯等人,2019;布朗等人,2020)。在过去几年中,下游任务性能以及参数的规模也在不断增加。
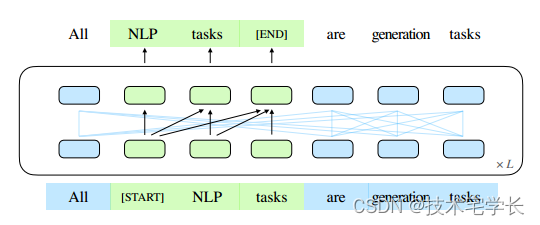
图1:GLM的示意图。我们清空文本范围(绿色部分)并自动生成它们。(部分注意边省略;参见图2。)
一般来说,现有的预训练框架可以分为三类:自回归、自动编码和编码器-解码器模型。自回归模型,如GPT(拉德福德等人,2018年a),学习从左到右的语言模型。虽然它们在长文本生成方面取得了成功,并且在扩展到数十亿个参数时显示出较少的短时学习能力(拉德福德等人,2018bBrown et al,2020),固有的缺点是单向注意机制,不能完全捕捉NLU任务中上下文词之间的依赖关系。自动编码模型,如BERT (Devlin等人,2019年),通过去噪目标学习双向上下文编码器,如掩蔽语言模型(MLM)。编码器产生适合自然语言理解任务的上下文化表示,但是不能直接应用于文本生成。编解码模型对编码者采用双向注意,对解码者采用单向注意,两者之间采用交叉注意(宋等,2019;毕等,2020;Lewis等人,2019)。
它们通常部署在条件生成任务中,例如文本摘要和响应生成。2 .T5 (Raffel等人,2020年)通过编码器-解码器模型统一了NLU和条件生成,但需要更多参数来匹配基于BRET的模型的性能,如RoBERTa(刘等人,2019年)和DeBERTa(何等人,2021年)
这些预训练框架没有一个足够灵活,能够在所有NLP任务中有竞争力地执行。以前的工作试图通过多任务学习结合目标来统一不同的框架(董等,2019;鲍等,2020)。然而,由于自动编码和自回归目标本质上不同,简单的统一不能完全继承两种框架的优点。
本文提出了一种基于自回归空白填充的预训练框架——GLM(General Language Model)。我们按照自动编码的思想,从输入文本中随机剔除连续范围的标记,并按照自回归预训练的思想,训练模型顺序重建范围(见图1)。虽然在T5 (Raffel等人,2020)中已经使用消隐填充进行文本到文本的预训练,但是我们提出了两种改进,即跨度混洗和2D位置编码。根据经验,我们表明,在相同的参数和计算成本下,GLM在SuperGLUE基准测试中明显优于BERT 4.6%-5.0%,并且在类似大小(158GB)的语料库上进行预训练时优于RoBERTa和BART。GLM在NLU和发电任务上也明显优于T5,参数和数据更少。
受模式开发训练(PET)的启发(Schick和Schütze,2020a),我们将NLU任务重新表述为模仿人类语言的手工完形填空题。与PET使用的基于PET的模型不同,GLM可以通过自回归填空自然地处理完形填空问题的多标记答案。
此外,我们表明,通过改变缺失区间的数量和长度,自回归空白填充目标可以预训练语言模型,以进行条件和无条件生成。
通过不同预训练目标的多任务学习,单个GLM可以在NLU和(有条件和无条件)文本生成两方面都表现出色。根据经验,与独立基线相比,通过共享参数,多任务预训练GLM在NLU、条件文本生成和语言建模任务方面都取得了改进。
2 GLM 预训练框架
我们提出了一种基于新型自回归空白填充目标的通用预训练框架 GLM。 GLM 将 NLU 任务制定为包含任务描述的完形填空问题,可以通过自回归生成来回答
2.1 预训练目标
2.1.1 自回归空白填充
GLM 通过优化自回归空白填充目标来训练。给定输入文本 x = [x1; · · · ; xn],多个文本跨度fs1; · · · ; smg 被采样,其中每个跨度 si 对应于一系列连续的标记 [si;1; · · · ; si;li ] 在 x 中。
每个范围都被替换为单个 [MASK] 标记,形成损坏的文本 xcorrupt。该模型以自回归方式从损坏的文本中预测跨度中丢失的标记,这意味着在预测跨度中丢失的标记时,模型可以访问损坏的文本和之前预测的跨度。为了充分捕获不同跨度之间的相互依赖性,我们随机排列跨度的顺序,类似于排列语言模型(Yang 等人,2019)。形式上,令 Zm 为长度为 m 的索引序列 [1; 的所有可能排列的集合; 2; · · · ; m],且 sz<i 为 [sz1 ; · · · ; szi−1 ],我们将预训练目标定义为
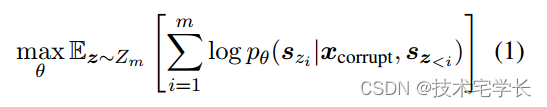
我们总是按照从左到右的顺序在每个空白中生成标记,即生成跨度 si 的概率因式分解为:
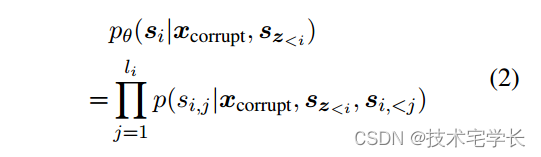
我们使用以下技术实现自回归空白填充目标。输入 x 分为两部分:A 部分是损坏的文本 xcorrupt,B 部分由屏蔽的范围组成。 A 部分令牌可以相互关注,但不能关注 B 中的任何令牌。B 部分令牌可以关注 A 部分和 B 中的前因,但不能关注 B 中的任何后续令牌。为了启用自回归生成,每个跨度都会被填充带有特殊标记 [START] 和 [END],分别用于输入和输出。通过这种方式,我们的模型在一个统一的模型中自动学习双向编码器(用于部分a)和单向解码器(用于部分B)。GLM的实现如图2所示。
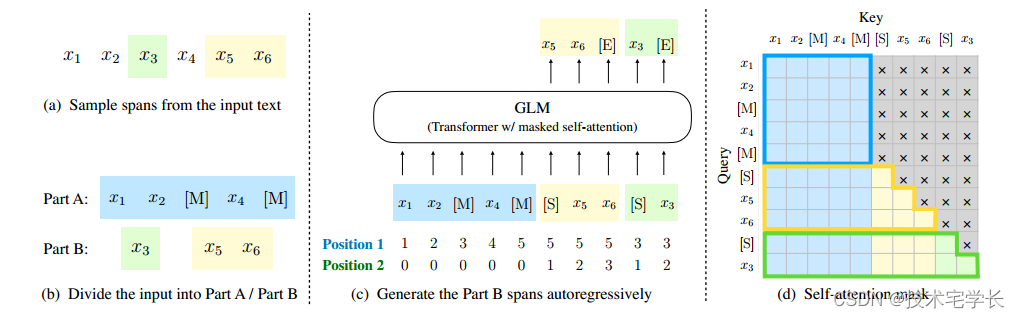
图2:GLM预训练。(a)原文为1,2,3,4,5,。对两个跨度3和t5, e进行采样(b)将A部分的采样跨度替换为(M),并对b部分的跨度进行洗刷(C) GLM自回归生成b部分。每个跨度都以[S]作为输入,并以(e)作为输出。2D位置编码表示跨间和跨内位置。(d)自我注意面具。灰色地带被掩盖了。部分attoken可以关注自身(蓝色帧),但不能关注B。部分B token可以关注A及其在B中的先行项(黄色和绿色帧对应两个跨度)。M:= MASK, S]:= START), E):=END END)。
2.1.2多任务预训
在上一节中,GLM掩盖了短跨度,适合于NLU任务。然而,我们有兴趣预先训练一个既能处理NLU又能处理文本生成的模型。然后,我们研究了一个多任务预训练设置,其中生成更长文本的第二个目标与空白填充目标联合优化。我们考虑以下两个目标:
·文档级。我们从原始长度的50%-100%的均匀分布中采样其长度的单个跨度。目标是生成长文本。
·句子级。我们限制掩码跨度必须是完整的句子。多个跨度(句子)被抽样以覆盖原始标记的15%。这一目标针对的是预测往往是完整句子或段落的连续第二次任务。
两个新目标的定义方式与原始目标相同,即公式1。唯一的区别是跨度的数量和跨度的长度。
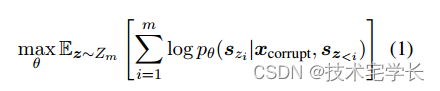
2.2模型体系结构
GLM使用单个Transformer,并对体系结构进行了一些修改:(1)我们重新安排了层归一化和残差连接的顺序,这对于大规模语言模型避免数值误差至关重要(Shoeybi等人,2019);(2)我们使用单个线性层进行输出令牌预测;(3)我们用gelu替换ReLU激活函数(Hendrycks and Gimpel, 2016)。
2.2.1二维位置编码。
如何对位置信息进行编码是自回归填充空白任务的难点之一。转换器依靠位置编码来注入符号的绝对位置和相对位置。我们提出二维位置编码来解决这一挑战。具体来说,每个标记都用两个位置id编码。第一个位置id表示损坏文本xcorrupt中的位置。对于掩码跨度,它是对应的[MASK]令牌的位置。第二个位置id表示跨内位置。对于Part A中的令牌,它们的第二个位置id为0。对于B部分中的令牌,它们的范围从1到跨度的长度。两个位置id通过可学习的嵌入表被投影成两个向量,这两个向量都被添加到输入标记嵌入中。
我们的编码方法保证了模型在重建时不知道掩码跨度的长度. 与其他模型相比,这是一个重要的区别。例如,XLNet (Yang等人,2019)对原始位置进行编码,以便能够感知缺失令牌的数量,SpanBERT (Joshi等人,2020)用多个[MASK]令牌替换span,并保持长度不变。我们的设计适合下游任务,因为通常事先不知道生成文本的长度.
2.3微调GLM
通常,对于下游NLU任务,线性分类器将由预训练模型产生的序列或标记的表示作为输入,并预测正确的标签。实践与生成式预训练任务不同,导致预训练和微调之间的不一致。
相反,我们将NLU分类任务重新制定为空白填充的生成任务,遵循PET (Schick and sch tze, 2020a)。具体来说,给定一个标记的例子(x;Y),我们通过包含单个掩码令牌的模式将输入文本x转换为完形问题c(x)。该模式是用自然语言编写的,以表示任务的语义。例如,一个情感分类任务可以表述为“{SENTENCE}”。这真的是[面具]”。候选标签y和y也被映射到完形填空的答案,称为verbalizer v(y)。在情感分类中,标签“积极”和“消极”被映射到单词“好”和“坏”。在给定x的情况下预测y的条件概率是
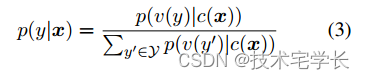
其中Y是标签集。因此,句子是积极的还是消极的概率与预测空格中的“好”或“坏”成正比。
然后我们用交叉熵损失对GLM进行微调(见图3)。
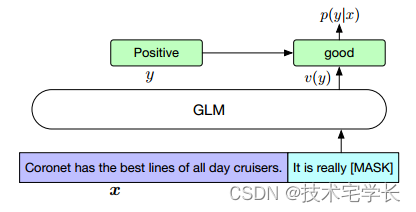
图3:用GLM填充空白的情感分类任务公式。
对于文本生成任务,给定的上下文构成了输入的A部分,并在末尾附加了一个掩码令牌。该模型自回归生成B部分的文本。我们可以直接将预训练好的GLM应用于无条件生成,或者对下游条件生成任务进行微调
2.4讨论与分析
在本节中,我们将讨论GLM与其他预训练模型的区别。我们主要关注的是它们如何适应下游的空白填充任务。
与BERT的比较(Devlin et al ., 2019)。
正如(Yang et al ., 2019)所指出的那样,由于传销的独立性假设,BERT无法捕获掩膜令牌的相互依赖性。BERT的另一个缺点是它不能正确地填补多个令牌的空白。为了推断长度为l的答案的概率,BERT需要执行l个连续预测。如果长度l未知,我们可能需要枚举所有可能的长度,因为BERT需要根据长度改变[MASK]令牌的数量。
与XLNet比较(Yang et al ., 2019)。
GLM和XLNet都是用自回归目标进行预训练的,但是它们之间有两个不同之处。首先,XLNet使用损坏前的原始位置编码。在推理过程中,我们需要知道或列举答案的长度,这与BERT的问题相同。其次,XLNet使用两流自关注机制(而不是右移)来避免Transformer中的信息泄漏。它使预训练的时间成本增加了一倍。
与T5的比较(rafael et al, 2020)。T5提出了一个类似的空白填充目标来预训练编码器-解码器变压器。T5对编码器和解码器使用独立的位置编码,并依赖于多个哨兵标记来区分屏蔽跨度。在下游任务中,只使用一个哨兵令牌,导致模型容量的浪费以及预训练和调优之间的不一致。此外,T5总是以固定的从左到右的顺序预测跨度。
因此,GLM在参数和数据较少的NLU和seq2seq任务上的表现明显优于T5,如3.2节和3.3节所述。
与UniLM的比较(Dong et al ., 2019)。
UniLM通过改变双向、单向和交叉注意的注意掩膜,在自动编码框架下组合不同的预训练目标。然而,UniLM总是用[MASK]令牌替换掩码跨度,这限制了它对掩码跨度及其上下文之间的依赖关系进行建模的能力。GLM输入前一个令牌,并自动回归地生成下一个令牌。在下游生成任务上对UniLM进行微调也依赖于掩码语言建模,这种建模效率较低。UniLMv2 (Bao et al ., 2020)对生成任务采用部分自回归建模,对NLU任务采用自编码目标。相反,GLM通过自回归预训练将NLU和生成任务统一起来。
3实验
现在我们描述我们的预训练设置和下游任务的评估。
3.1预训练设置
为了与BERT (Devlin等人,2019)进行公平的比较,我们使用BooksCorpus (Zhu等人,2015)和英文维基百科作为我们的预训练数据。我们使用BERT的无大小写词块标记器,词汇量为30k。我们使用与BERTBase和BERTLarge相同的架构训练GLMBase和GLMLarge,分别包含110M和340M参数。
对于多任务预训练,我们训练了两个包含空白填充目标和文档级或句子级目标的大型模型,分别表示为GLMDoc和GLMSent。
此外,我们用文档级多任务预训练训练了两个更大的GLM模型,即410M(30层,隐藏大小1024,16个注意头)和515M(30层,隐藏大小1152,18个注意头)参数,分别记为GLM410M和GLM515M。
为了与SOTA模型进行比较,我们还训练了一个与RoBERTa具有相同数据、标记化和超参数的large -size模型(Liu et al ., 2019),记为GLMRoBERTa。由于资源限制,我们只对模型进行了25万步的预训练,这是RoBERTa和BART训练步骤的一半,训练令牌的数量接近T5。更多的实验细节可以在附录A中找到
3.2SuperGLUE
为了评估我们预训练的GLM模型,我们在SuperGLUE基准上进行了实验(Wang et al ., 2019),并报告了标准指标。SuperGLUE由8个具有挑战性的NLU任务组成。我们根据PET (Schick and sch tze, 2020b),将分类任务重新制定为人工制作的填空问题。
然后,我们对每个任务的预训练GLM模型进行微调,如第2.3节所述。填空题和其他细节可在附录B.1中找到。
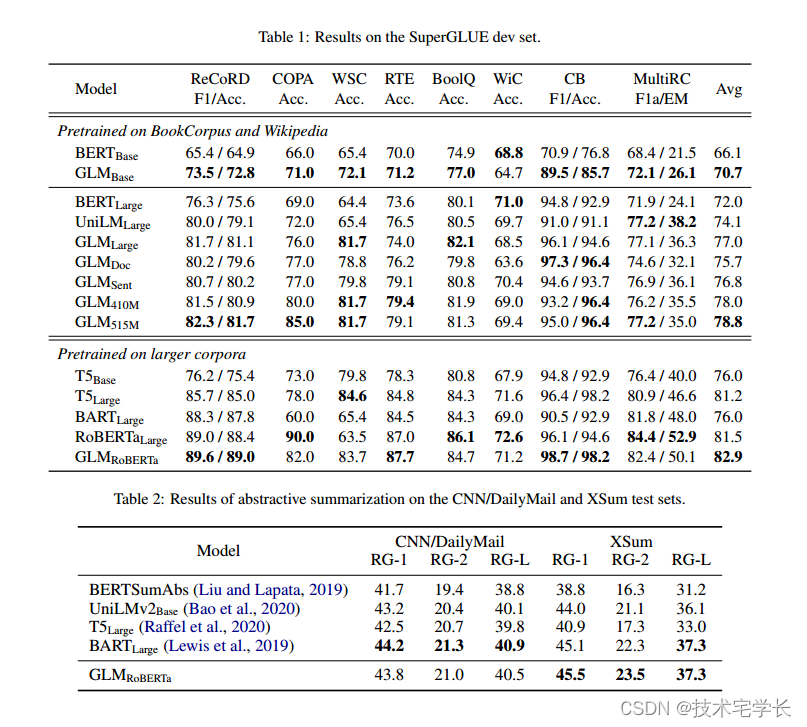
为了与GLMBase和GLMLarge进行公平的比较,我们选择BERTBase和BERTLarge作为我们的基线,它们在相同的语料库上进行了相似的时间预训练。我们报告了标准调优的性能(即对[CLS]令牌表示的分类)。BERT在完形填空题中的表现见章节3.4。为了与GLMRoBERTa进行比较,我们选择T5, BARTLarge和RoBERTaLarge作为我们的基线。T5在BERTLarge的参数数量上没有直接匹配,所以我们同时给出了T5Base (220M参数)和T5Large (770M参数)的结果。所有其他基线的大小与BERTLarge相似。
表1显示了结果。在训练数据量相同的情况下,GLM在基本架构或大型架构的大多数任务上始终优于BERT。唯一的例外是WiC(词义消歧)。GLMBase的平均得分比BERTBase高4.6%,GLMLarge的平均得分比BERTLarge高5.0%。它清楚地表明了我们的方法在NLU任务中的优势。在robertalage的设置中,GLMRoBERTa仍然可以在基线上实现改进,但边际较小。具体来说,GLMRoBERTa的性能优于T5Large,但尺寸只有T5Large的一半。我们还发现BART在具有挑战性的SuperGLUE基准测试中表现不佳。我们推测这可能归因于编码器-解码器结构的低参数效率和序列对序列的去噪目标。
3.3多任务预训练
然后我们在多任务设置中评估GLM的性能(第2.1节)。在一个训练批中,我们以相同的机会对短跨度和长跨度(文档级或句子级)进行采样。我们评估了NLU、seq2seq、空白填充和零射击语言建模的多任务模型。
超强力胶水。对于NLU任务,我们在SuperGLUE基准上评估模型。结果如表1所示。我们观察到,在多任务预训练中,GLMDoc和GLMSent的性能略差于GLMLarge,但仍然优于BERTLarge和UniLMLarge。在多任务模型中,GLMSent比GLMDoc平均高出1.1%。将GLMDoc的参数增加到410M (1.25×BERTLarge),性能优于GLMLarge。具有515M参数的GLM (1.5×BERTLarge)可以执行得更好。
Sequence-to-Sequence。考虑到可用的基线结果,我们使用Gigaword数据集(Rush等人,2015)进行抽象摘要,使用SQuAD 1.1数据集(Rajpurkar等人,2016)进行问题生成(Du等人,2017)作为在BookCorpus和Wikipedia上预训练的模型的基准。此外,我们使用CNN/DailyMail (See et al ., 2017)和XSum (Narayan et al ., 2018)数据集进行抽象总结,作为在更大语料库上预训练模型的基准。
在BookCorpus和Wikipedia上训练模型的结果如表3和表4所示。我们观察到GLMLarge在两代任务上可以达到与其他预训练模型相匹配的性能。GLMSent的性能优于GLMLarge,而GLMDoc的性能略差于GLMLarge。这表明教导模型扩展给定上下文的文档级目标对旨在从上下文中提取有用信息的条件生成的帮助较小。将GLMDoc的参数增加到410M,可以在这两个任务上获得最佳性能。在较大语料库上训练的模型结果如表2所示。GLMRoBERTa可以达到与seq2seq BART模型相匹配的性能,优于T5和UniLMv2。
填入文本。文本填充是预测与周围上下文一致的文本缺失范围的任务(Zhu等人,2019;Donahue et al, 2020;Shen et al ., 2020)。GLM训练了一个自回归的空白填充目标,因此可以直接解决这个问题。我们在Yahoo Answers数据集上评估了GLM (Yang et al ., 2017),并将其与空白语言模型(BLM) (Shen et al ., 2020)进行了比较,空白语言模型是专门为文本填充设计的模型。从表5的结果来看,GLM在很大程度上优于以前的方法(1.3到3.9 BLEU),并且在该数据集上达到了最先进的结果。我们注意到GLMDoc的性能略低于GLMLarge,这与我们在seq2seq实验中的观察结果一致。
语言建模。大多数语言建模数据集(如WikiText103)都是从维基百科文档构建的,我们的预训练数据集已经包含了维基百科文档。因此,我们在预训练数据集的一个持久化测试集上评估语言建模困惑度,该测试集包含大约2000万个令牌,表示为BookWiki。我们还在LAMBADA数据集上评估了GLM (Paperno et al ., 2016),该数据集测试了系统在文本中建模远程依赖关系的能力。任务是预测一篇文章的最后一个单词。作为基线,我们训练了一个GPTLarge模型(Radford等人,2018b;Brown et al, 2020)使用与GLMLarge相同的数据和标记化。
结果如图4所示。所有模型都在零射击设置下进行了评估。由于GLM学习了双向注意,我们也在语境被双向注意编码的情况下评估了GLM。在预训练过程中如果没有生成目标,GLMLarge将无法完成语言建模任务,其perplexity大于100。在参数数量相同的情况下,GLMDoc的性能比GPTLarge差。这是预期的,因为GLMDoc也优化了空白填充目标。将模型参数增加到410M (GPTLarge的1.25倍),性能接近GPTLarge。
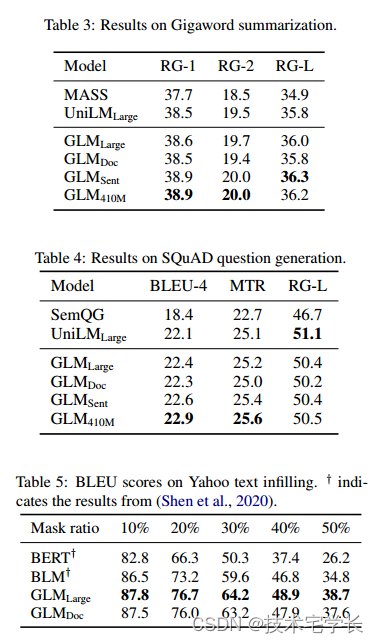
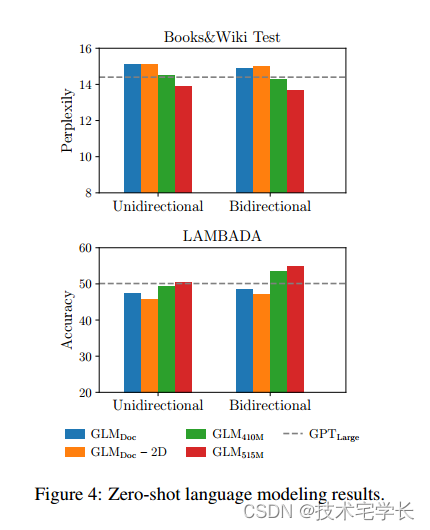
GLM515M (GPTLarge的1.5倍)可以进一步优于GPTLarge。在参数数量相同的情况下,对上下文进行双向注意编码可以提高语言建模的性能。在此设置下,GLM410M优于GPTLarge。这是GLM相对于单向GPT的优势。我们还研究了二维位置编码对长文本生成的贡献。我们发现,去除二维位置编码会导致语言建模精度降低和复杂度增加。
总结。最重要的是,我们得出结论,GLM有效地在自然语言理解和生成任务之间共享模型参数,比独立的BERT、编码器-解码器或GPT模型获得更好的性能。
3.4消融研究
表6显示了我们对GLM的消融分析。
首先,为了与BERT进行苹果与苹果的比较,我们用我们的实现、数据和超参数(第2行)训练了一个BERTLarge模型。
性能比官方BERTLarge略差,比GLMLarge差得多。
这证实了GLM在NLU任务上优于掩膜LM预训练的优越性。其次,我们展示了作为序列分类器(第5行)和封闭式微调的BERT的SuperGLUE性能(第3行)。与封闭式微调的BERT相比,GLM受益于自回归预训练。特别是在ReCoRD和WSC中,其中语言表达器由多个令牌组成,GLM的性能始终优于BERT。
这证明了GLM在处理变长空白方面的优势。另一个观察结果是,完形填空公式对GLM在NLU任务上的表现至关重要。对于大型模型,cloclostyle微调可以提高7个点的性能。最后,我们比较了不同预训练设计的GLM变体,以了解它们的重要性。第6行显示,删除跨度变换(总是从左到右预测掩码跨度)会导致SuperGLUE的性能严重下降。第7行使用不同的哨兵令牌而不是单一的[MASK]令牌来表示不同的掩码跨度。该模型的性能比标准GLM差。我们假设它浪费了一些建模能力来学习下游任务中不使用的不同哨兵令牌,只有一个空白。在图4中,我们展示了删除二维位置编码的第二维会损害长文本生成的性能。
我们注意到T5是用类似的空白填充目标进行预训练的。GLM在三个方面有所不同:(1)GLM由单个编码器组成,(2)GLM对掩码跨度进行洗牌,(3)GLM使用单个[MASK]而不是多个哨兵令牌。
虽然由于训练数据和参数数量的差异,我们无法直接将GLM与T5进行比较,但表1和表6的结果已经证明了GLM的优势。
4相关工作
Blank Language Modeling.预训练语言模型。预训练大规模语言模型可以显著提高下游任务的性能。有三种类型的预训练模型。首先,自动编码模型通过去噪目标来学习用于自然语言理解的双向上下文化编码器(Devlin等人,2019;Joshi et al, 2020;Yang等人,2019;Liu et al ., 2019;Lan等,2020;Clark et al, 2020)。其次,用从左到右的语言建模目标训练自回归模型(Radford et al ., 2018a,b;Brown et al, 2020)。第三,对编码器-解码器模型进行序列到序列任务的预训练(Song等人,2019;Lewis等人,2019;Bi et al, 2020;Zhang et al, 2020)。
在编码器-解码器模型中,BART (Lewis et al ., 2019)通过向编码器和解码器提供相同的输入并获取解码器的最终隐藏状态来执行NLU任务。相反,T5 (rafael et al, 2020)在文本到文本框架中制定了大多数语言任务。然而,这两种模型都需要更多的参数来优于RoBERTa等自动编码模型(Liu et al ., 2019)。UniLM (Dong et al ., 2019);Bao et al ., 2020)在具有不同注意掩模的掩模语言建模目标下统一了三种预训练模型。
NLU as Generation 。以前,预训练的语言模型在学习到的表示上使用线性分类器完成NLU的分类任务。GPT-2 (Radford等人,2018b)和GPT-3 (Brown等人,2020)表明,生成语言模型可以通过直接预测正确答案来完成NLU任务,如问答,而无需进行微调,给定任务指令或一些标记示例。然而,由于单向注意力的限制,生成模型需要更多的参数来工作。最近,PET (Schick and sch tze, 2020a,b)提出将输入样例重新制定为在few-shot设置中具有类似于预训练语料库模式的完形问题。研究表明,结合基于梯度的微调,PET可以在少量射击设置中获得比GPT-3更好的性能,而只需要GPT-3 0.1%的参数。类似地,Athiwaratkun等人(2020)和Paolini等人(2020)将结构化预测任务(如序列标记和关系提取)转换为序列生成任务。
Blank Language Modeling.空白语言建模。Donahue等人(2020)和Shen et al .(2020)也研究了落料填充模型。与他们的工作不同,我们以空白填充为目标预训练语言模型,并评估其在下游NLU和生成任务中的表现。
5结论
GLM是一种用于自然语言理解和生成的通用预训练框架。我们表明,NLU任务可以表述为条件生成任务,因此可以通过自回归模型求解。GLM将不同任务的预训练目标统一为自回归的空白填充,混合注意掩模和新颖的二维位置编码。我们的经验表明,GLM在NLU任务上优于以前的方法,并且可以有效地共享不同任务的参数。
A 预训练设置
A.1数据集训练
GLMBase和GLMLarge,我们使用BookCorpus (Zhu et al ., 2015)和BERT使用的Wikipedia (Devlin et al ., 2019)。
为了训练GLMRoBERTa,我们遵循RoBERTa的预训练数据集(Liu等人,2019),其中包括BookCorups (Zhu等人,2015)、维基百科(16GB)、CC-News (CommonCrawl新闻数据的英文部分,76GB)、OpenWebText(从Reddit上共享的url中提取的网页内容,至少有三个点对(Gokaslan和Cohen, 2019), 38GB)和Stories(过滤后的CommonCrawl数据子集,以匹配Winograd模式的故事风格(Trinh和Le, 2019), 31GB)。
Stories数据集不再是公开可用的4。
因此,我们删除Stories数据集并用OpenWebText25 (66GB)替换OpenWebText。
CC-News数据集不公开,我们使用(Mackenzie et al, 2020)发布的CC-News-en。所有数据集总共使用了158GB的未压缩文本,与RoBERTa的160GB数据集的大小接近。
3https://commoncrawl.org/2016/10/news-dataset-available
4https://github.com/tensorflow/models/tree/archive/research/lm_commonsense#1-download-data-files
5https://openwebtext2.readthedocs.io/en/latest
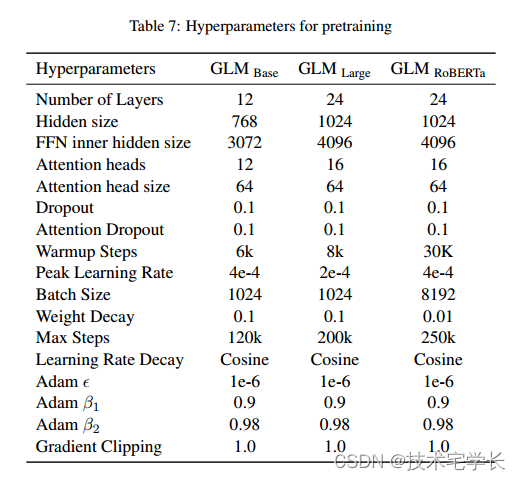
A.2 Hyperparameters
GLMBase和GLMLarge的超参数与BERT使用的超参数类似。为了权衡训练速度和与BERT(批大小256和1,000,000训练步)的公平比较,我们对GLMLarge使用批大小1024和200,000训练步。由于GLMBase更小,我们将训练步数减少到120,000步,以加快预训练。GLMDoc和GLMSent的超参数与GLMLarge的超参数相同。GLM410M和GLM515M的超参数除Transformer架构外,其余参数与GLMLarge相同。模型在64个V100 gpu上训练200K步,批大小为1024,最大序列长度为512,GLMLarge大约需要2.5天。
为了训练GLMRoBERTa,我们遵循RoBERTa的大部分超参数。
主要区别包括:(1)由于资源限制,我们只预训练了25万步的GLM RoBERTa,这是RoBERTa和BART训练步骤的一半,训练的token数量接近T5。(2)我们使用余弦衰减代替线性衰减来进行学习率调度(3)我们还应用了值为1.0的梯度裁剪。
表7总结了所有预训练设置的超参数。
A.3 Implementation
我们的预训练实现基于Megatron-LM (Shoeybi等人,2019)和DeepSpeed (Rasley等人,2020)。我们在补充材料中包含了我们的代码。由于补充材料的大小限制,我们不能包括预训练的模型,但会在未来公开。
B Downstream Tasks
B.1 SuperGLUE
SuperGLUE基准测试由8个NLU任务组成。我们将其制定为空白填充任务,如下(Schick and sch, 2020b)。表8显示了我们在实验中使用的完形填空问题和语言表达器。对于3个任务(ReCoRD、COPA和WSC),答案可能由多个令牌组成,而对于其他5个任务,答案始终是单个令牌。
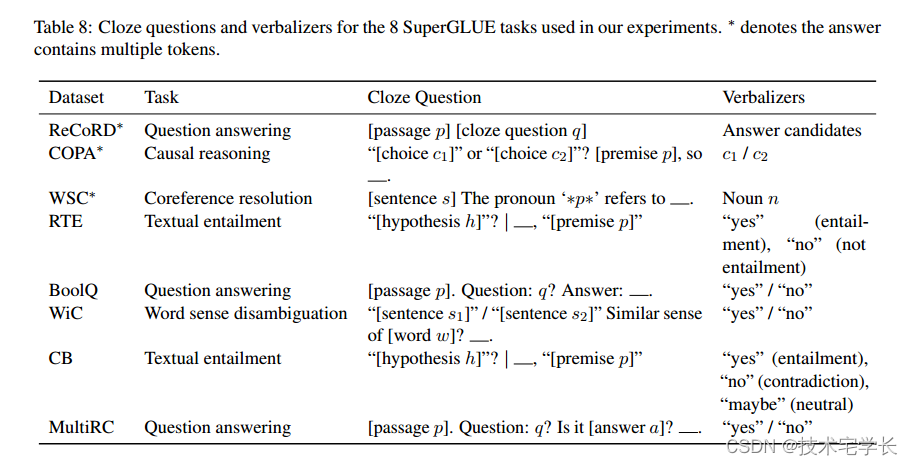
在SuperGLUE任务上调优GLM时,我们使用表8中的完形填空问题构造输入,并用[MASK]令牌替换空白。然后我们计算生成每个候选答案的分数。对于5个单令牌任务,分数被定义为语言化令牌的logit。对于3个多令牌任务,我们使用了言语器令牌的对数概率之和。由于我们提出的自回归空白填充机制,我们可以一次获得所有的对数概率。然后利用真值标签计算交叉熵损失,并更新模型参数。
对于基线分类器,我们遵循标准实践,将每个任务的输入部分(例如文本隐含的前提和假设,或者ReCORD和MultiRC的段落、问题和答案)连接起来,并在[CLS]令牌表示的顶部添加一个分类层。我们还对其他预训练模型实现了封闭型微调,但性能通常与标准分类器相似,正如我们在消融研究中所示。具有空白填充目标的模型,如T5和我们的GLM,从将NLU任务转换为填空题中获益更多。因此,对于T5和GLM,我们在主要结果中报告了这种转换后的性能。
B.2 Sequence-to-Sequence
对于文本摘要任务,我们使用数据集Gigaword (Rush et al ., 2015)进行模型微调和评估。我们使用AdamW优化器在训练集上对GLMLARGE进行了4个epoch的微调。
学习率的峰值为3e-5,热身超过6%的训练步骤,呈线性衰减。
我们还使用速率为0.1的标签平滑(Pereyra等人,2017)。文档最大长度为192,摘要最大长度为32。在解码过程中,我们使用波束大小为5的波束搜索,去除重复的三元组。我们调整开发集的长度惩罚值。评价指标为Rouge-1、Rouge-2和Rouge-L (Lin, 2004)在测试集上的F1分数。
对于问题生成任务,我们使用SQuAD 1.1数据集(Rajpurkar等人,2016),并遵循(Du等人,2017)的数据集分割。优化器的超参数与抽象摘要的超参数相同。最大文章长度为464,最大问题长度为48。在解码过程中,我们使用波束大小为5的波束搜索,并调整开发集的长度惩罚值。评价指标为BLEU-1、BLEU-2、BLEU-3、BLEU4 (Papineni et al ., 2002)、METEOR (Denkowski and Lavie, 2014)和Rouge-L (Lin, 2004)的得分。
T5Large在XSum上的结果是通过运行Huggingface transformers6提供的汇总脚本得到的。seq2seq任务上基线的其他结果均来源于相应的论文。
B.3 Text Infilling
我们跟踪(Shen et al ., 2020)并评估Yahoo Answers数据集(Yang et al ., 2017)上的文本填充性能,该数据集分别包含100K/10K/10K文档,用于训练/有效/测试。文档的平均长度是78个单词。为了构建文本填充任务,我们随机屏蔽每个文档标记的给定比例r 2 × 10%···50%g,并将相邻的被屏蔽标记折叠成单个空白。我们在训练集上对GLMLarge进行了5个epoch的动态屏蔽微调,即。
在训练时随机生成空白。
与序列对序列的实验类似,我们使用峰值学习率为1e-5的AdamW优化器和6%的预热线性调度器。
为了与之前的工作进行比较,我们使用了(Shen et al ., 2020)构建的相同测试集。
评估指标是填充文本相对于原始文档的BLEU分数。我们比较了两个基线:(1)BERT,它学习了一个从左到右的语言模型,在空白表示的基础上生成掩码标记;(2)由(Shen等人,2020)提出的BLM,它可以用任意轨迹填充空白。
B.4 Language Modeling
我们评估了该模型在BookWiki上的语言建模能力和在LAMBDA数据集上的准确性(Paperno et al, 2016)。
困惑度是语言建模中一个被广泛研究的评价标准。Perplexity是语料库平均交叉熵的指数。
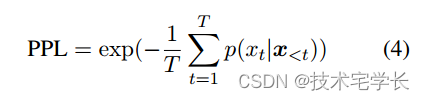
其中x < t =[x0;;XT 1]。由于transformers只能在固定输入大小w的窗口上工作,因此我们无法完全计算p(XT jxt w:t1).即使为每个标记计算这个值也是非常昂贵的,因为我们需要对w大小的上下文进行T评估。为了提高评估效率,我们采用重叠评估,其中我们每次将滑动窗口推进一些重叠o,并且只计算窗口的最后o个标记的交叉熵损失。在我们的实验中,我们为所有模型设置o = 256。
LAMBDA是一个封闭型数据集,用于测试远程依赖关系建模的能力。每个例子是一篇由4-5个句子组成的文章,其中最后一个单词缺失,模型需要预测文章的最后一个单词。由于我们使用WordPiece标记化,一个词可以分成几个子词单位。我们使用教师强制,只有当所有预测的标记都正确时,我们才认为预测是正确的。
C Results on Other NLU Benchmarks
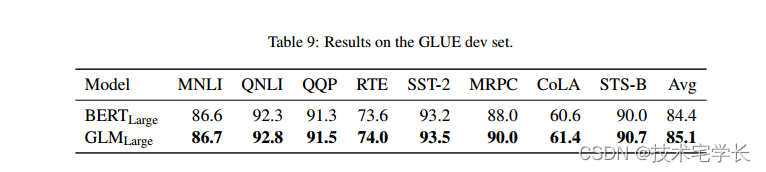
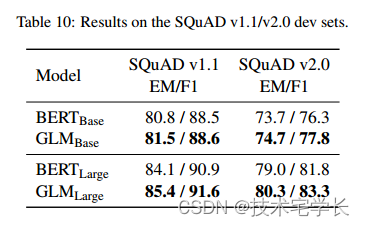
GLUE(Wang等人,2018)是另一个广泛使用的NLU基准,包括单句任务(例如情感分析(Socher等人,2013))和句子对任务(例如文本相似性(Cer等人,2017)和自然语言推理(Williams等人,2018;Dagan等人,2005年))。这一基准通常被认为没有强力胶那么具有挑战性。Team(Rajpurkar等人,2016,2018)是一个摘录的问题回答基准。我们进一步比较了GLM和BERT在这两个基准上的差异。
在GLUE和LAND上的结果显示在表9和表10中。在这两个基准上,GLM仍然可以在相同的参数数量下超过BERT,但差距较小。
D Text Generation Samples
我们展示了GLMDoc生成的文本,给定了从测试集中随机抽样的未知上下文。我们使用k=40的top-k随机抽样来生成,并将最大序列长度设置为512。一些文本被删节了(Some of the texts are cut short.)。
示例D.1。怀俄明州议会是美国怀俄明州的立法机构。
GLM:它由州参议院和众议院组成。截至2019年,州参议员是史蒂夫·基什、乔·L·威廉姆斯和琳达·S·博伦斯。
怀俄明州立法机构的成员是从代表该州多数地区的单一成员选区选举产生的。现任州参议院成员是:近年来,参议院发生了四次变化。最近的一次是创建了一个有六个席位的选区,其中包括以下全部或部分内容:在2009年的选举中,州参议院议员当选,任期六年。目前的州众议院成员是:怀俄明州宪法将某些权力分配给州长。
最值得注意的是,州长是参议院主席和州长。然而,如果州长希望任命一名成员进入怀俄明州参议院,法律授权州长这样做。怀俄明州州长没有立法权,但有权否决议员,这并不局限于对法律的否决。根据怀俄明州宪法,州长可以否决怀俄明州众议院其他成员的行动。州长还可以任命怀俄明州参议院的成员。此外,州长还可以任命怀俄明州众议院的成员。怀俄明州宪法规定,州长可以任命怀俄明州参议院成员进入怀俄明州最高法院,并任命怀俄明州参议院主席
示例D.2。乔纳森·特里是一名电视和电影演员
GLM:他是《X战警》系列动画片的配音演员,也是《辛普森一家》和《超人奇遇记》的配音演员。他还为《科拉传奇》中的角色配音,他曾在几部电视连续剧中亮相,包括饰演比利·希格尔迪猪船长的《辛普森一家》、《x档案》、《英雄》和《辛普森一家电影》,以及网络连续剧《克拉斯蒂·奥秘》饰演特伦格斯上校。他为《卫报》撰稿。
乔纳森·特里出生在伦敦。特里在英国萨里长大,就读于英国苏塞克斯大学,毕业时获得了英国文学学位。他是伦敦国王学院的客座讲师,然后在英国表演学院学习了两年的表演课程,为他未来在娱乐业的职业生涯做准备。特里最初在电视剧《辛普森一家》中饰演船长比利·希格勒迪皮格,但他的角色只是该剧前六季中的一个反复出现的角色。后来,他作为常客出现在该剧的最后六季中,此后一直是该剧的常客。
他在《宠物的秘密生活》的前几集中饰演少校杰克·瑞安。他还作为配角出现在几集的《宠物的秘密生活》中。自《辛普森一家大电影》以来,他一直在电视剧《辛普森一家》中工作,最著名的角色是饰演骷髅船长和同名幽灵。他在几部电影中扮演角色,包括“\”、“\”、“\”和“\”。
他曾在1993年的《杀人犯》、1995年的《伪装者》以及电视节目《王室成员》和《账单》中亮相。


















 3418
3418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











