






文章目录
以下链接包含本文相关资源:
。需要文件可发邮件到3307320866@qq.com
完整报告链接:https://download.csdn.net/download/m0_48932261/89432061
数据集下载链接:https://download.csdn.net/download/m0_48932261/89421590?spm=1001.2014.3001.5501
摘要
家庭暴力在现今社会屡见不鲜,成为威胁社会和谐与稳定的重要问题之一。家庭暴力不仅包括身体上的虐待,还涉及情感、心理和经济上的虐待,给受害者尤其是女性和儿童带来深远的负面影响。有效预防和处理家庭暴力事件,及时感知和理解伴侣的情感显得尤为重要。为了帮助社会稳定,提高居民生活幸福指数,本系统选取了CMU-MOSI、IEMOCAP数据集,利用Transformer、Adam优化器等多种深度学习算法,构建起情感检测系统。用户可以将信息输入到情感检测系统中,系统能够帮助识别检测对象的情感状态,提供预警,保护受害者的权益,并避免矛盾的进一步激化。本系统选取了MOSi、IEMOCAP数据集,并利用transformer技术构建了一个情绪检测系统。MOSi、IEMOCAP数据集是一个多模态情感分析数据集,包含视频、音频和文本三种模式的数据,非常适合用于情感分析和情绪检测研究。其多样性和丰富性,使其成为情感检测系统开发的理想选择。通过构建和应用情感检测系统,可以在家庭暴力问题发生前提供预警,减少暴力事件的发生频率和严重程度。该系统不仅有助于保护受害者的权益,改善家庭关系,还有助于构建一个更加和谐和安全的社会环境。利用MOSi、IEMOCAP数据集和transformer技术构建情感检测系统,是应对家庭暴力问题的一项重要创新和实践,能够在保护家庭暴力受害者、预防暴力事件方面发挥重要作用,推动社会和谐和进步。
第一章 背景与意义
1.1 背景
家庭暴力是一个普遍存在的社会问题,它不仅侵蚀着个体的尊严和权利,也对社会的道德和法律秩序构成挑战。深入了解家庭暴力的发展现状、认识其严重危害,并明确预防和干预项目的意义与目的,对于构建和谐社会至关重要。
1.1.1 家庭暴力发展现状
家庭暴力作为一种严重的社会问题,其发生率在全球范围内一直居高不下。尽管各国政府、国际组织和民间社会已经采取了包括立法、教育、公共宣传和支持服务在内的多种措施来应对和减少家庭暴力事件,但这一问题仍然普遍存在。家庭暴力的隐蔽性和复杂性,加之受文化、宗教和社会观念的影响,使得许多案例难以被及时发现和处理,从而成为一个难以根除的社会顽疾。
1.1.2 家庭暴力的危害
家庭暴力的危害性是广泛而深远的,它的影响不仅限于受害者个体,还会波及整个家庭系统,乃至更广泛的社会层面。受害者遭受的身体伤害往往是显而易见的,但家庭暴力所带来的心理创伤却可能是隐蔽而持久的。受害者可能会经历深刻的心理痛苦,包括羞耻、内疚、无助感和持续的恐惧,这些感受可能会长期影响他们的心理健康和社会功能。
1.2 意义与目的
本项目通过构建和应用情感检测系统,旨在成为预防家庭暴力的第一道防线。该系统利用MOSi、IEMOCAP数据集和前沿的Transformer技术,能够深入分析家庭成员的情感状态,及时捕捉到潜在的冲突信号。通过提前预警,我们不仅可以减少家庭暴力的发生频率,还能降低其严重程度,从而避免对受害者造成不可逆转的伤害。本项目的意义不仅在于技术层面的创新,更在于它对促进社会正义、保护人权、维护社会秩序的深远影响。通过这一系统,我们期望能够为每一个家庭带来和平与安宁,为社会带来和谐与进步。
第二章 关键技术与方法
2.1 文本模态特征提取法
BERT(Bidirectional Encoder Representations from Transformers)是由Google在2018年提出的一种预训练语言模型,它在自然语言处理(NLP)任务中取得了显著的成果。
2.2 视频模态特征提取法
OpenFace 2.0 由卡内基梅隆大学开发的先进开源工具包,专门用于面部行为分析。OpenFace 2.0集成了一系列尖端功能,包括高精度面部标记点检测、实时头部姿态估计、面部动作单元识别,以及眼动估计。
2.3 音频模态特征提取法
Librosa是一个专为音乐和音频分析设计的Python库,它为音乐信息检索(MIR)领域提供了一套全面而强大的工具集。
2.4 注意力机制(Attention)
注意力机制是深度学习中模拟人类选择性关注的一种技术,它允许模型在处理序列数据时,动态地聚焦于输入中最为相关的部分。这种机制首次在神经机器翻译中得到应用,并迅速成为自然语言处理及其他领域的核心技术。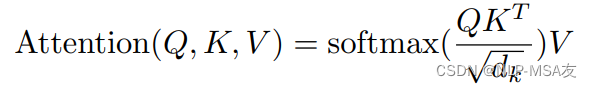
其中,Q、K、V代表模态输入,dk代表问题规模。具体的点积操作如下图结构图所示:
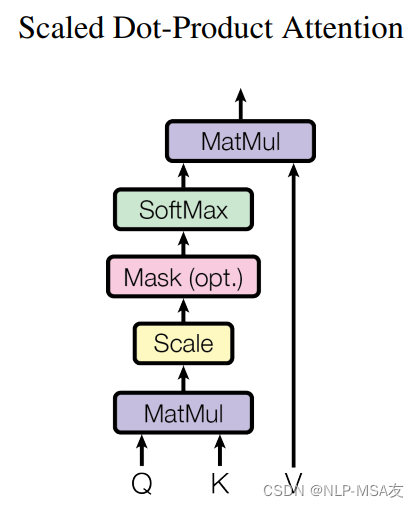
2.5 多头注意力机制(Multi-Attention)
多头注意力机制是深度学习领域中一种创新且强大的技术,尤其在变换器(Transformer)模型架构中发挥着核心作用。这种机制的先进之处在于其能够并行地处理信息的多个子空间表示,从而在不同层面上捕捉输入数据的丰富特征。

其中Concat代表拼接操作,W是可学习的权重,i表示第i个头(多层注意力机制中的第i层)。网络结构图如下图所示。
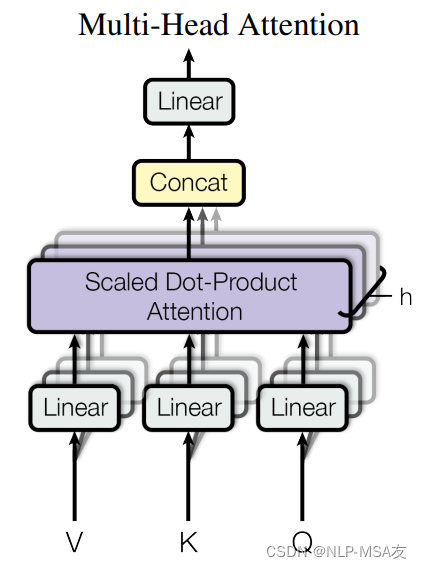
2.6 Transformer
Transformer是一种革命性的神经网络架构,它在自然语言处理(NLP)领域引发了一场变革。这种模型完全基于注意力机制,摒弃了传统的循环神经网络(RNN)结构,使得模型能够并行处理序列数据,极大地提高了训练效率。Transformer的网络结构如下图所示:
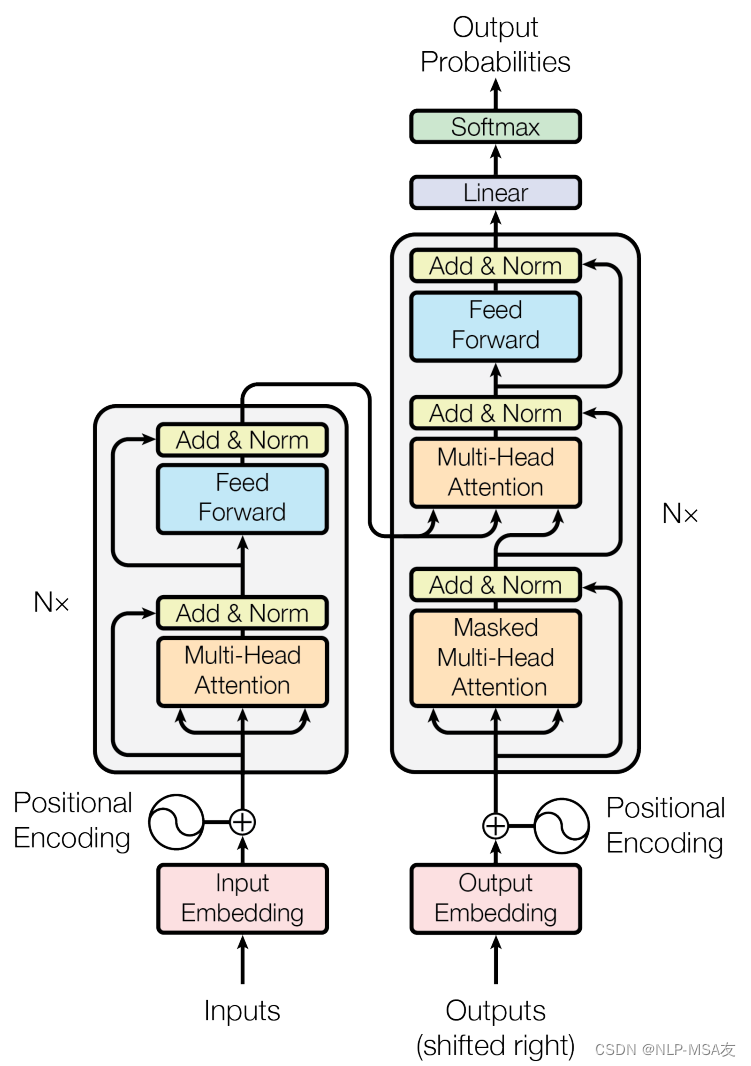
第三章 系统的设计与实现
在本次系统开发过程中,首先的关键步骤是获取源数据集。本文对数据集进行深入分析,并执行特征提取,以确保数据的完整性和一致性。数据处理阶段完成后,本文转向PyCharm集成开发环境,开始设计机器学习算法模型。通过利用处理后的数据集对模型进行系统训练,本文进一步通过一系列测试来评估不同模型的性能。经过细致的比较和验证,本文最终选定了表现最佳的模型,并将其应用于实际使用场景,以确保系统能够提供高效、准确的解决方案。
3.1 文本特征提取
采用预训练的bert模型对输入的文本进行特征提取,将特征变成向量表示。首先导入一些必要的三方库,BertTokenizer 和 BertModel 是使用 Hugging Face 的 transformers 库中的类,它们分别用于BERT模型的文本分词和模型加载。随后, 设计一个文本编码函数TextEmbedding(tokenizer, model, text),它负责将输入文本转换为BERT模型的嵌入表示,这一过程对于后续的自然语言处理任务至关重要。代码实现如下:
3.2 音频特征提取
本文使用Librosa进行音频特征的提取,方法流程是遍历指定文件夹内的所有音频文件,从中提取有用的音频特征,并最终将这些特征保存到一个字典中,以便于后续的分析和处理。
之后,在循环中,对于每个文件,本文使用 librosa.load 函数加载音频数据并提取了以下音频特征:过零率(zero_crossing_rate),反映了信号在单位时间内过零的次数,是音频信号的一种基本特征。
3.3 视频特征提取
为了从视频文件中提取图像和音频特征,本文引入了CatchPIC_Audio_FromVideo_camera(filepath,savepath) 函数。
通过CatchPIC_Audio_FromVideo_camera(filepath,savepath) 函数,能够自动化地从视频文件中提取图像和音频特征,为进一步的分析和处理提供了便利。这一过程不仅提高了特征提取的效率,也保证了数据处理的一致性和准确性。
3.4 深度学习算法实现
深度学习算法的主要流程为特征编码、特征融合与结果预测。
3.4.1 特征编码
特征编码部分采用了深度学习中的多头注意力机制(Multihead Attention),以及随后的前馈网络(Feed-Forward Network),用于有效地处理视觉(visual)、音频(audio)和文本(text)三种不同类型的输入数据。
通过这种特征编码方法,我们能够为不同类型的输入数据生成丰富且具有区分性的特征表示,这对于后续的模型训练和预测任务至关重要。这种编码方式不仅提高了模型对数据的理解能力,也为处理多模态数据提供了一种有效的技术手段。
3.4.2 特征融合
在本项目的深度学习模型中,特征融合和模态间交互影响是通过精心设计的多头注意力机制和前馈网络来实现的。
这种设计允许模型在不同模态之间进行信息的整合和融合,通过多头注意力机制和前馈网络的结合,提高了模型对多模态数据的表达能力。
3.4.3 结果预测
为了指导模型训练,本文引入了决策融合方式。在多模态特征的解码阶段,我们使用SigmoidAtt函数对不同模态的特征编码进行解码,生成对应的输出。这些输出随后通过密集连接层和线性变换,生成最终的预测结果output_res_vv、output_res_aa和 output_res_tt。
通过这种设计,我们不仅能够训练模型以最小化预测误差,还能够通过正则化技术提高模型的泛化能力。这种综合的方法为多模态学习任务提供了一种有效的技术手段,有助于提高模型在复杂数据集上的性能。
3.5 深度学习算法训练
本文在训练深度学习模型的过程中,采用了一些核心的机器学习技术。首先,模型参数是通过Xavier初始化来设定的,这有助于在训练初期避免梯度消失或爆炸的问题。训练中使用的优化算法是Adam,它是一种非常流行的自适应学习率优化算法,能够根据参数的梯度自适应调整学习率。
损失函数的设计也很关键,自定义了一个损失函数来指导模型的训练。在每个训练周期,模型通过前向传播计算输出和损失,然后反向传播算法根据损失来更新模型的权重。
为了防止模型过拟合,本文还引入了L2正则化,这是一种常见的正则化技术,通过惩罚大的权重值来促使模型学习到更加简单的表示。此外,定期保存模型的检查点惯不仅有助于监控训练过程,还可以在模型出现意外时恢复到之前的状态。
3.6 深度学习算法性能测试
在本项目中,模型的评估和测试过程是通过一系列函数来实现的。evaluation 函数负责计算预测结果和真实标签的 F1 分数和准确率,这两个指标是衡量模型性能的关键。test 函数是测试过程中的核心,它首先加载数据集,然后定义了模型的 TensorFlow 变量作用域,并初始化了模型实例 mtest。随后加载之前训练过程中保存的最佳模型检查点。测试过程中,我们尝试恢复一系列定期保存的模型状态,并在每个模型状态上执行测试集的预测。
通过这种系统化的测试方法,我们能够全面评估模型的泛化能力,并确保所选模型在实际应用中的有效性和可靠性。
3.7 系统测试
在本系统开发中,我们实现了一个简洁直观的用户交互流程。用户仅需输入数字 “1” 即可轻松启动检测过程。一旦用户做出选择,系统便立即在后台激活算法模型,开始一系列复杂的训练和运算任务。这包括对数据集的预处理、特征的提取,以及模型的参数优化。

随着模型运算的完成,系统将对所有用户进行测试,并生成详细的测试报告。这份报告不仅展示了模型预测的结果,还与实际的真实结果进行了对比,以便进行准确评估。系统将自动计算并展示模型的准确率,这一指标反映了模型预测的准确性和可靠性。
在系统测试阶段,特别关注源数据集中的第一条数据。本文假设这是当前用户的有效数据,并将其作为模型初步测试和验证的基础。这种做法有助于快速评估模型对新数据的适应性和预测能力。其中数字与情感的对应关系如下:
emo_dict = {
'0': '快乐',
'1': '生气',
'2': '悲伤',
'3': '中性',
'4': '挫折',
'5': '兴奋',
'6': '惊讶'
}

整个过程的设计旨在确保用户能够轻松获取检测结果,同时对模型的性能有一个清晰的认识。这种透明度和即时反馈机制不仅增强了用户的信任感,也为系统开发者提供了宝贵的数据,以便进行持续的优化和改进。
第四章 总结
在本项目中,开发了一个深度学习模型,专注于家庭暴力背景下的情感分析。这个系统通过先进的技术手段,能够提前识别情感变化,帮助预防潜在的家庭冲突。我们利用了BERT等预训练语言模型来提取文本特征,并结合了多头注意力机制和Transformer架构的优势,以提高模型对情感状态的识别能力。项目的核心是一个情感检测系统,它能够分析家庭成员之间的交流信息,识别出潜在的负面情绪和冲突信号。系统通过实时监控和分析家庭内部的沟通模式,能够在家庭暴力问题发生前提供预警,帮助预防和减少暴力事件的发生。在开发过程中,使用了CMU-MOSI等多模态情感分析数据集进行训练和测试,这使得模型能够从文本中提取情感相关的特征,并对可能的情感冲突进行评估。此外,系统的用户界面设计简洁直观,确保了易用性和可访问性。
















 623
623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











