







文章目录
摘要
- 视觉SLAM技术具有成本低,安装简单的优点;
- 相较于激光SLAM,能获得环境中色彩和纹理信息 → \rightarrow → 提取更多特征,更好场景辨识
【本文内容】
(1)分析当前SLAM的研究现状;
(2)概述视觉SLAM的基本原理和方法;
(3)综述研究热点;
(4)视觉SLAM存在的问题和发展趋势;
关键词
- 移动机器人;
- 同时定位与建图;
- 视觉;
- 动态环境;
0 引言
目前 SLAM 技术研究主要集中于两种方法:一是基于便携式激光测距仪的方法,即激光SLAM;另一种是基于计算机视觉的方法,即视觉SLAM;
视觉SLAM:采用相机作为传感器代替激光雷达重构地图
视觉 SLAM 主要由特征提取、特征跟踪、运动跟踪、闭环检测、地图构建、位姿估计等部分组成。
1 视觉 SLAM 概述
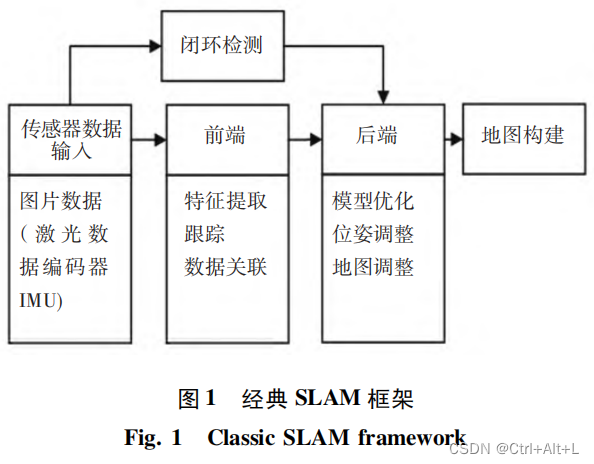
经典视觉 SLAM 框架通常包含传感器数据输入、前端(视觉预处理)、后端(算法)、地图构建以及闭环检测。
- 前端:特征提取、短期和长期数据关联和将几何信息转化为纯粹数学信息;
- 后端:优化、最小化相机姿态的累计误差和地图信息的优化调整;
- 闭环检测(回环检测):计算图像相似性,识别比对经过的场景,实现累计误差的消除;
根据视觉传感器的不同,视觉 SLAM 主要分为单目(单目相机)、RGB-D(单目相机和红外传感设备)、立体视觉 SLAM(不同方位安装多个相机) 等方法。
视觉传感器一般具有视觉里程测量功能,具有足够的稳定性和鲁棒性,而且易于实现。
1.1 经典 SLAM 方法
基于直接法的视觉SLAM;基于特征点法的视觉SLAM;
1.1.1 基于直接法的视觉 SLAM
| 名称 | 主要内容 | 特点 | 引文 |
|---|---|---|---|
| LSD-SLAM | 构建一个半稠密的全局稳定的环境地图,包含了更全面的环境表示,在 CPU 上实现了半稠密场景的重建。 | 该方法对相机内参敏感和曝光敏感;需要特征点进行回环检测;无法在照明不规律变化的场景中应用; | ENGEL J,SCHöPS T,CREMERS D. LSD-SLAM: Large-scale direct monocular SLAM[C]/ /European conference on computer vision. Springer,Cham,2014: 834-849 |
| DTAM | 采用直接稠密的方法,通过在相机视频流中提取多张静态场景图片来提高单个数据信息的准确性,从而实时生成精确的深度地图; | 计算复杂度大,需要GPU并行计算;对全局照明处理较差; | NEWCOMBE R A,LOVEGROVE S J,DAVISON A J. DTAM: Dense tracking and mapping in real-time [C] / / 2011 international conference on computer vision. IEEE,2011: 2320-2327. |
| SVO(Semi-direct Visual Odoemtry) | 半直接法的视觉里程计,特征点和直接法混合使用;舍弃了回环检测; | 时间复杂度较低;在位姿估计中会生成很大的累计误差,丢失位置后重建比较困难。 | FORSTER C,PIZZOLI M,SCARAMUZZA D. SVO: Fast semi -direct monocular visual odometry[C]/ /2014 IEEE international conference on robotics and automation (ICRA) . IEEE,2014: 15- 22. |
| DSO(Direct Sparse Odometry) | 基于高度精确的稀疏直接结构;法能够直接优化光度误差,考虑了光度标定模型,该方法不仅完善了直接法位姿估计的误差模型,还加入了仿射亮度变换、光度标定、深度优化等方法,在无特征的区域中也可以使其具有鲁棒性。 | 没有回环检测 | ENGEL J,KOLTUN V,CREMERS D. Direct sparse odometry [J]. IEEE transactions on pattern analysis and machine intelligence,2017,40( 3) : 611-625. |
1.1.2 基于特征点的视觉 SLAM
-
Davison 等人 ——> 单目SLAM方法(MonoSLAM) ——> 采用扩展卡尔曼滤波算法建立环境特征点地图 ——> 地图具有稀疏性:需要更多的特征来实现 ——> 出现了UKF方法和**改进UKF方法 **,解决视觉SLAM的线性不确定性。
-
Sim 等人 ——> 基于PF的单目SLAM ——> 可以构建更精确的地图映射 ——> 计算复杂度较高 ——> 无法在大型环境下应用。
-
Klein等人 ——> 基于关键帧的单目SLAM(PTAM) ——> 建图和跟踪并行化处理;关键帧提取技术,对数帧图像进行串联从而优化 ——> 减小了机器人定位中的不确定性(非线性优化代替EKF)——> 存在全局优化问题,无法在大型环境下应用。
-
Mur-Artal 等人 ——> (2015)基于特征法的单目SLAM(ORB-SLAM) ——> 实时估计3D位置特征和重建环境地图,良好的缩放和旋转不变性,较高的精度 ——> CPU高负担,生成仅用于构建的地图,无法用于导航和避障;
Mur-Artal 等人 ——> (2017)基于改进特征法的单目SLAM(ORB-SLAM2) ——> 增加了对RGB-D相机、深度相机和立体相机的支持 ——> 依赖大量数据集生成,耗时、易产生无效数据;缺乏离线可视化和轨迹建图能力。
2 视觉 SLAM 研究热点
2.1 视觉与惯性传感器融合的 SLAM
视觉前端:视觉传感器和IMU结合,获得更加丰富的信息;进而通过采集信息处理,从而进行估计。
IMU能给视觉里程计精准的定位;视觉信息定位来减小IMU零偏,减小发散和累计误差;
提高位姿估计输出频率、提高位姿估计的精度、提升整个系统的鲁棒性
应用场景:机器人、无人机、无人驾驶、AR 和 VR 等
| 方法 | 内容 | 特点 | 引文 |
|---|---|---|---|
| MSCKF | 将视觉和惯性信息在EKF下融合。 | 应用在运动剧烈、纹理的环境中;更好的鲁棒性;更高精度和速度,能在嵌入式平台上运行。 | HUANG G. Visual-inertial navigation: A concise review[C]/ / 2019 international conference on robotics and automation ( ICRA) . IEEE,2019: 9572-9582. |
| ROVIO | 紧耦合 VIO 系统;图像块滤波;利用EKF进行状态估计;FAST提取角点;图像块在视频的基础上获得了多层次的表达;利用 IMU 估计的位姿来计算特征投影后的光度误差; | 算法计算量小,但对应不同的设备需要调参数(参数对精度很重要) ,并且没有闭环,经常存在误差,会残留到下一时刻 | MOURIKIS A,ROUMELIOTIS S. A Multi - State Constraint Kalman Filter for Vision - aided Inertial Navigation [C]/ / Proceedings 2007 IEEE International Conference,2007: 3565 - 3572. |
| OKVIS | 使用非线性优化基于关键帧视觉SLAM技术。构成优化中重投影,预测 IMU 状态量和优化的参数之间构成 IMU 测量误差,两项误差放在一起做优化 | 不支持重定位,也没有闭环检测或校正方案 | LEUTENEGGER S,LYNEN S,BOSSE M,et al. Keyframe - based visual- inertial odometry using nonlinear optimization[J]. International Journal of Robotics Research,2015,34( 3) : 314 - 334. |
| VINS-Mono | 估计器初始化和故障恢复,采用基于单耦合、非线性优化的方法。通过融合预积分的 IMU 测量数据和特征观测数据获得高精度的视觉惯性里程计。 | 更加完善和鲁棒的初始化以及闭环检测过程 | TONG Q,PEILIANG L,SHAOJIE S. VINS -Mono: A Robust and Versatile Monocular Visual- Inertial State Estimator[J]. IEEE Transactions on Robotics,2017 ( 99) : 1-17. |
2.2 视觉与激光雷达融合的 SLAM
特点:激光雷达在建图和距离测量时准确度较好的优势
针对问题:单目尺度漂移、双目深度估计精度不高、户外 RGB-D 稠密重建困难
不足之处:标定和融合比较困难
视觉与激光雷达融合的 SLAM 主要分为: 改进的视觉 SLAM、改进的激光 SLAM 以及并行激光与视觉 SLAM。
| 名称 | 内容 | 特点 | 引文 |
|---|---|---|---|
| LiDAR - Monocular Visual Odometry,LIMO | 提取图片特征点的深度; | 不仅考虑局部平面假设的外点,并考虑了地面点。 | GRAETER J,WILCZYNSKI A,LAUER M. Limo: Lidar - monocular visual odometry[C]/ /Proceedings of the 2018 IEEE / RSJ International Conference on Intelligent Robots and Systems ( IROS) ,Madrid,Spain,2018: 7872-7879. |
| 基于单目相机直接法的视觉 SLAM 框架 | 滑动窗口追踪 + 集成了深度的帧与帧的匹配方法 | 许多像素缺失深度信息 | SHIN Y S,PARK Y S,KIM A. Direct visual slam using sparse depth for camera - lidar system[C]/ /2018 IEEE International Conference on Robotics and Automation ( ICRA) . IEEE,2018: 5144-5151. |
| De Silva 等人工作 | 计算两个传感器之间的几何变换后,采用高斯过程回归,对缺失值进行插值。 | 解决缺失深度信息问题 | DE SILVA V,ROCHE J,KONDOZ A. Fusion of LiDAR and camera sensor data for environment sensing in driverless vehicles [J]. arXiv Preprint arXiv: 1710.06230,2018 |
| Scherer 等人工作 | 采用激光雷达进行障碍物及边界检测 | 可能包含遮挡点,从而对精度有一定的影响 | SCHERER S,REHDER J,ACHAR S,et al. River mapping from a flying robot: state estimation,river detection,and obstacle mapping[J]. Autonomous Robots,2012,33( 1) : 189-214. |
| Huang 等人工作 | 基于直接法的 SLAM 方法,遮挡点检测器和共面点检测器 | 解决遮挡存在时精度的影响 | HUANG K,XIAO J,STACHNISS C. Accurate direct visual - laser odometry with explicit occlusion handling and plane detection [C]/ /2019 International Conference on Robotics and Automation ( ICRA) . IEEE,2019: 1295-1301. |
| Liang 等人工作 | 一种解决激光和相机传感器集成的大规模激光碰撞中的闭环问题 | 利用ORB 特征和词袋特征;环路检测的快速、鲁棒性 | LIANG X,CHEN H,LI Y,et al. Visual laser-SLAM in large- scale indoor environments [C ]/ /2016 IEEE International Conference on Robotics and Biomimetics ( ROBIO) . IEEE,2016: 19-24. |
| Zhu 等人工作 | 3D 激光 SLAM 和视觉关键帧词袋回环检测相融合,并对最近点迭代(ICP) 进行优化 | None | ZHU Z,YANG S,DAI H,et al. Loop detection and correction of 3d laser-based slam with visual information[C]/ /Proceedings of the 31st International Conference on Computer Animation and Social Agents. 2018: 53-58. |
| Pandey 等人工作 | 利用 3D 点云与可用相机图像的共配准,将高尺度特征描述符( 如尺度不变特征变换(SIFT) 或加速鲁棒特征(SURF) ) 与 3D 点相关联 | 利用视觉信息对刚性转换做了预测,并且建立通用的 ICP 框架。 | PANDEY G,SAVARESE S,MCBRIDE J R,et al. Visually bootstrapped generalized ICP [C]/ /2011 IEEE International Conference on Robotics and Automation. IEEE,2011: 2660 - 2667. |
| Seo 等人工作 | 同时采用激光雷达和视觉传感器并行构建了两个地图: 激光雷达立体像素地图和具有地图点的视觉地图,并在后端优化中运用残差对里程求解,使其保持全局一致 | 更好的进行状态估计,是一种紧耦合的方法 | SEO Y, CHOU C C. A tight coupling of vision - lidar measurements for an effective odometry [C]/ /2019 IEEE Intelligent Vehicles Symposium ( IV) . IEEE,2019: 1118-1123. |
| Zhang 等人工作 | 一种视觉雷达里程计的通用框架 | 高频视觉里程计估计运动,低频雷达细化运动估计 | ZHANG J,SINGH S. Visual-lidar odometry and mapping: Low- drift,robust,and fast[C]/ /2015 IEEE International Conference on Robotics and Automation ( ICRA) . IEEE,2015: 2174-2181. |
2.3 基于深度学习的视觉 SLAM
- 使用深度神经网络对单目视觉深度进行估计;
- 将深度学习与视觉 SLAM 前端结合,从而提高图像特征提取的准确度;
- 融入物体识别、目标检测、语音分割等技术,进而增加对周围环境信息的感知与理解;
| 名称 | 内容 | 特点 | 引文 |
|---|---|---|---|
| Zhou 等人工作 | 一种单目深度和位姿估计的无监督学习网络 | 完全无监督网络;得到的深度和位姿缺乏系统尺度; | ZHOU T,BROWN M,SNAVELY N,et al. Unsupervised learning of depth and ego-motion from video[C]/ /Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1851-1858. |
| Godard 等人工作 | 提出了一种卷积神经网络,替代了直接用深度图数据训练,采用容易获得的双目立体视觉的角度,在没有参考深度数据的情况下,估计单个图像的深度 | 端到端无监督单眼深度估计;加强左右视差图的一致性;提升性能和鲁棒性; | GODARD C,MAC AODHA O,BROSTOW G J. Unsupervised monocular depth estimation with left - right consistency[C]/ / Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 270-279. |
| Mahjourian 等人工作 | 一种基于无监督学习的新方法,对单目视频中的深度与自我运动的估计,最终作者在 KITTI 数据集和手机拍摄的微景观标定的视频数据集上进行了算法验证 | None | MAHJOURIAN R,WICKE M,ANGELOVA A. Unsupervised learning of depth and ego-motion from monocular video using 3d geometric constraints[C]/ /Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 5667-5675. |
| DeepSlam | 在存在图像噪声的情况下进行特征点检测 | 具有显著的性能差距 | MAHJOURIAN R,WICKE M,ANGELOVA A. Unsupervised learning of depth and ego-motion from monocular video using 3d geometric constraints[C]/ /Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 5667-5675. |
| SuperPoint | 适用于计算机视觉中大量多视图几何问题的兴趣点检测器,和描述符的训练 | None | DETONE D,MALISIEWICZ T,RABINOVICH A. Superpoint: Self - supervised interest point detection and description[C]/ / Proceedings of the IEEE conference on computer vision and pattern recognition workshops. 2018: 224-236. |
| Jiexiong Tang 等人工作 | 一种基于深度学习的GCNv2 网络(GCN-SLAM) ,用于生成关键点和描述符。 | None | TANG J,ERICSON L,FOLKESSON J,et al. GCNv2: Efficient correspondence prediction for real-time SLAM[J]. IEEE Robotics and Automation Letters,2019,4( 4) : 3505-3512. |
2.4 动态环境下的视觉 SLAM
其关键技术就是将动态的行人或物品等特征点,能够在地图中过滤移除,避免对定位和闭环检测产生不良影响。
| 名称 | 内容 | 特点 | 引文 |
|---|---|---|---|
| RDSLAM( Robust monocular slam) | 一种基于关键帧的在线表示和更新方法的实时单目 SLAM 系统。 | 可以处理缓慢变化的动态环境,能够检测变化并及时更新地图。 | TAN W,LIU H,DONG Z,et al. Robust monocular SLAM in dynamic environments[C]/ /2013 IEEE International Symposium on Mixed and Augmented Reality ( ISMAR) . IEEE,2013: 209- 218 |
| DS-SLAM | 一个面对动态环境的语义视觉 SLAM 系统,结合语义信息和运动特征点检测,来滤除每一帧中的动态物体 | 基于优化 ORB-SLAM 的方法、提高位姿估计的准确性、建立语义八叉树地图 | YU C,LIU Z,LIU X J,et al. DS -SLAM: A semantic visual SLAM towards dynamic environments [C]/ /2018 IEEE/RSJ International Conference on Intelligent Robots and Systems ( IROS) . IEEE,2018: 1168-1174. |
| Mask Fusion | 一个实时的、具备对象感知功能的、语义和动态 RGB-D SLAM 系统。 | 在连续的、自主运动中,能够在跟踪和重建的同时,识别分割场景中不同的物体并分配语义类别标签。 | RUNZ M,BUFFIER M,AGAPITO L. Maskfusion: Real-time recognition,tracking and reconstruction of multiple moving objects [C]/ /2018 IEEE International Symposium on Mixed and Augmented Reality ( ISMAR) . IEEE,2018: 10-20. |
| Dyna SLAM | 一个在动态环境下辅助静态地图的 SLAM 系统 | 通过增加运动分割方法使其在动态环境中具有稳健性,并且能够对动态物品遮挡的部分进行修复优化,生成静态场景地图 | BESCOS B,FÁCIL J M,CIVERA J,et al. DynaSLAM: Tracking,mapping,and inpainting in dynamic scenes[J]. IEEE Robotics and Automation Letters,2018,3( 4) : 4076-4083. |
| Static Fusion | 一种面向动态环境基于面元的 RGB-D SLAM 系 统 | 在动态环境中检测运动目标并同时重建,不能有大量动态物体,否则初始化不确定性困难 | SCONA R,JAIMEZ M,PETILLOT Y R,et al. Staticfusion: Background reconstruction for dense rgb - d slam in dynamic environments [C]/ /2018 IEEE International Conference on Robotics and Automation ( ICRA) . IEEE,2018: 3849-3856. |
3 结束语
问题:目前已有的 SLAM 方法仍然在计算力问题、室外动态大规模地图构建、地图复用等方面存在不足,以及在实时性与准确性问题上难以兼顾。
方向:向可移植、多传感器融合以及智能语义 SLAM 的方向发展。


















 8153
8153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











