







《机器学习》,周志华,第二章,p.23
文章目录
- 1. 经验误差与过拟合
- 2. 评估方法
- 留出法(hold-out)
- 交叉验证法(cross validation)
- 自助法(bootstrapping)
- 调参与最终模型
- 3. 性能度量(performance measure)
- 错误率与准确率
- 精确率(precision)、召回率(recal)与 F1-Score
- ROC 与 AUC
- 代价敏感错误率与代价曲线
- 4. 比较检验(了解)
- 假设检验(hypothesis test)
- (1)二项检验(binomial-test)
- (2)t 检验(t-test)
- 交叉验证 t 检验
1. 经验误差与过拟合
- 错误率(error rate):分类错误数 / 样本总数
- 精确率(accuracy):分类正确数 / 样本总数,也就是1 - 错误率
- 误差(error):模型的实际预测输出和样本真实输出的差异
- 训练误差(training error)/ 经验误差(empirical error):训练集上的误差
- 泛化误差(generalization error):新样本上的误差
我们想得到泛化误差最小的模型,但是我们只能去努力最小化经验误差。
- 过拟合(overfitting):学习的过头了,在训练集上的效果非常好,但是泛化能力较差。
- 欠拟合(underfitting):与过拟合相对,训练集上的性质还没学习好,就拿去预测。
欠拟合可以通过多学习来解决,但是过拟合比较麻烦,过拟合是无法避免的。
2. 评估方法
- 测试集(testing set):用于大致测试模型的泛化误差,再进行评估选择合适的模型。注意,测试集的样本尽量不要出现在训练集中,不要在训练的过程中使用。
- 测试误差(testing error):作为模型泛化误差的近似。
那么如何去划分训练集和测试集?
留出法(hold-out)
直接将数据集的数据按照比例划分为训练集和测试集,比如 7:3。
注意:划分的时候尽量保持数据分布的一致性。也就是保留类别比例,这种采样(sampling)的方式为分层采样(stratified sampling)。
举例:数据集包含100个样本,600正例,400反例,正例:反例 = 6:4,那么划分后的训练集(测试集)中的正例:反例也要保持 6:4。
交叉验证法(cross validation)
将数据集划分为 k 个大小近似且互斥的子集,每个子集都尽可能保持数据分布的一致性,即都是通过分层采样得到。然后每次使用 k-1 个子集的并集作为训练集,剩下的那个子集作为测试集去训练,这样可以获得k组训练集+测试集,可以进行 k 次训练和验证,最终返回 k 个测试结果的均值。
交叉验证的稳定性和保真度取决于 k 的取值,所以交叉验证法又称为 k折交叉验证法(k-fold cross validation)
划分为 k 个子集的方式有多种,通常还要随机使用不同的划分重复 p 次,最终的评估结果是这 p 次 k 折交叉验证的均值。
特例:假设数据集中有 m 个数据,我们令 m = k,那每个子集中只有一个数据,这就是留一法(Leave-One-Out,LOO)。留一法不需要进行随机划分,因为怎么划分都一样。它使用的训练集比数据集只少了一个样本,这使得大多数情况下,留一法的对这个数据集的评估结果非常精确。但是在数据集较大的情况下,使用这个方法的计算开销非常大!!!
自助法(bootstrapping)
在含有 m 个样本的数据集中,每次随机挑选一个样本, 将其作为训练样本,再将此样本放回到数据集中,这样有放回地抽样 m 次,生成一个与原数据集大小相同的数据集,这个新数据集就是训练集。这样有些样本可能在训练集中出现多次,有些则可能从未出现。原数据集中大概有 36.8% 的样本不会出现在新数据集中。因此,我们把这些未出现在新数据集中的样本作为验证集。把前面的步骤重复进行多次,这样就可以训练出多个模型并得到它们的验证误差,然后取平均值,作为该模型的验证误差。
为什么原数据集中大概有 36.8% 的样本不会出现在新数据集中?
假设数据集中有m个样本,那么每次每一个样本被抽取到的概率是 1/m,抽样 m 次,某个样本始终不被抽取到的概率是 (1-1/m)m。当 m 的取值趋近于无穷大时,样本未被抽中的概率为e的负一次方,结果约等于 0.368。
自助法在数据集较小,难以有效划分训练集/验证集时很有用;此外,自助法能从初始数据集中产生多个不同的训练集,这对集成学习等方法有很大的好处。但是自助法产生的训练集的数据分布和原数据集的不一样,会引入估计偏差。
因此,在数据量足够的情况下 ,更推荐使用留出法和交叉验证法。
调参与最终模型
- 调参(parameter tuning):对算法的参数进行调节,调参对最终的模型性能有着关键的影响。
- 验证集(validation set):用于评估测试模型的数据,由训练数据划分出。
我们在对比不同模型泛化性能时,我们用测试集上的判别效果来估计模型实际使用时的泛化能力,而把训练数据另外划分为训练集和验证集,基于验证集上的性能来进行模型选择和调参。
在模型的训练过程中,我们只使用了部分数据进行训练,还流出了一部分数据用于评估测试。因此,在模型选择完成之后,学习算法和参数都已经确定,此时我们应该使用整个数据集重新训练模型,这才是最终给用户的模型。
3. 性能度量(performance measure)
衡量模型泛化能力的标准。
- 均方误差(mean squared error,MSE):用真实值 - 预测值然后平方后求和平均,常用线性回归的损失函数。MSE是指参数估计值与参数真值之差平方的期望值。MSE可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度。

错误率与准确率
- 错误率:分类错误的样本数占样本总数的比例。
- 准确率(accurancy):分类正确的样本数占样本总数的比例。
精确率(precision)、召回率(recal)与 F1-Score
对于二分类问题,可以根据真实类别和预测类别分为真正例(true positive,TP)、假正例(false positive,FP)、真反例(true negative,TN)、假反例(false negative,FN)。显然有:TP + FP + TN + FN = 样本总数。
我们期望 TP、TN越大越好,FP、FN 越小越好。

- 精确率 / 查准率(precision):预测为正例的那些数据里预测正确的数据个数。
- 召回率 / 查全率(recall):真实为正例的那些数据里模型预测正确的数据个数。
- 精确率-召回率曲线(P-R曲线):以精确率为纵轴,召回率为横轴的曲线。
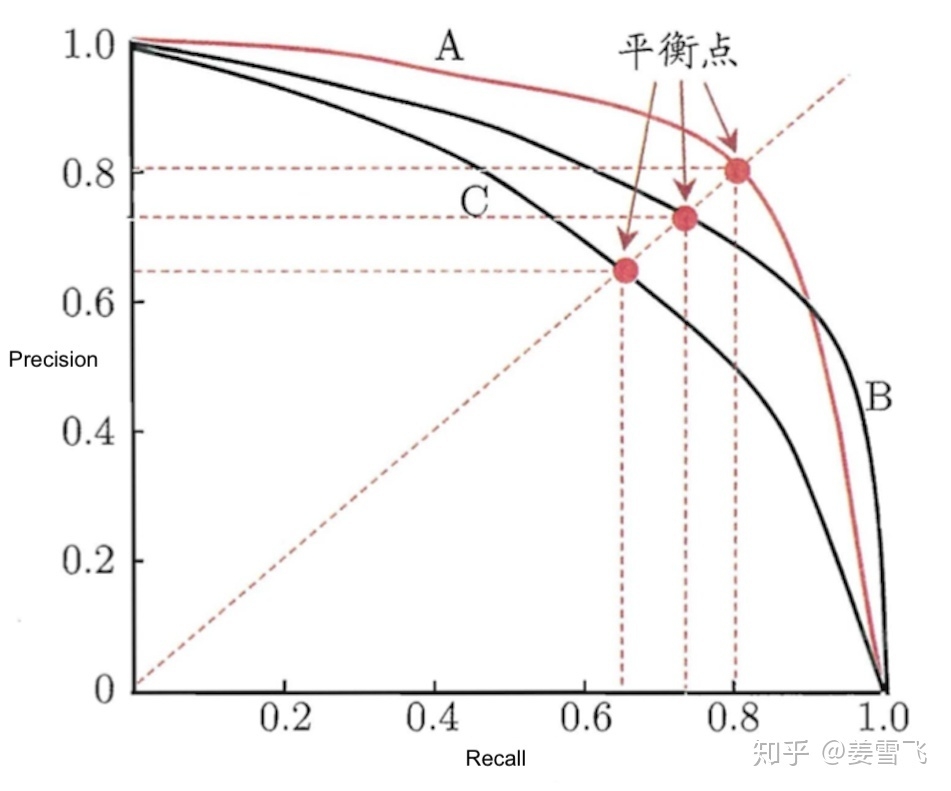
在对两个模型的 P-R 曲线进行比较时,如果一个模型的曲线完全在另一个模型曲线的上方,那么上方的这个模型的效果更好。
还有一种 P-R 曲线的的比较方法,那就是比较其与 x,y 轴围成图形的面积,面积越大,效果越好。但是这个面积的大小比较难去估计,所以引入了平衡点(Break-Even Point,BEP) 这一概念,它是精确率 = 召回率相同时的取值,值越大的模型 效果越好。
精确率和召回率是一对矛盾的度量。一者偏高,另外一者往往偏低。用 BEP 去衡量过于简略,于是就有了 F1-Score。
- F1-Score:F1 值是来综合评估精确率和召回率,当精确率和召回率都高时,F1 也会高。F1 通常有两种公式,一种是基于精确率和召回率的调和平均定义,另一种是基于他们的带权调和平均定义。
1 F 1 = 1 2 ⋅ ( 1 P + 1 R ) ⟶ F 1 = 2 ⋅ P R P + R = 2 ⋅ T P 样 例 总 数 + T P − T N \frac{1}{F1} = \frac{1}{2}\cdot(\frac{1}{P} + \frac{1}{R}) \longrightarrow F1 = \frac{2\cdot PR}{P+R} = \frac{2\cdot TP}{样例总数+TP-TN} F11=21⋅(P1+R1)⟶F1=P+R2⋅PR=样例总数+TP−TN2⋅TP 1 F β = 1 1 + β 2 ⋅ ( 1 P + 1 R ) ⟶ F β = ( 1 + β 2 ) ⋅ P R ( β 2 ⋅ P ) + R \frac{1}{F_{\beta}} = \frac{1}{1+\beta^{2}}\cdot (\frac{1}{P} + \frac{1}{R}) \longrightarrow F_{\beta} = \frac{(1+\beta^{2})\cdot PR}{(\beta^{2}\cdot P)+R} Fβ1=1+β21⋅(P1+R1)⟶Fβ=(β2⋅P)+R(1+β2)⋅PR
其中 β > 0 \beta > 0 β>0 度量了 reacll 和 precision 的相对重要性。 β = 1 \beta = 1 β=1 时就是标准的 F1-Score, β > 1 \beta > 1 β>1 时 recall 有更大影响, β < 1 \beta < 1 β<1 时 precision 有更大影响。
ROC 与 AUC
-
TPR (True Postive Rate):真正类率,代表分类器预测的正类中实际正实例占所有正实例的比例, S e n s i t i v i t y Sensitivity Sensitivity。
-
FPR(False Postive Rate):假正类率,代表分类器预测的正类中实际负实例占所有负实例的比例, 1 − S p e c i f i c i t y 1-Specificity 1−Specificity。
-
TNR(True Negative Rate):真负类率,代表分类器预测的负类中实际负实例占所有负实例的比例, S p e c i f i c i t y Specificity Specificity。
T P R = T P ( T P + F N ) TPR = \frac{TP}{(TP+FN)} TPR=(TP+FN)TP F P R = F P F P + T N = 1 − T N R FPR=\frac{FP}{FP+TN}=1-TNR FPR=FP+TNFP=1−TNR T N R = T N F P + T N = 1 − F P R TNR=\frac{TN}{FP+TN}=1-FPR TNR=FP+TNTN=1−FPR -
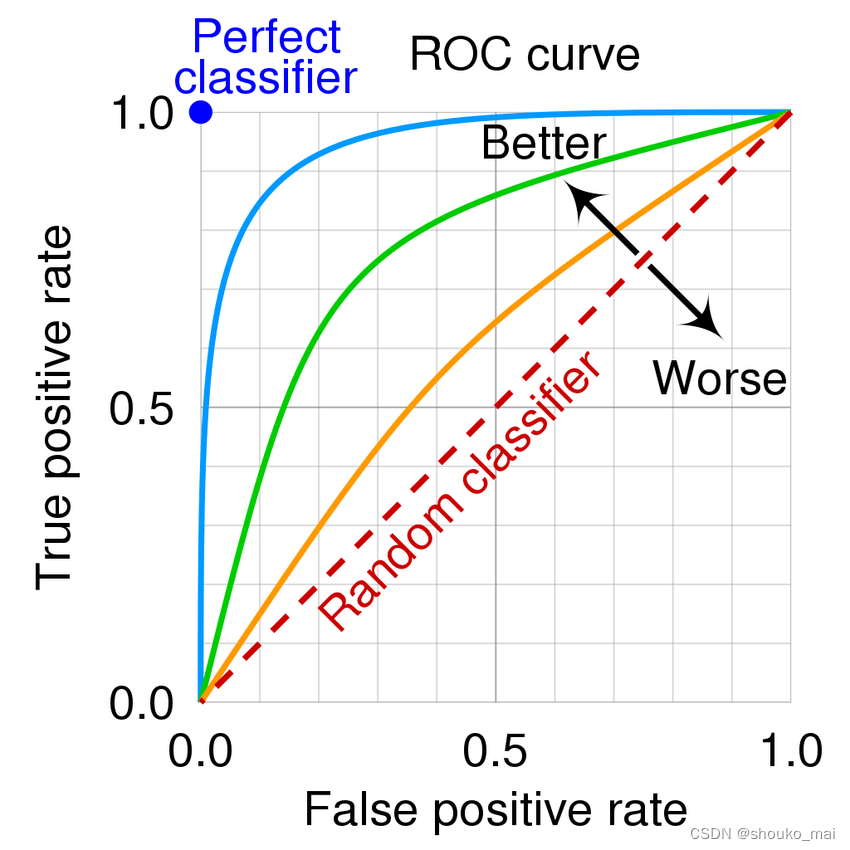
ROC 曲线(receiveroperating characteristic):纵轴表示真正类率灵敏度,横轴表示负正类率特异度。对某个分类器而言,我们可以根据其在测试样本上的表现得到一个 TPR 和 FPR 点对。这样,此分类器就可以映射成 ROC 平面上的一个点。调整这个分类器分类时候使用的阈值,我们就可以得到一个经过 (0, 0) ,(1, 1) 的曲线,这就是此分类器的 ROC 曲线。
一般情况下,ROC 曲线都应该处于 (0, 0) 和 (1, 1) 连线的上方。因为 (0, 0) 和 (1, 1) 连线形成的 ROC 曲线实际上代表的是一个随机分类器。如果很不幸,你得到一个位于此直线下方的分类器的话,一个直观的补救办法就是把所有的预测结果反向,即:分类器输出结果为正类,则最终分类的结果为负类,反之,则为正类。
- AUC(Area Under roc Curve):顾名思义,AUC的值就是处于ROC 曲线下方的那部分面积的大小。通常,AUC的值介于 0.5 到 1.0 之间,AUC值越大的模型,正确率越高。
从AUC判断分类器(预测模型)优劣的标准:
- AUC = 1,是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合,不存在完美分类器。
- 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
- AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
- AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
代价敏感错误率与代价曲线
在现实情况中,分类错误之后不同类型错误所造成的后果也不同,比如安检通道把钥匙等金属制品错误的分类到危险品,仅仅是多了一层人工检查的麻烦;但是如果把一把刀错误的分类到安全品里面,那么可能造成十分严重的后果。
不同的错误造成的损失是不同的,为了权衡这个损失,可以为错误赋予非均等代价(unequal cost)。我们可以用一张表来代表代价: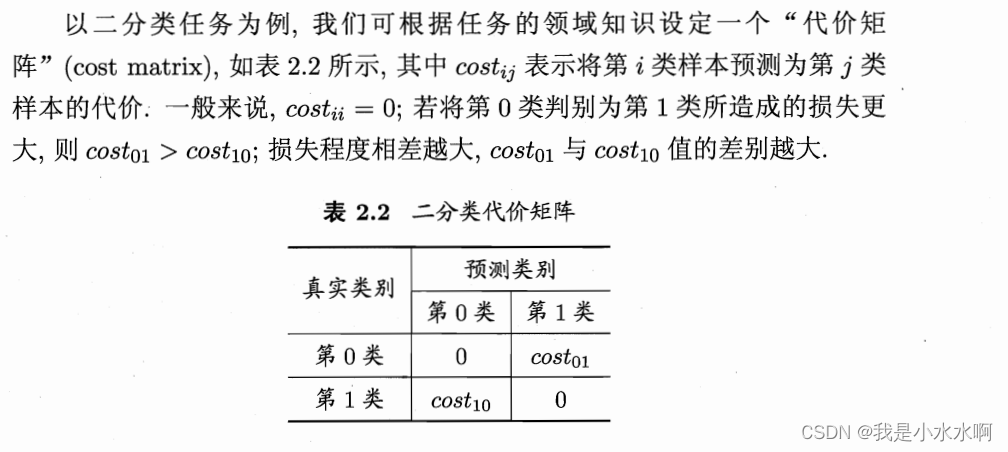
在实际应用中,代价敏感错误率通常用于处理那些不同类别错误分类代价差异较大的问题,例如欺诈检测、医学诊断等领域。在训练分类模型时,引入代价矩阵可以帮助模型更好地适应不同类别的代价,从而提高模型在实际应用中的性能。
-
代价曲线(Cost Curve):是一个用于评估代价敏感学习算法性能的工具。在许多实际问题中,不同类别的错误分类可能导致不同的代价。例如,在医疗诊断中,将一个健康患者误诊为患病可能会导致不同于将一个患病患者误诊为健康的代价。代价曲线帮助我们在考虑不同错误分类代价的情况下,选择一个适当的分类阈值。
-
FNR(False Negative Rate):假反例率,表示正例中有多少被预测错了,变成了负例。
-
FPR(False Positive Rate):假正例率,表示负例中有多少预测错了,变成了正例。
-
P(+):归一化的正例概率代价,表示你现在有的样本中,正例的比例。
纵轴,归一化的损失代价,公式上方是模型总概率代价,下方是总概率代价的最大值(即 FNR、FPR 都等于 1):
c
o
s
t
n
o
r
m
=
F
N
R
⋅
p
⋅
c
o
s
t
01
+
F
P
R
⋅
(
1
−
p
)
⋅
c
o
s
t
10
p
⋅
c
o
s
t
01
+
(
1
−
p
)
⋅
c
o
s
t
10
cost_{norm} = \frac{FNR\cdot p\cdot cost_{01}+FPR\cdot (1-p)\cdot cost_{10}}{p\cdot cost_{01}+(1-p)\cdot cost_{10}}
costnorm=p⋅cost01+(1−p)⋅cost10FNR⋅p⋅cost01+FPR⋅(1−p)⋅cost10
横轴,归一化的正例概率代价,公式上方是正例的概率代价,下方是总概率代价最大值,相除进行归一化:
P
(
+
)
=
p
⋅
c
o
s
t
01
p
⋅
c
o
s
t
01
+
(
1
−
p
)
⋅
c
o
s
t
10
P(+) = \frac{p\cdot cost_{01}}{p\cdot cost_{01}+(1-p)\cdot cost_{10}}
P(+)=p⋅cost01+(1−p)⋅cost10p⋅cost01
将横轴公式带入纵轴,得到:
c
o
s
t
n
o
r
m
=
F
N
R
⋅
P
(
+
)
+
F
P
R
⋅
(
1
−
P
(
+
)
)
cost_{norm} = FNR\cdot P(+)+FPR\cdot (1-P(+))
costnorm=FNR⋅P(+)+FPR⋅(1−P(+))
这个公式仅与 FNR、FPR、P(+) 有关,其中:
F
N
R
=
1
−
T
P
R
=
F
N
F
N
+
T
P
FNR=1-TPR=\frac{FN}{FN+TP}
FNR=1−TPR=FN+TPFN
F
P
R
=
F
P
F
P
+
T
N
FPR=\frac{FP}{FP+TN}
FPR=FP+TNFP
代价曲线的绘制:ROC 曲线上的每一点都对应了代价平面上的一条线段。因为假设 ROC 曲线上点的坐标为(TPR,FPR),那么就可以计算出对应的 FNR,然后就可以在代价平面上绘制出一条从(0,FPR)到(1,FNR)的线段,线段下面的面积即代表了该条件下的期望总体代价。
我们将 ROC 曲线上的每一个点都转换为代价平面上的一条线段,然后取所有线段下界的面积,这就是在所有条件下模型的期望总体代价,如下图所示:

代价曲线的意义和应用包括以下几点:
- 选择最优分类阈值: 代价曲线可以帮助你选择一个最适合的分类阈值,使得在考虑不同类别错误分类代价的情况下,总代价最小化。通过观察代价曲线,你可以选择使得总代价最小的分类阈值,从而在实际应用中取得更好的性能。
- 模型选择和比较: 代价曲线可以用于比较不同模型在代价敏感情况下的性能。通过比较不同模型在代价曲线上的表现,你可以选择最适合你问题的模型。
- 业务决策支持: 在许多业务场景中,不同类型的错误可能具有不同的后果。例如,在信用卡欺诈检测中,将一个正常交易误判为欺诈交易的代价可能比将一个欺诈交易误判为正常交易的代价大得多。代价曲线可以帮助业务决策者理解模型的性能,并根据业务需求调整模型的阈值。
4. 比较检验(了解)
在机器学习中,比较两个模型的学习性能,并不是求出两个关于性能度量的值,然后比较大小就可以完成的。因为模型的性能涉及到很多方面,而这些方面有时候又有矛盾关系。
我们需要考虑的评估学习性能的因素主要有以下几点:
- 泛化能力:即机器学习算法对新样本的适应能力。。
- 测试集的选择:不同大小、不同样例的测试集导致的训练结果可能是不一样的。
- 算法的随机性:因为机器学习是有黑盒性质的,我们无法得知里面的具体运行过程,有可能用同一个测试集、在同一个模型上以相同的参数来运行,都会出现不一样的结果。
假设检验(hypothesis test)
- 泛化错误率 ϵ \epsilon ϵ:是指模型在一般情况下,对一个样本分类出错的概率。
- 测试错误率
ϵ
^
\hat{\epsilon}
ϵ^:即模型在一个大小为 m 的数据集上恰好有
ϵ
^
m
\hat{\epsilon } m
ϵ^m 个样本被分错类了。
– 泛化错误率是一个理论上的值,无法获得;而测试错误率是一个我们可以测量得到的值。
假设检验的方法就是用 ϵ ^ \hat{\epsilon} ϵ^ 去估计 ϵ \epsilon ϵ 的值。
(1)二项检验(binomial-test)
一个模型在 m 个样本上,其中恰有
ϵ
^
⋅
m
\hat{\epsilon}\cdot m
ϵ^⋅m 个样本被误分类。那么泛化错误率为
ϵ
\epsilon
ϵ 的模型,要将其中
m
′
m'
m′ 个样本误分类,其余样本全部分类正确的概率为:
P
(
ϵ
^
;
ϵ
)
=
C
m
m
′
ϵ
m
′
(
1
−
ϵ
)
)
m
−
m
′
P \left ( \hat \epsilon ;\epsilon \right ) = C_{m}^{m'} \epsilon ^ {m'} \left ( 1 - \epsilon) \right ) ^ {m - m'}
P(ϵ^;ϵ)=Cmm′ϵm′(1−ϵ))m−m′
由此可以估算出其恰好将
m
′
=
ϵ
⋅
m
m' = \epsilon \cdot m
m′=ϵ⋅m 个样本误分类的概率如下:
P
(
ϵ
^
;
ϵ
)
=
C
m
ϵ
^
⋅
m
ϵ
ϵ
^
⋅
m
(
1
−
ϵ
)
m
−
ϵ
^
⋅
m
P(\hat \epsilon;\epsilon ) = C_{m}^{\hat \epsilon \cdot m} \epsilon ^{\hat{\epsilon }\cdot m }(1-\epsilon )^{m-\hat{\epsilon }\cdot m }
P(ϵ^;ϵ)=Cmϵ^⋅mϵϵ^⋅m(1−ϵ)m−ϵ^⋅m
给定测试错误率 ϵ ^ \hat{\epsilon} ϵ^,则使用极大似然估计,解 ∂ P ( ϵ ^ ; ϵ ) ∂ ϵ = 0 \frac{\partial P(\hat \epsilon;\epsilon )}{\partial \epsilon} = 0 ∂ϵ∂P(ϵ^;ϵ)=0 可知 P ( ϵ ^ ; ϵ ) P(\hat \epsilon;\epsilon ) P(ϵ^;ϵ) 在 ϵ = ϵ ^ \epsilon = \hat \epsilon ϵ=ϵ^ 时最大, ∣ ϵ − ϵ ^ ∣ | \epsilon - \hat \epsilon| ∣ϵ−ϵ^∣ 增大时 P ( ϵ ^ ; ϵ ) P(\hat \epsilon;\epsilon ) P(ϵ^;ϵ) 减小,这符合二项分布(binomial distribution)
当
ϵ
=
0.3
,
m
=
10
\epsilon = 0.3, m=10
ϵ=0.3,m=10,我们可以发现在 10 个样本中测得 3 个被误分类的概率最大。

我们可以使用“二项检验”对
ϵ
≤
0.3
\epsilon \le 0.3
ϵ≤0.3 (泛化错误率是否不大于 0.3)这样的假设进行检验。
更一般的假设:单个模型的泛化错误率
ϵ
\epsilon
ϵ 不超过给定值
ϵ
0
\epsilon_0
ϵ0:
ϵ
≤
ϵ
0
\epsilon \le \epsilon_0
ϵ≤ϵ0。
则在“
1
−
α
1-\alpha
1−α”的概率下,所能观测到的最大错误率就是
ϵ
0
\epsilon_0
ϵ0。
- 显著性水平
α
\alpha
α:一个概率值,原假设为真时,拒绝原假设的概率,表示为alpha常用取值为0.01, 0.05, 0.10
在下图中, α \alpha α 是右边分布图中阴影的面积,其他部分就是我们可以接受的错误率。这里的 1 − α 1-\alpha 1−α 就是我们的置信度,对应置信度的区间 [0, 6] 就是置信区间,只要我们验证的结果在置信区间内,那么就是可信的。

于是就有了这个公式,左边式子在右边式子满足时成立:
ϵ ‾ = max ϵ s.t. ∑ i = ϵ 0 × m + 1 m C m i ϵ 0 i ( 1 − ϵ 0 ) m − i < α \overline{\epsilon} = \mathop{\max} {\epsilon} \text{ s.t. } \sum_{i=\epsilon_0 \times m+1}^{m} \text{C}_{m}^{i} \epsilon_0^{i}(1-\epsilon_0)^{m-i}<\alpha ϵ=maxϵ s.t. i=ϵ0×m+1∑mCmiϵ0i(1−ϵ0)m−i<α
(2)t 检验(t-test)
假设单个模型的泛化错误率
ϵ
\epsilon
ϵ 等于其通过 k 折交叉验证得到的多次测试的错误率
ϵ
^
1
,
.
.
.
,
ϵ
^
k
\hat{\epsilon}_1,...,\hat{\epsilon}_k
ϵ^1,...,ϵ^k 的平均值
μ
\mu
μ:
ϵ
=
μ
=
1
k
∑
i
=
1
k
ϵ
^
i
\epsilon = \mu =\frac{1}{k}\sum_{i=1}^{k}\hat{\epsilon}_i
ϵ=μ=k1i=1∑kϵ^i
计算 k 次测试错误率
ϵ
^
1
,
.
.
.
,
ϵ
^
k
\hat{\epsilon}_1,...,\hat{\epsilon}_k
ϵ^1,...,ϵ^k 的平均值
μ
\mu
μ 和方差
σ
2
\sigma^2
σ2:
μ
=
1
k
∑
i
=
1
k
ϵ
^
i
\mu = \frac{1}{k}\sum_{i=1}^{k}\hat{\epsilon}_i
μ=k1i=1∑kϵ^i
σ
2
=
1
k
−
1
∑
i
=
1
k
(
ϵ
^
i
−
μ
)
2
\sigma^2 = \frac{1}{k-1}\sum_{i=1}^{k}(\hat{\epsilon}_i-\mu)^2
σ2=k−11i=1∑k(ϵ^i−μ)2
构造统计量
τ
t
\tau_t
τt 服从自由度为 k - 1 的 t 分布,则可以使用 t 检验:
τ
t
=
k
(
μ
−
ϵ
)
σ
\tau_t = \frac{\sqrt{k}(\mu-\epsilon)}{\sigma}
τt=σk(μ−ϵ)
交叉验证 t 检验
假设模型 A 和模型 B 的性能相同:在相同的训练集、测试集上得到的测试错误率相同:
ϵ
i
A
=
ϵ
i
B
\epsilon_i^A = \epsilon_i^B
ϵiA=ϵiB
对于模型 A 和模型 B,通过 k 折交叉验证的得到的测试错误率为
ϵ
1
A
,
.
.
.
,
ϵ
k
A
\epsilon_1^A,...,\epsilon_k^A
ϵ1A,...,ϵkA 和
ϵ
1
B
,
.
.
.
,
ϵ
k
B
\epsilon_1^B,...,\epsilon_k^B
ϵ1B,...,ϵkB,其中
ϵ
1
A
\epsilon_1^A
ϵ1A 和
ϵ
1
B
\epsilon_1^B
ϵ1B 是在相同的第 i 折训练/测试集上得到的结果。
采用**成对 t 检验(paired t-test)**进行检验。具体的,对每一对测试错误率求差
Δ
i
=
ϵ
i
A
−
ϵ
i
B
\Delta_i=\epsilon_i^A-\epsilon_i^B
Δi=ϵiA−ϵiB ,可得差值
Δ
1
,
…
,
Δ
k
\Delta_1,…,\Delta_k
Δ1,…,Δk。计算其平均值
μ
\mu
μ 和方差
σ
2
\sigma^2
σ2,构造统计量
τ
t
\tau_t
τt:
τ
t
=
k
μ
σ
\tau_t = \frac{\sqrt{k}\mu}{\sigma}
τt=σkμ
上述提交了
τ
t
\tau_t
τt 服从自由度 k - 1 的 t 分布,可以使用 t 检验。















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









