







 本文详细介绍了LZW编码的工作原理,包括编码和解码过程,并提供了代码分析。实验结果显示,LZW编码对不同文件类型的压缩效果因文件中重复字符串的多少而异,对于重复字符串较多的文件,压缩效率更高。LZW编码的优点在于其自适应性和简单的算法实现,但当字符串重复率低时,压缩效率会受到影响。
本文详细介绍了LZW编码的工作原理,包括编码和解码过程,并提供了代码分析。实验结果显示,LZW编码对不同文件类型的压缩效果因文件中重复字符串的多少而异,对于重复字符串较多的文件,压缩效率更高。LZW编码的优点在于其自适应性和简单的算法实现,但当字符串重复率低时,压缩效率会受到影响。
LZW编码
LZW编码是从输入的字符流中提取词条,创建词典,用码字来表示词条。LZW围绕词典转换表完成,LZW编码器通过管理词典完成输入和输出间的转换,输入是字符流,输出是n位表示的码字流。解码端输入码字流,边解码边建立词典,得到输出字符流。
编码原理
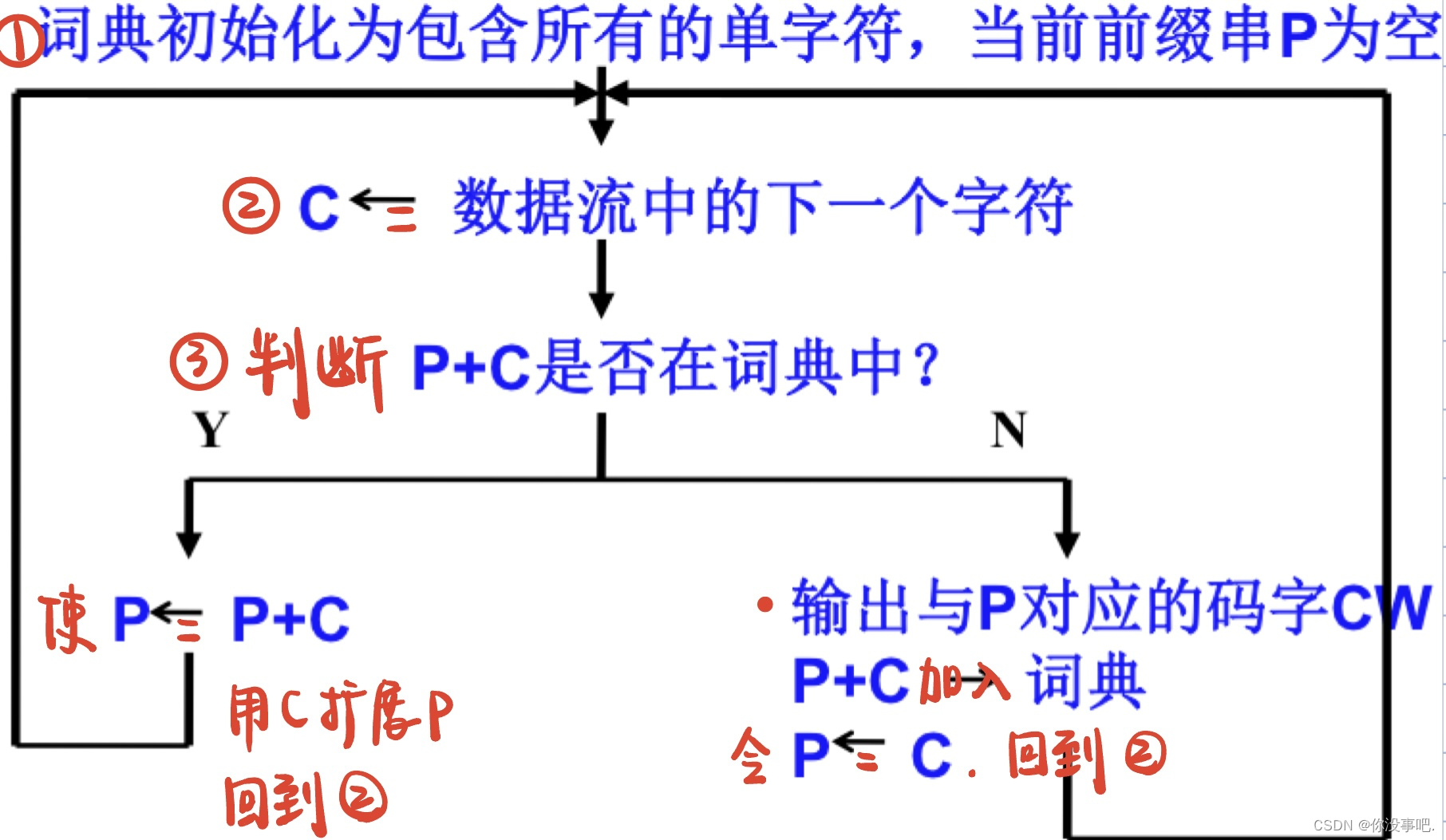
首先初始化词典,然后顺序从待压缩文件中读入字符并按照上述算法执行编码,最后将编得码字流输出到文件中。
解码原理
 LZW解码算法首先初始化词典,然后顺序从压缩文件中读入码字,并按照上述算法执行解码,最后将解得的字符串输出至文件中。
LZW解码算法首先初始化词典,然后顺序从压缩文件中读入码字,并按照上述算法执行解码,最后将解得的字符串输出至文件中。
代码分析
- 定义词典树
#define MAX_CODE 65535 //词典中最多的词典数目 struct { //词典树 int suffix; //当前字符的尾缀字符 int parent, firstchild, nextsibling; //分别表示当前节点对应的母节点、第一个孩子节点、下一个兄弟节点 } dictionary[MAX_CODE+1]; int next_code; int d_stack[MAX_CODE]; // stack for decoding a phrase,用来存储解码后的短语 - 初始化词典树
void InitDictionary( void){ //初始化词典 int i; for( i=0; i<256; i++){ //单个字符写入词典,也就是词典树的第一层 dictionary[i].suffix = i; //尾缀字符 dictionary[i].parent = -1; //母节点
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2791
2791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









