






DPCM
DPCM是差分预测编码调制的缩写,是比较典型的预测编码系统。DPCM利用信源相邻符号之间的相关性进行预测编码。在编码端,输入一个样本值,与上一个样本的预测值作差,对差值进行量化,得到的量化结果一方面作为编码端输出,另一方面反量化后作为预测器的输入,与上一个样本的预测值相加,作为当前样本的预测值(或说重建值)。
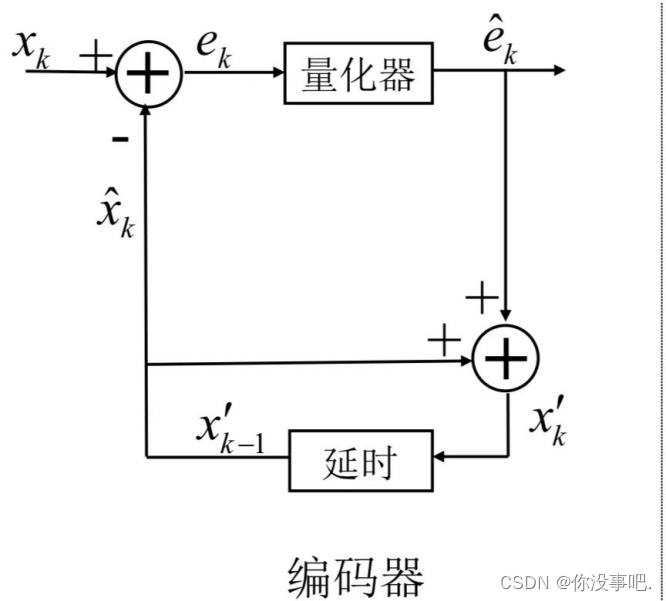
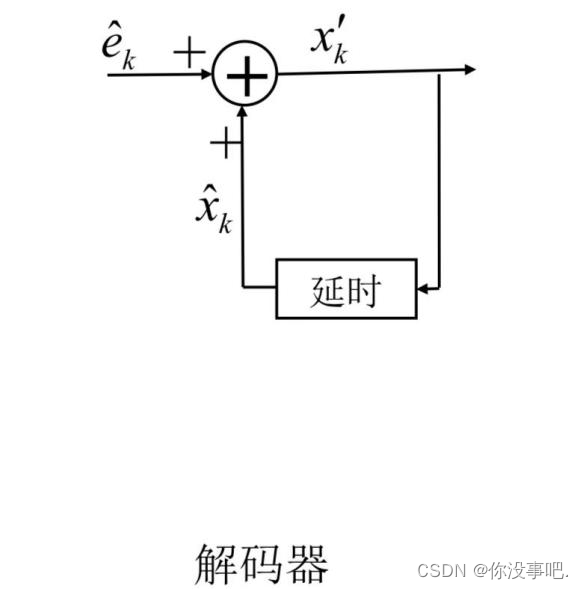
在DPCM系统中,需要注意的是预测器的输入是已经解码以后的样本。之所以不用原始样本来做预测,是因为在解码端无法得到原始样本,只能得到存在误差的样本。因此,在DPCM编码器中实际内嵌了一个解码器。
量化
在本次实验中,我们采用固定预测器和均匀量化器。量化器采用8比特均匀量化。本实验的目标是验证DPCM编码的编码效率。首先读取一个256级的灰度图像,采用自己设定的预测方法计算预测误差,并对预测误差进行8比特均匀量化(基本要求)。还可对预测误差进行1比特、2比特和4比特的量化设计。
PSNR(峰值信噪比)
PSNR是一种评价图像的客观标准,对于给定大小为M×N的图像来说,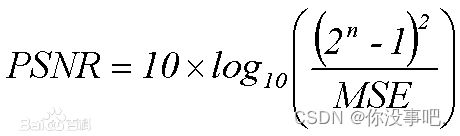
![]()
- PSNR高于40dB说明图像质量非常好,非常接近原始图像;
- PSNR30-40dB表示图像质量较好,失真可察觉但能接受;
- PSNR20-30dB表明图像质量差;
- PSNR低于20dB图像质量无法接受。
代码实现
DPCM编码
本次实验采用左侧预测,并设第一列的预测值为128
void DPCM(unsigned char* y_buffer, unsigned char* pred_buffer, unsigned char* re_buffer, int width, int height, int qbit)
{
int error;
for (int i = 0; i < height; i++)
{
for (int j = 0; j < width; j++)
{
if (j == 0)
{ //第一列以128进行预测
error = (y_buffer[i * width + j]) - 128; //误差值
pred_buffer[i * width + j] = Quant(qbit, error); //量化误差值
re_buffer[i * width + j] = inverseQuant(qbit, pred_buffer[i * width + j]) + 128; //重建值
}
else
{ //其他列都以前一列进行预测
error = (y_buffer[i * width + j]) - re_buffer[i * width + j - 1]; //误差值
pred_buffer[i * width + j] = Quant(qbit, error); //量化误差值
re_buffer[i * width + j] = inverseQuant(qbit, pred_buffer[i * width + j]) + re_buffer[i * width + j - 1]; //重建值
}
}
}
int max = pow(2, qbit) - 1; //当前量化的最大值
for (int i = 0; i < width * height; i++)
{ //处理可能溢出的情况
if (pred_buffer[i] < 0) pred_buffer[i] = 0;
if (pred_buffer[i] > max) pred_buffer[i] = max;
if (re_buffer[i] < 0) re_buffer[i] = 0;
if (re_buffer[i] > 255) re_buffer[i] = 255;
}
}PSNR计算
double PSNR(unsigned char* y_buffer, unsigned char* re_buffer,int width, int height, int qbit)
{
double mse = 0, psnr = 0;
for (int i = 0; i < width * height; i++) {
mse += pow((y_buffer[i] - re_buffer[i]), 2);
}
mse = mse / (width * height);
psnr = 10 * log10(pow(255, 2) / mse);
return psnr;
}Main.cpp
int main(int argc, char** argv) {
char* ori_name = argv[1]; //原始图像
char* pred_name = argv[2]; //预测误差图像
char* re_name = argv[3]; //重建图像
int qbit = atoi(argv[4]); //量化bit数
FILE* ori_file = NULL; //原始yuv
FILE* pred_file = NULL; //预测误差yuv
FILE* re_file = NULL; //重建yuv
int width = 256, height = 256;
unsigned char* y_buffer = new unsigned char[width * height];
unsigned char* u_buffer = new unsigned char[(width * height) / 4];
unsigned char* v_buffer = new unsigned char[(width * height) / 4]; //原始图像的yuv
unsigned char* pred_buffer = new unsigned char[width * height]; //预测误差图像buffer
unsigned char* re_buffer = new unsigned char[width * height]; //重建图像buffer
ori_file = fopen(ori_name, "rb");
if (ori_file == NULL) {
cout << "Can't open the origin image!" << endl;
}
else {
cout << "The origin image has been opened!" << endl;
}
pred_file = fopen(pred_name, "wb");
if (pred_file == NULL) {
cout << "Can't open the predict image!" << endl;
}
else {
cout << "The predict image has been opened!" << endl;
}
re_file = fopen(re_name, "wb");
if (re_file == NULL) {
cout << "Can't open the rebuild image!" << endl;
}
else {
cout << "The rebild image has been opened!" << endl;
}
//读原文件
fread(y_buffer, 1, width * height, ori_file);
fread(u_buffer, 1, (width * height) / 4, ori_file);
fread(v_buffer, 1, (width * height) / 4, ori_file);
FILE* orig; //计算原文件的概率分布
orig = fopen("E:/biancheng/c and c++/data compression/allfile/ex_3/Lena256B_origin.txt", "wb");
double frequency[256] = { 0 };
Frequency(y_buffer, frequency, height, width);
fprintf(orig, "%s\t%s\n", "symbol", "freq");
for (int i = 0; i < 256; i++)
{
fprintf(orig, "%d\t%f\n", i, frequency[i]);
}
//DPCM
DPCM(y_buffer, pred_buffer, re_buffer, width, height, qbit);
//计算PSNR
double psnr;
psnr = PSNR(y_buffer, re_buffer, width, height, qbit);
cout << "The PSNR of " << ori_name << " is " << psnr << endl;
//写预测误差文件
fwrite(pred_buffer, 1, width * height, pred_file);
fwrite(u_buffer, 1, (width * height) / 4, pred_file);
fwrite(v_buffer, 1, (width * height) / 4, pred_file);
FILE* pred; //计算预测误差文件的概率分布
pred = fopen("E:/biancheng/c and c++/data compression/allfile/ex_3/Lena256B_predict_1bit.txt", "wb");
double frequency_[256] = { 0 };
Frequency(pred_buffer, frequency_, height, width);
fprintf(pred, "%s\t%s\n", "symbol", "freq");
for (int i = 0; i < 256; i++)
{
fprintf(pred, "%d\t%f\n", i, frequency_[i]);
}
//写重建图像文件
fwrite(re_buffer, 1, width * height, re_file);
fwrite(u_buffer, 1, (width * height) / 4, re_file);
fwrite(v_buffer, 1, (width * height) / 4, re_file);
fclose(ori_file);
fclose(pred_file);
fclose(re_file);
delete[] y_buffer;
delete[] u_buffer;
delete[] v_buffer;
delete[] pred_buffer;
delete[] re_buffer;
return 0;
}实验结果
| 量化比特数 | 原始图像 | 预测误差图 | 重建图像 | PSNR |
|---|---|---|---|---|
| 8 |  |  |  | 51.1338 |
| 4 |  |  |  | 14.8189 |
| 2 |  |  |  | 7.64999 |
| 1 |  |  |  | 7.59892 |
可以看出,使用8bit量化可以较好地还原原始图像,此时得到的PSNR值也在50以上,说明图像质量极好,接近原始图像,人眼几乎无法看出异常。随着量化bit数减少,PSNR值也逐渐降低,图像出现了明显的失真,已经无法很好的重建图像了。
预测误差图概率分布
-
量化比特数
预测误差图概率分布
8
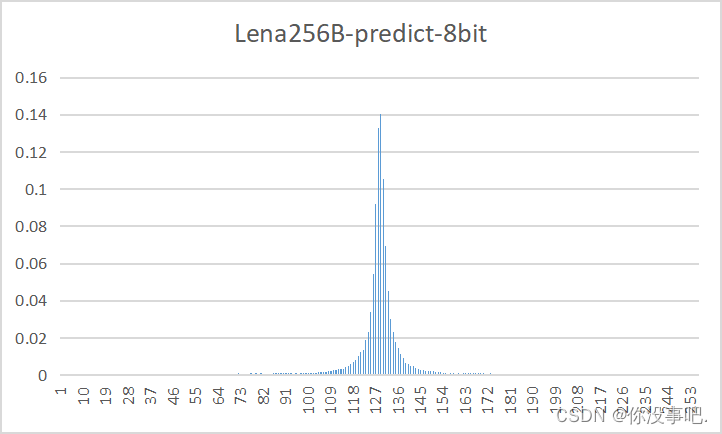
4

2
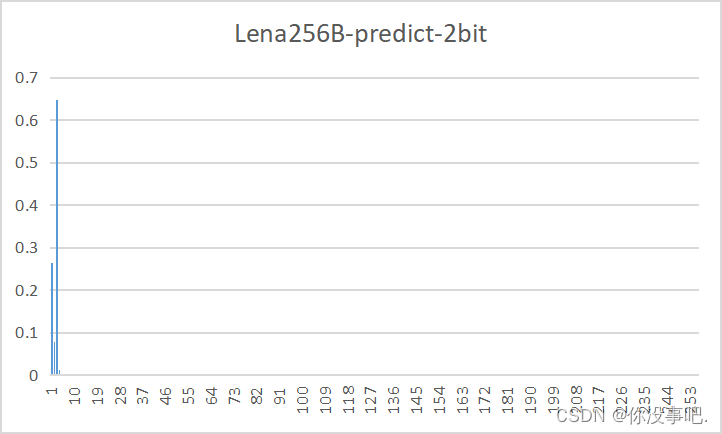
1
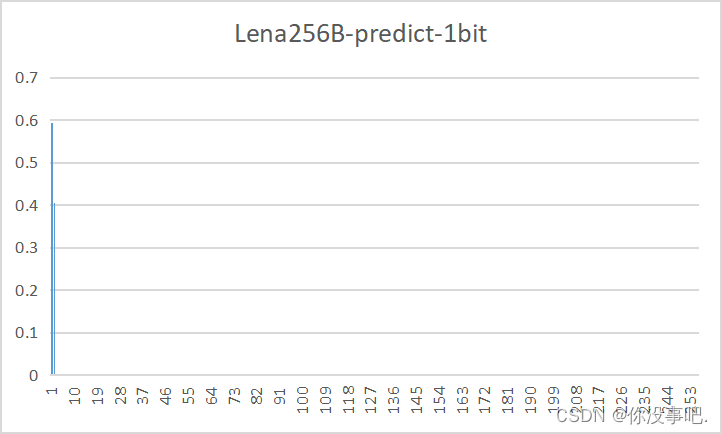
通过观察发现,利用DPCM得到的预测残差图的概率分布近似为Laplacian分布,更适合用霍夫曼编码,因此预测误差图的压缩效率更高。
实验总结
·对于4bit、2bit、1bit量化的情况,因为量化后电平较低,所以可能没有办法看清预测误差图像,因此可以将电平抬高128观察。
·对于相邻符号之间相关性较高的图片来说,DPCM可以很好的利用这一特性,减少冗余度,提高编码效率。















 1723
1723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









