







Friedman检验和后续检验的全过程
1.计算平均序值-根据各项评价指标来排序,比如汉明损失,该值越低越好,所以如果值越低,就标注1,按照升序来依次排序,1,2,3,4,5,6,7,8,9。如果发现在某个数据集上的两个算法的性能结果一致,那么就对它们的序值进行平分,比如在数据集langlog上,存在两个算法的序值都为6.5,这是因为进行排序时,它们原本的位置应该是6和7,但由于两者性能相同,因此这里,对它们进行了平均处理,即6+7=13,13/2=6.5,然后表格中的每一列的所有序值进行相加,除以数据集个数,就可以得到平均序值了,比如第一列的平均序值计算如下:(1+4+7+1+1+1+1+1+1+6+1.5+1+1+1+1)/15=1.9667;再比如对于评价指标F1来说,值越大代表算法的性能越好,所以最大的值排序1,其他的按照降序来进行排序,剩下的步骤同上述一样。
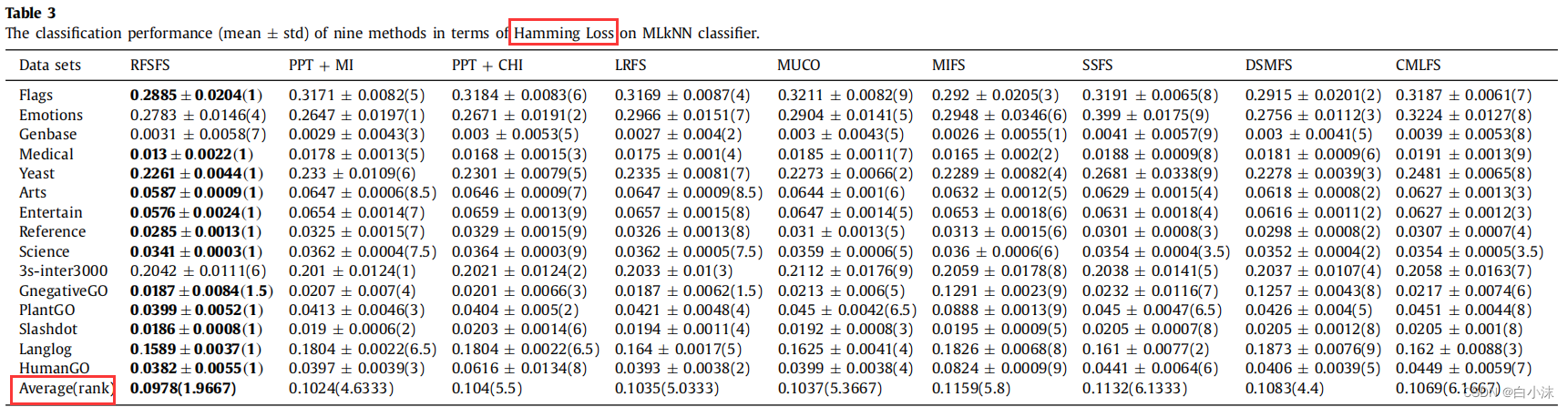
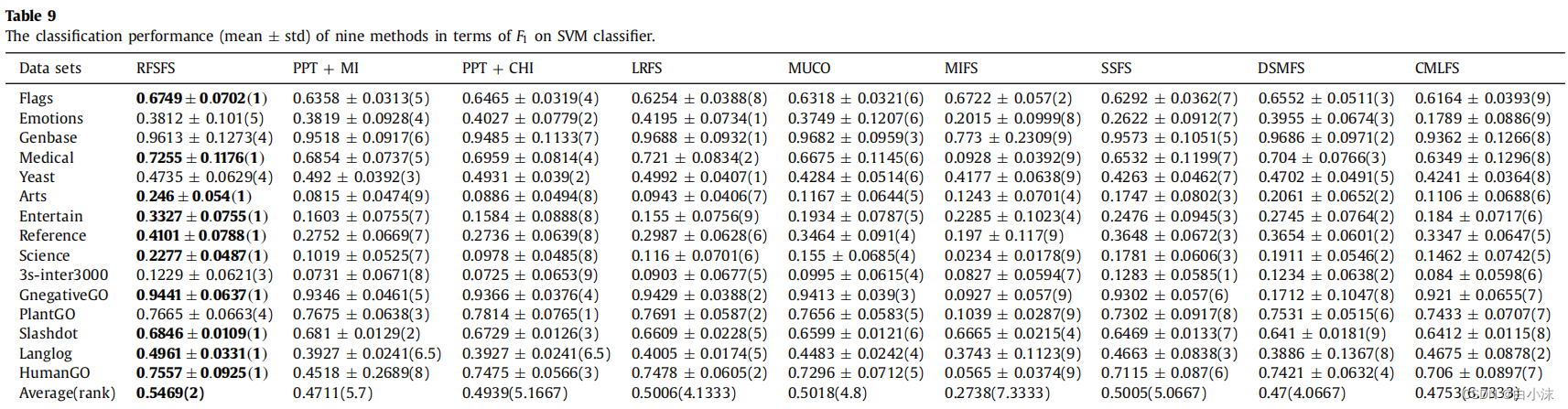
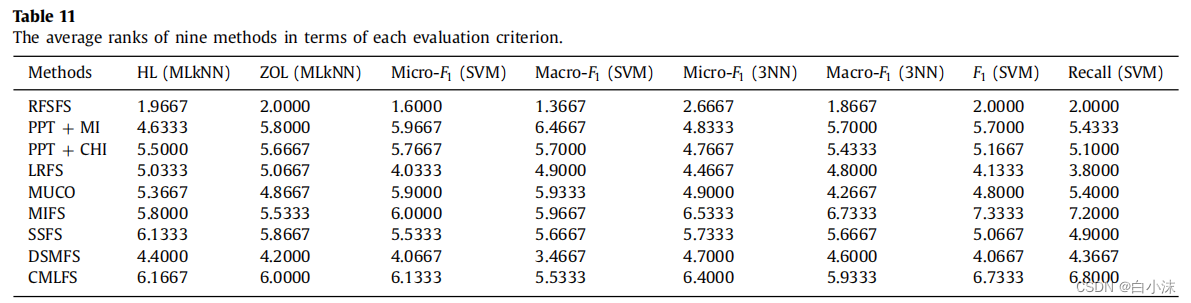
2.这个表格是对之前计算各个算法的平均序值的一个总结
3.利用以下公式计算FF值和Critical value【α = 0.05】的值
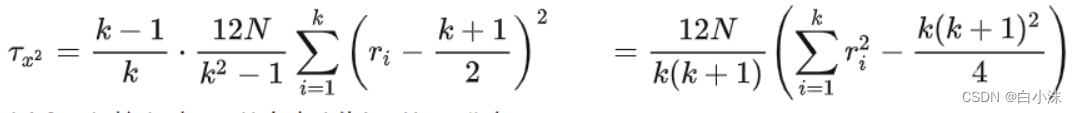
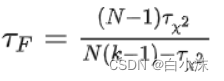

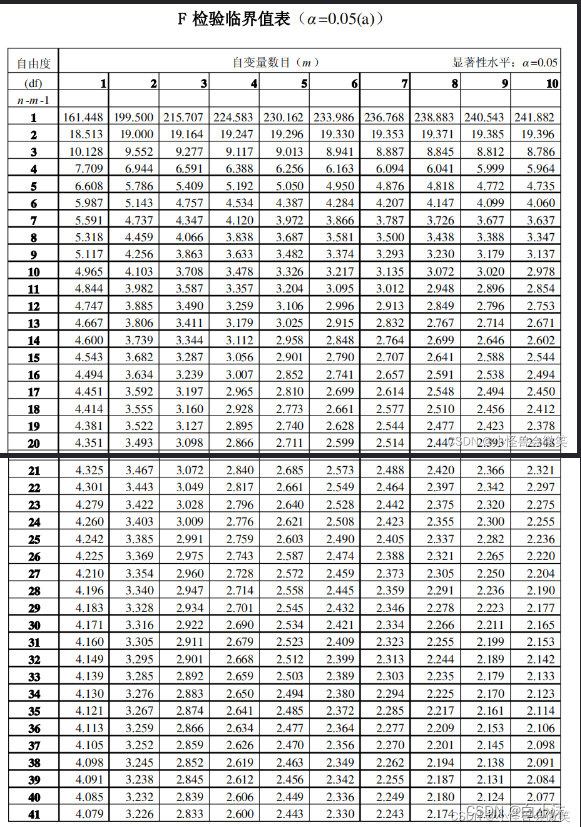
这里K=9,N=15,服从自由度为K-1=8,N-1=14,【K-1=8】*【N-1=14】=112的分布,值可以通过查表得到。下面是部分表格内的值
根据上面的公式计算和查表就可以得到下面这张表格的内容了
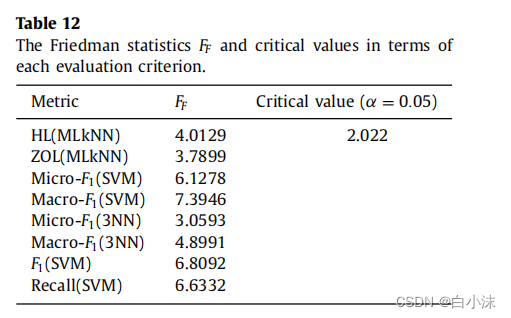
可以发现FF的值比Critical value值大很多,所以拒绝H0原假设:at the significance level α = 0.05, the null hypothesis is rejected (this hypothesis denotes all compared methods have the same performance.).
采用后续检验,Nemenyi Test检验或者Bonferroni-Dunn test检验,找到对应K=9的值,如下表:


通过公式计算出CD的值:
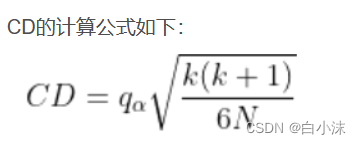

3.绘制检验图
可以借助代码或者手绘
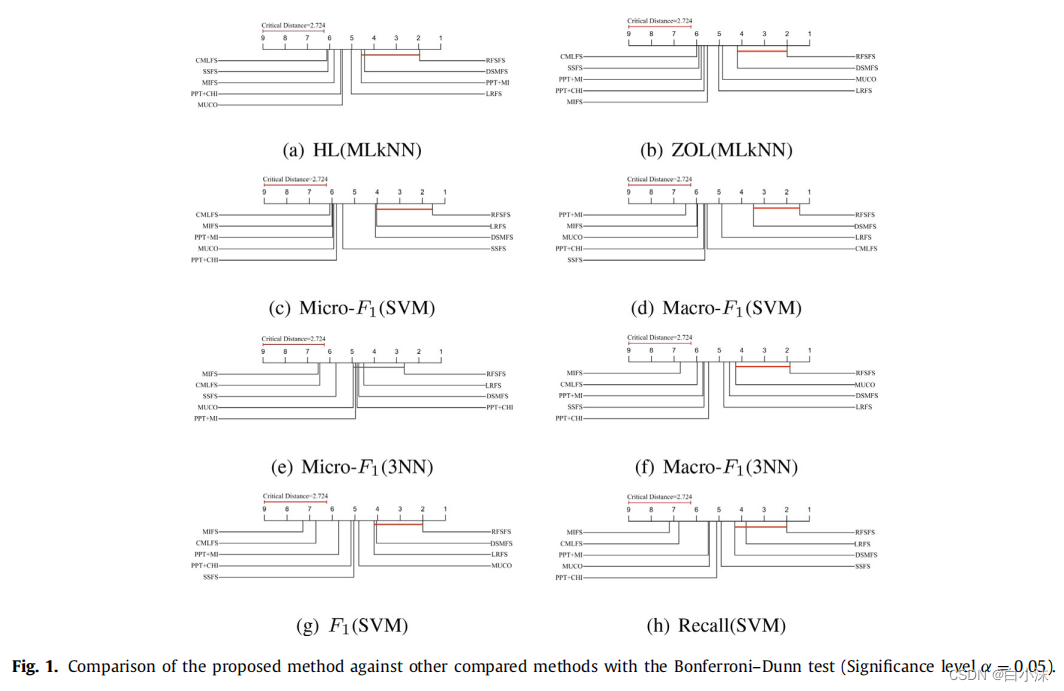
参考文章:
https://liuwentao.blog.csdn.net/article/details/126967205?spm=1001.2014.3001.5506















 4150
4150











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









