






【本文仅供学习记录,概无其他用处,一些图片资源来自网络,侵删】
《Adaptive Federated Learning in Resource Constrained Edge Computing Systems》
《资源受限边缘计算系统中的自适应联邦学习》
下载地址:https://sci-hub.3800808.com/10.1109/jsac.2019.2904348
- 摘要
这是一篇高引的CCFA类论文,数学证明很严谨、对不同情况的分析很全面、论文撰写很注重细节。
本文分析了边缘计算环境中Non-IID数据上联邦学习的收敛界限(convergence bound),使用这个理论界限,提出了一种控制算法来实现局部更新和全局聚合之间的理想折衷,以便在资源预算约束下最小化损失函数。
- 研究背景
物联网和社交网络应用快速发展,导致网络边缘生成的数据呈指数级增长。据预测,在不久的将来,数据生成速率将超过当今互联网的容量。
由于网络带宽和数据隐私问题,将所有数据发送到远程云是不切实际的,通常也是不必要的。因此,研究机构估计,超过90%的数据将被存储,并在本地处理。
移动边缘计算(MEC)的新兴技术使具有全球协调的本地数据存储和处理成为可能,其中边缘节点(如传感器,家庭网关,微型服务器和小型蜂窝)配备了存储和计算能力。多个边缘节点与远程云协同工作,以执行涉及本地处理和远程协调/执行的大规模分布式任务。分析大量数据并获得有用的信息,以便检测、分类和预测未来事件,通常应用机器学习技术,而在资源受限的 MEC 系统上执行分布式机器学习具有挑战性。于是在本文提出了一支算法来确定全局聚合的频率,以便有效使用可用资源。
- 问题场景
边缘计算场景,资源受限边缘计算系统。
- 科学问题建模(创新点)
边缘计算中使用联邦学习训练机器学习模型,首先得从理论上证明模型在Non-IID数据上的收敛性,这是在边缘计算中使用联邦学习的一个假设和前提,很多论文忽略这个前提其实是不够严谨的。本文作者给出了理论证明,众所周知从理论上证明一个经验上认为是正确的问题是很复杂的,只有理论证明是对的才可以放心使用。
- 研究方法
本文分析了边缘计算环境中Non-IID数据上联邦学习的收敛界限(convergence bound),使用这个理论界限,提出了一种控制算法来实现局部更新和全局聚合之间的理想折衷,以便在资源预算约束下最小化损失函数。
在边缘计算中,如何利用给定数量的资源来最小化联邦学习中的损失函数,不考虑通讯的情况下,问题的关键在于确定 T 和 τ 的值,其中 τ 代表本地节点更新的epoch数目, T 代表节点处总共的迭代次数。文章提出一种自适应的算法来计算 τ 。
- 实验
本文对比了三个Baseline,用了两种模型优化方式,采用了四种网络结构,三个数据集,每个数据集使用了四种方式划分。
三个Baseline:
(a)集中梯度下降 ,其中整个训练数据集存储在单个边缘节点上,并使用标准(集中)梯度直接在该节点上训练模型下降程序;
(b)典型联合学习方法,相当于在我们的设置中使用固定(非自适应)τ 值;
(c)同步分布式梯度下降,相当于在我们的设置中固定 τ = 1。
两种优化方法DGD和SGD:
我们在实验中同时考虑了 DGD(确定性梯度下降)和 SGD,以评估所提出算法的普遍适用性。
四种网络模型和三个数据集:
模型:我们在五个不同的数据集上评估四种不同模型的训练,代表各种各样的小型和大型模型和数据集。因为可以预期所有这些变体都存在于边缘计算场景中。这些模型包括平方 SVM、线性回归、K-means 和深度卷积神经网络 (CNN)。SVM和线性回归的损失函数是凸的,而 K-means 和 CNN 的损失函数是非凸的。
数据集:CNN 在三个不同的数据集上使用 SGD 进行训练,包括 MNIST-O,MNIST、MNIST-F。MNIST数据集与 MNIST-O数据集一样,但前者包含 60000 张CIFAR-10 数据集彩色图像(其中50000张用于训练,10000张用于测试)。
数据集采用四种划分方式:
方式1:每个数据样本被随机分配给一个节点,因此每个节点都有统一(但不完整)的信息。
方式2:每个节点中的所有数据样本都具有相同的标签。7 这表示每个节点具有非均匀信息的情况,因为整个数据集具有多个不同标签的样本。
方式3:每个节点都有整个数据集(因此是完整的信息)。
方式4:具有前半部分标签的数据样本与方式1 一样分布到前半部分节点。
实验结果:
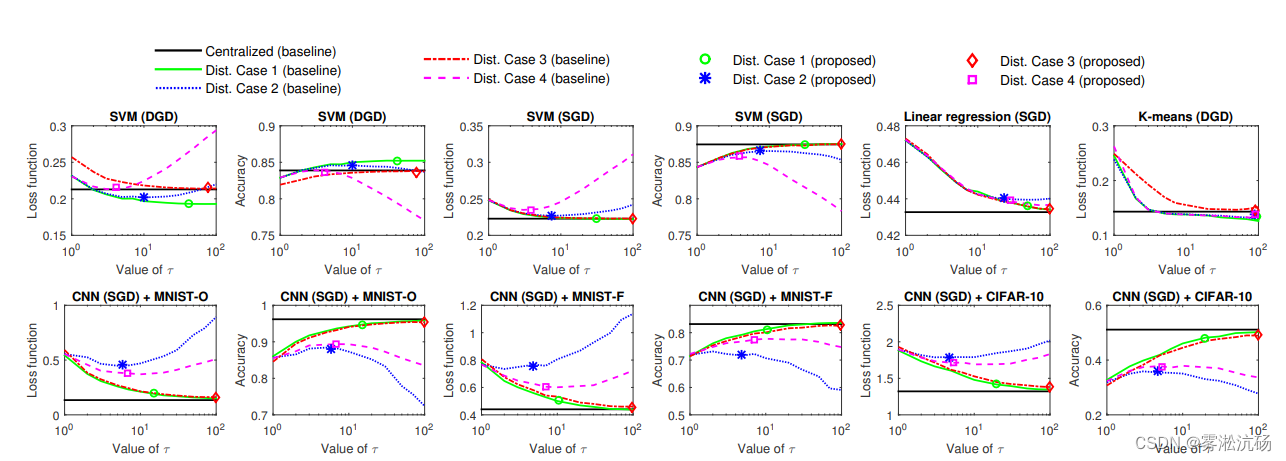
图为不同τ的损失函数值和分类精度。只有 SVM 和 CNN 分类器具有准确度值。曲线显示了具有不同固定 τ 值的基线的结果。
文章提出了自适应算法在资源约束情况下计算本地迭代轮次的最优值,所有在上图中最优值用一个点表示。左边第一列看,使用自适应算法寻找到的值,总能使损失函数最小,或出现在拐点附近;左边第二列看,适应自适应算法寻找到的值,总能使模型的acc最高,或出现在拐点附近。
文章的其他实验对损失值、准确率、不同边缘节点数目、不同时延约束的情况都做了讨论,十分全面。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









