






联邦平均算法(FederatedAveraging algorithm)是经典的联邦学习算法,来自于联邦学习原始论文中给出的FedAvg的算法框架。原始联邦学习论文地址:https://arxiv.org/pdf/1602.05629.pdf
联邦学习特点:适合机器学习任务,数据不出客户端,通过聚合本地计算来学习共享模型,更新模型梯度。联邦学习具有隐私优势,每次只更新和传输模型梯度;插入一些无关数据对模型训练影响不大而对攻击者造成麻烦时,可以使用这种差分隐私的方法提高联邦学习隐私性。
原始联邦学习论文三大贡献:
(1)将移动设备分散数据的培训问题确定为一个重要的研究方向;
(2)选择可应用于该设置的简单实用的算法;
(3)对提议的方法进行广泛的实证评估。
适合联邦学习的问题:图像分类,预测那些图片在未来会被查看共享;语言模型,改善语音识别和触屏文本输入。
分布式学习与联邦学习对比
分布式学习是一个分布式进行的大型神经网络,仍可能集中于几大数据中心;
联邦学习关心数据本身、数据的特点,如:非独立同分布、非平衡数据、大规模分布、通信效率问题等对联邦学习模型进行改进。
解决办法:通过增加客户单并行性和增加客户端计算来降低通信。分布式一致性算法可以训练非独立同分布数据
联邦学习与普通集中学习的区别:
普通集中化学习:定义为简单的模型梯度平均
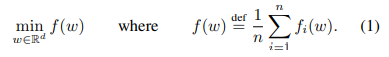
联邦学习:每次选取的用户不同,进行加权平均

FedSGD与FedAvg的区别与联系:
深度学习大部分都是基于SGD算法,在SGD算法上进行的优化改进。所以SGD可以简单直接用于联邦学习
FedSGD:每一轮通信随机选择部分客户端进行单批次梯度计算, 首先根据本地数据和当前全局模型进行一次梯度下降计算本地梯度,然后服务器加权平均聚合这些梯度形成新一轮全剧模型。
FedAvg:使用FedSGD的训练方式,但是在本地进行多次训练。
FedAvg有三个控制参数C、E、B(其余为本地参数):
K:表示客户端个数
C: 每轮执行计算的客户端比列
E: 每一个客户端对本地数据训练次数(本地更新次数)
B: 客户端批大小,表示每一次本地更新时的数据量,我们设置B = ∞为单批次,即一批次训练所有本地数据;显然,FedSGD对应于B = ∞,E = 1
η:表示学习率
我们先用中文表述一下算法流程:
服务器:
初始化参数
在每轮训练中:
分发:从K个客户中随机取m个,放入集合St,其中m是C与K的乘积,可见是按比例C选取的,如果c*k小于1,那就只选一个客户端
聚合:接受m个传回的参数w,对他们聚合【加权平均】,变为wt+1
客户端:
St内客户划分自己的数据集,每一块大小都为B
在每轮本地训练中:
在每块数据中:
算出该块数据损失梯度,然后进行梯度下降更新,得到新的本地权重
新的本地权重=是本地权重-梯度x学习率
Return w to 服务器
论文中的伪代码如下:

算法初始化参数选择:
联邦学习中最重要的是本地数据结合参数,训练分散在客户端的数据,参数有两个选择:
- 每个客户端自己先训练,得到参数,作为初始参数,这会导致不同客户端初始参数各异
- 使用共享的所有客户端相同的参数,会导致所有客户端初始参数相同
实验证明共享初始化参数可以减少总训练损失,推测原因可能是客户端训练过拟合局部数据集;而且在聚合梯度时,原始的平均聚合方法也出奇的好。
实验:
论文后期为了显示联邦学习算法的优越,做了好几个实验,这里选了两个有代表性的。没搞清楚代码,盲目分析结果也没有太大收获,所以在亲手实验后再更新实验结论吧。
源码地址:https://github.com/WHDY/FedAvg
说明:MNIST是一个手写体数字的图片数据集,该数据集来由美国国家标准与技术研究所(National Institute of Standards and Technology (NIST))发起整理,一共统计了来自250个不同的人手写数字图片,其中50%是高中生,50%来自人口普查局的工作人员。该数据集的收集目的是希望通过算法,实现对手写数字的识别。
实验一:训练MNIST数据集,对应的数字是几
实验二:训练莎士比亚作品集,读完每一行单词后预测下一个单词

















 6469
6469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









