









序列到序列学习:输入和输出都是长度不同的序列
引出Attention
传统的机器翻译是,将“机器学习”四个字都学习之后,拿着最后一个编码的信息去进行翻译。但是有个问题,就是在进行翻译的时候,“学习”两个字对“机器”翻译成“machine”并没有什么帮助。我们希望在进行前两个字翻译的时候,包含的学习的信息只有“机器”这两个字。
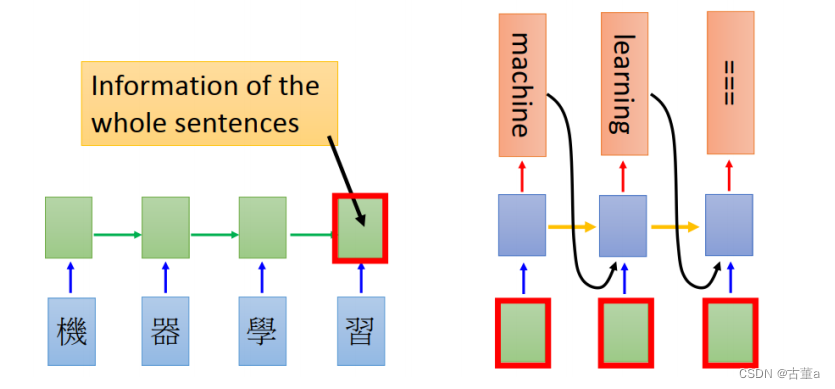
就是很多时候,特别当序列很长很长的时候,最后一个总编码,里面可能把前面信息都丢掉了,如果我有一些注意力机制的时候,我在翻译不同的词的时候,用这序列里面不同的位置的那些不同的位置的字,那可能信息翻译的准确度就会更高一些。
定义
注意力机制(Attention Mechanism)是一种用于增强神经网络模型在处理序列数据时的能力的技术。它在序列到序列(Sequence-to-Sequence)任务中特别常见,如机器翻译、语音识别和摘要生成等任务。
在传统的序列模型中,模型会对整个输入序列进行编码,然后使用编码的固定长度向量进行解码。然而,这种固定长度向量无法充分表示长序列中的所有信息,尤其是对于较长的输入序列,容易出现信息丢失或模糊的问题。
注意力机制通过在解码过程中动态选择性地聚焦(focus)输入序列的特定部分,使模型能够根据输入序列的不同部分调整其关注和权重分配。它允许模型根据当前解码步骤的需要,动态地分配不同的注意力或权重给输入序列的不同位置,以捕捉关键信息。
一般而言,注意力机制包含以下几个关键组成部分:
-
查询(Query):在解码过程中,当前的解码器状态会被用作查询向量,表示当前要生成的目标序列的部分。
-
键(Keys)和值(Values):输入序列经过编码器后得到的键和值。键和值的数量与输入序列的长度相同。
-
注意力权重(Attention Weights):通过计算查询向量与每个输入序列位置的关联程度,得到对应的注意力权重。注意力权重表示了解码器在解码时应该关注输入序列中的哪些部分。
-
上下文向量(Context Vector):将注意力权重与值进行加权求和,得到一个上下文向量。上下文向量是对输入序列的加权汇总,用于提供给解码器更丰富的信息。
注意力机制的引入使模型能够根据输入序列的不同部分调整其关注和重要性,从而提升模型的表现能力。它在序列任务中广泛应用,并取得了显著的效果改进。
Attention-based model
基于注意力机制的模型(Attention-based model)是一种神经网络架构,通常采用编码器-解码器(Encoder-Decoder)框架。编码器负责处理输入序列,并生成表示输入信息的隐藏状态或嵌入向量。解码器根据编码器的表示和先前生成的标记,生成输出序列。
注意力机制使解码器能够动态地聚焦输入序列的不同部分,根据当前解码步骤自适应地选择性地关注相关信息。这使得模型能够有选择地关注输入序列的重要部分,为解码器提供更丰富的上下文信息。
以下是基于注意力机制的模型的高级概述:
-
编码器:输入序列经过编码器网络处理,可以是循环神经网络(RNN)、卷积神经网络(CNN)或Transformer。编码器将输入序列转化为隐藏状态或嵌入向量,捕捉输入信息。
-
解码器:解码器网络以编码器的隐藏状态或嵌入向量为输入,并生成输出序列。在每个解码步骤中,解码器使用注意力机制关注输入序列的不同部分,以确定最相关的信息。
-
注意力计算:注意力机制计算注意力权重,表示每个输入位置对当前解码步骤的重要性或相关性。注意力权重是根据解码器的隐藏状态和编码器的隐藏状态计算得出的。
-
上下文向量:利用注意力权重对编码器的隐藏状态进行加权求和,得到上下文向量。上下文向量提供给解码器一个对输入序列相关部分的汇总表示。
-
解码和下一个标记生成:上下文向量、解码器的隐藏状态和先前生成的标记一起,用于生成输出序列中的下一个标记。这个过程迭代地重复,直到生成完整的输出序列。
假设我们存在一个可学习的向量,叫做
z
0
z^0
z0,还是机器学习这四个字,我希望翻译“machine”,我希望这个单词里面就是“机”和“器”,这两个的特征。希望他两个特征作为我的输入。则使用
z
0
z^0
z0和这四个字的向量
h
1
,
h
2
,
h
3
,
h
4
h^1,h^2,h^3,h^4
h1,h2,h3,h4进行匹配。然后输出一个
0
−
1
0 - 1
0−1的实数。
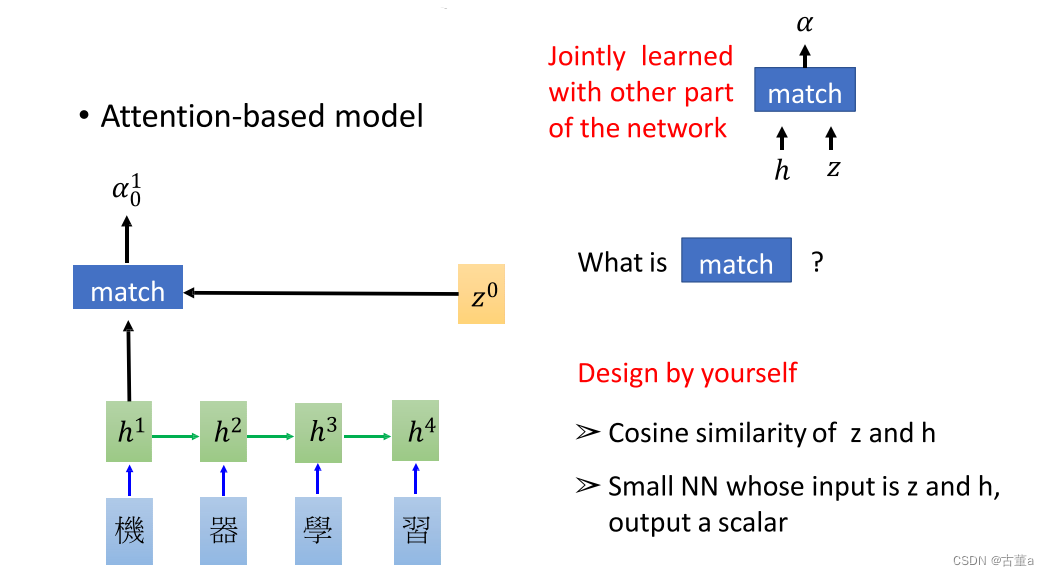
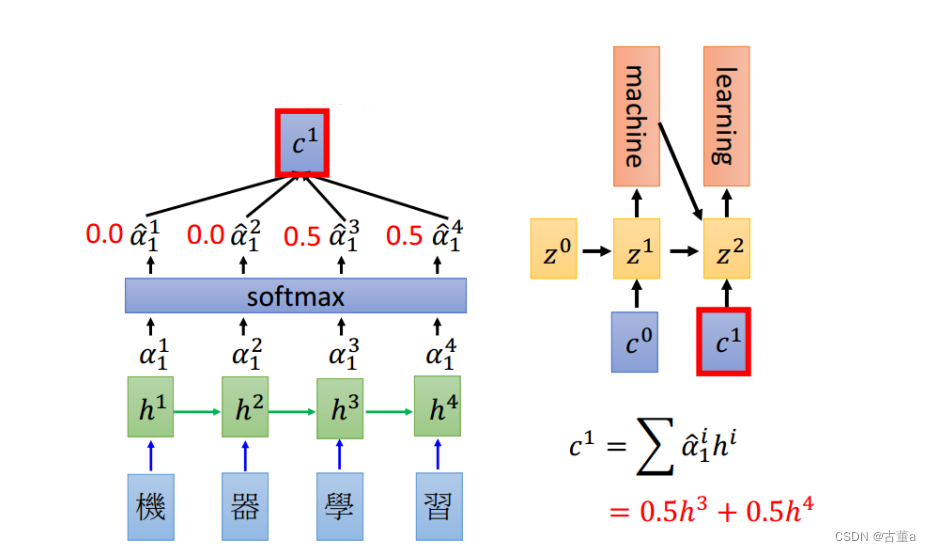
到我们真实做的时候,我们就直接算点乘,这个z向量,跟这个h向量,点乘,完了后得到一个值。
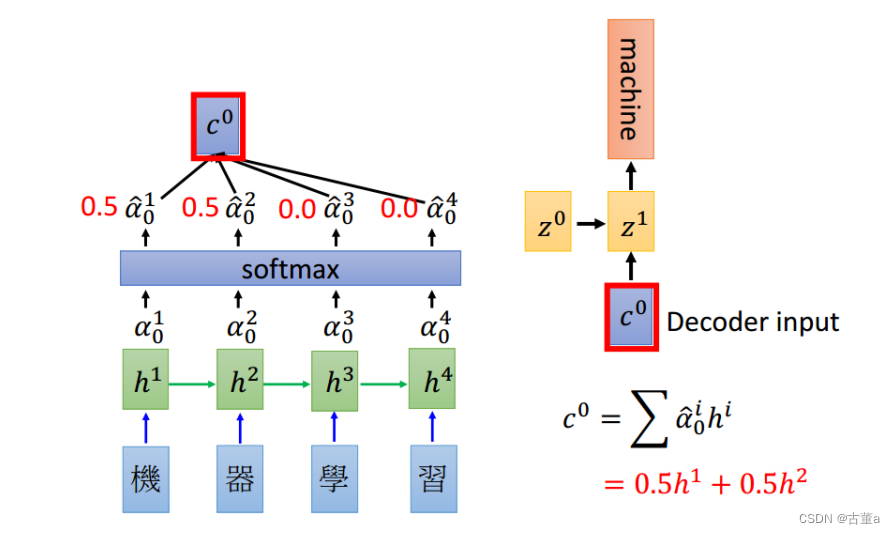
z
0
z^0
z0与四个h向量点乘后,得到四个值。然后使用softmax进行概率化,这四个数值概率化后总和为一,我们希望这个总和以后得到这样一组权重。这四个权值分别拿来跟四个字的向量进行相乘,我的总向量就是由权值和他对应的编码相乘。
因此在翻译“machine”的时候,特征里面只包含 h 1 , h 2 h^1,h^2 h1,h2。
同理,再把
z
1
z^1
z1拿出来,跟四个h向量进行点乘,也能得到一组权值。
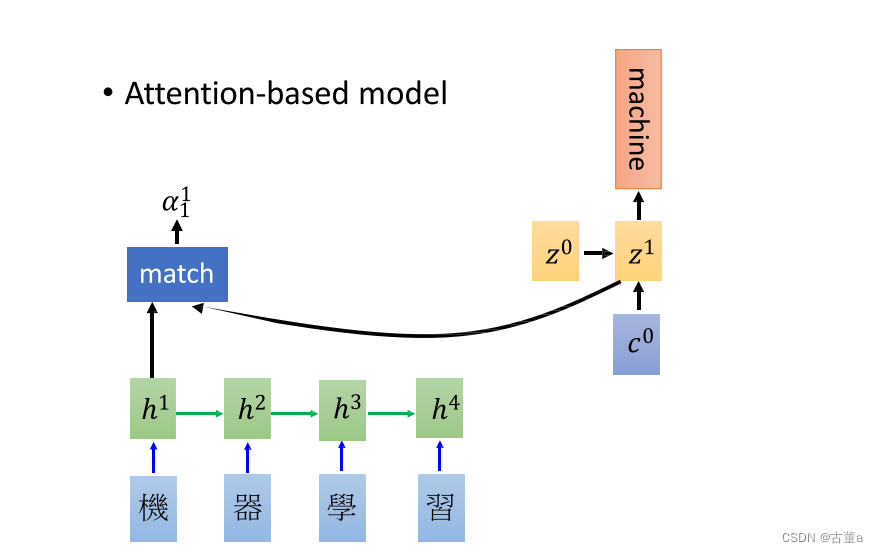
因此在翻译“learning”的时候,特征里面只包含
h
3
,
h
4
h^3,h^4
h3,h4。
当然最后这个在这种预测任务里面 ,还是要加一个终止符。
就输入来说, c 0 c^0 c0和 c 1 c^1 c1就跟我们原来不一样,原来是把混合到最后一个时刻的都拿出来 ,现在不一样,最后一个时刻确实是包含着前面时刻,但是我不光用最后一个时刻,我还用前面这时刻的,只用attation了以后,我这个时候就更注重前面时刻的信息。
注重在我关注的哪个点。我就注重哪个点的信息
通俗解释
当我们处理信息时,往往需要选择性地关注某些部分而忽略其他部分。类比于人类的注意力,注意力机制就是一种模拟人类关注力的技术。
想象一下,当你在听某个人说话时,你会将注意力集中在他们的声音和表情上,而忽略其他背景噪音或其他人的讲话。这种集中注意力的能力使你能够更好地理解他们说的话并作出适当的回应。
在计算机模型中,注意力机制的作用类似。当模型处理序列数据时,比如一句话或一段文本,注意力机制能够帮助模型选择性地关注输入序列的不同部分,根据当前任务的需要给予不同部分不同的重要性。
具体而言,注意力机制通过计算每个输入位置与当前处理步骤的关联程度,得到对应的权重。这些权重表示了模型在解决当前问题时应该关注输入序列的哪些部分。根据这些权重,模型可以动态地调整对输入序列不同位置的关注程度,以捕捉到关键的信息。
注意力机制的好处是它能够帮助模型更好地处理长序列或复杂的信息。通过集中关注重要的部分,模型能够更准确地理解输入并做出更好的预测或生成结果。
应用在图像领域
图像字幕生成(image caption generation)
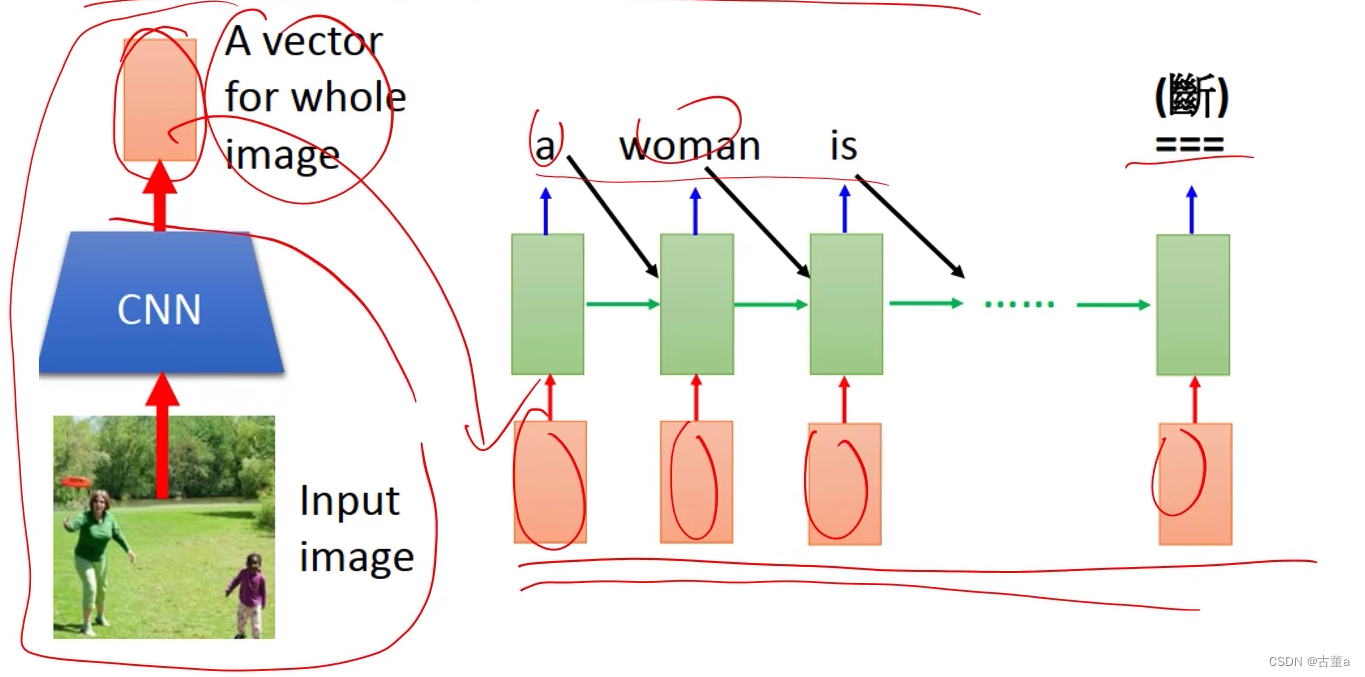
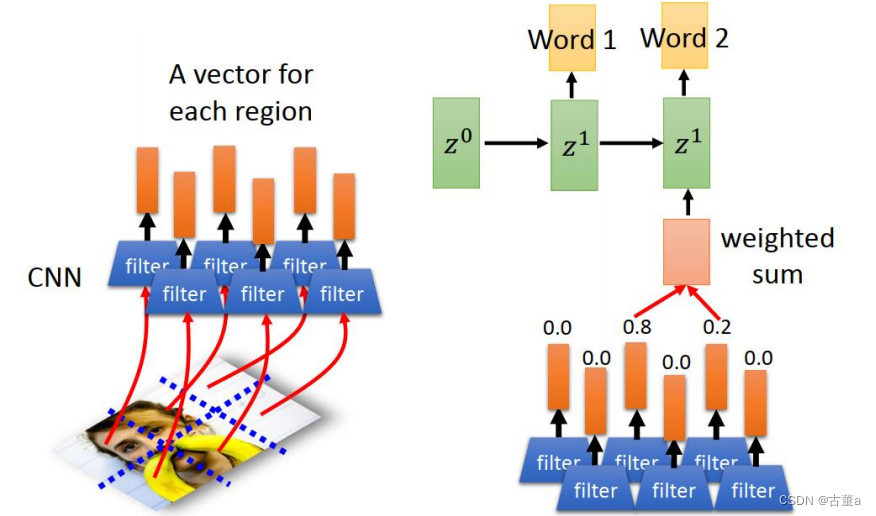
这一段文字产生可以用时序的,但是这个地方的这个特征,图像用cnn,可能提到一个特征,那时候这两个东西连接不到一起去 。使用attention机制。比如women这个单词,这个里面想跟图像的存在women这块区域有关,而跟其他那些地方没关。
怎么实现呢 ?
我们把图像打成六个区块或者八个或者16个或者24个或者64个区块,每个区块去提取一个特征,把这些特征按位置放起来 ,就得到了也是一个时序的东西。
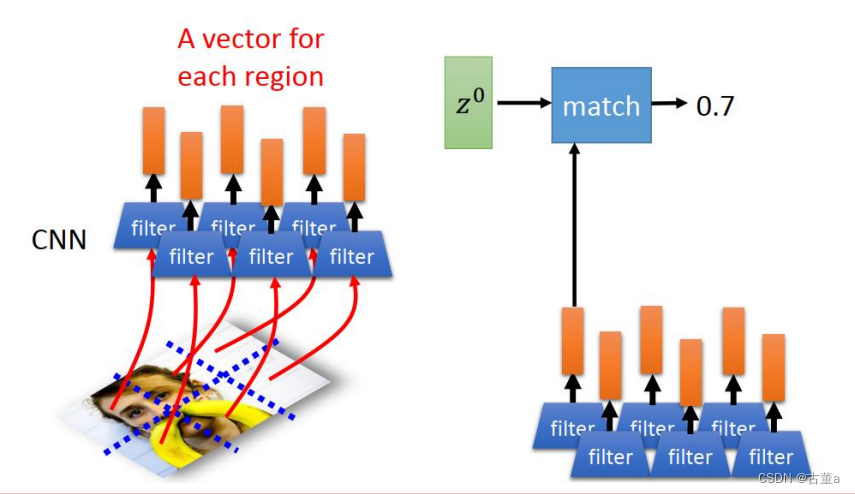
有了时序,使用
z
0
z^0
z0跟这个可以做match,match完了以后。z0跟这个所有特征做match得到一个权重。然后这个权重,就是由这些特征每个不同的图像位置的权重跟他的特征累加起来的。 然后去预测第一个单词
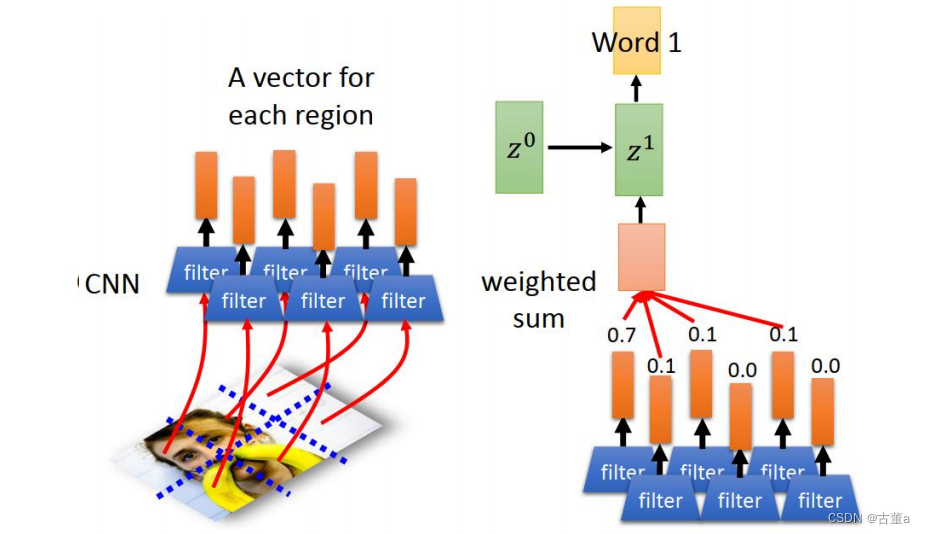
那反过来,第一个单词通过这几个权重,就能看出来这第一个单词跟图像的位置有关系
同理
z
1
z^1
z1继续进行match后预测
通过看这个单词看到的权重,就知道这个单词跟哪个区域相关。

当然权重不是只有一或者零,有的地方亮就是表示跟他相关度高,这暗的地方表示相关度低。
飞盘已经能知道,这个单词是靠图像的亮这块区域做的决定,狗是靠图像的这块区域做的
还有一些错误的,翻译都翻译错的了。

视频处理
把图像的一个视频序列,把图像的每一帧当做一个特征,每一帧是提取10个特征。
当把这个时间序列和这个语言序列,跟我的这个图像的时间序列就做对齐的时候,就做这种注意力相关的时候,发现单词和视频的某些帧有对应。
















 4430
4430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









