




 本文探讨计算机视觉中的注意力机制,尤其是软注意力在空间域和通道域的应用。空间域通过空间转换器提取关键信息,通道域通过权重分配关注重要通道。此外,还介绍了混合域的注意力机制,结合空间和通道域的优点,适用于深度残差网络。最后,简要提及了时间域注意力在视频分析中的应用。
本文探讨计算机视觉中的注意力机制,尤其是软注意力在空间域和通道域的应用。空间域通过空间转换器提取关键信息,通道域通过权重分配关注重要通道。此外,还介绍了混合域的注意力机制,结合空间和通道域的优点,适用于深度残差网络。最后,简要提及了时间域注意力在视频分析中的应用。
简介
计算机视觉(computer vision)中的注意力机制(attention)的主要是想让系统学会把注意力放在感兴趣的地方。具备注意力机制的神经网络一方面能够自主学习注意力机制,另一方面则是注意力机制能够反过来帮助我们去理解神经网络看到的世界。
近几年来,深度学习与视觉注意力机制结合的研究工作,大多数是集中于使用掩码(mask)来形成注意力机制。掩码的原理在于通过另一层新的权重,将图片数据中关键的特征标识出来,通过学习训练,让深度神经网络学到每一张新图片中需要关注的区域,也就形成了注意力。
注意力有两种,一种是软注意力(soft attention),另一种则是强注意力(hard attention)。
软注意力更关注区域或者通道,而且软注意力是确定性的注意力,学习完成后直接可以通过网络生成,最关键的地方是软注意力是可微的,这是一个非常重要的地方。可以微分的注意力就可以通过神经网络算出梯度并且前向传播和后向反馈来学习得到注意力的权重。
强注意力与软注意力不同点在于,首先强注意力是更加关注点,也就是图像中的每个点都有可能延伸出注意力,同时强注意力是一个随机的预测过程,更强调动态变化。当然,最关键是强注意力是一个不可微的注意力,训练过程往往是通过增强学习(reinforcement learning)来完成的。
为了更清楚地介绍计算机视觉中的注意力机制,这篇文章将从注意力域(attention domain)的角度来分析几种注意力的实现方法。其中主要是三种注意力域,空间域(spatial domain),通道域(channel domain),混合域(mixed domain)。
软注意力的注意力域
空间域(Spatial Domain)
设计思路:
空间域将原始图片中的空间信息变换到另一个空间中并保留了关键信息。
普通的卷积神经网络中的池化层(pooling layer)直接用一些max pooling 或者average pooling 的方法,将图片信息压缩,减少运算量提升准确率。
发明者认为之前pooling的方法太过于暴力,直接将信息合并会导致关键信息无法识别出来,所以提出了一个叫空间转换器(spatial transformer)的模块,将图片中的的空间域信息做对应的空间变换,从而能将关键的信息提取出来。

比如这个直观的实验图:
(a)列是原始的图片信息,其中第一个手写数字7没有做任何变换,第二个手写数字5,做了一定的旋转变化,而第三个手写数字6,加上了一些噪声信号;
(b)列中的彩色边框是学习到的spatial transformer的框盒(bounding
box),每一个框盒其实就是对应图片学习出来的一个spatial transformer;
c列中是通过spatial
transformer转换之后的特征图,可以看出7的关键区域被选择出来,5被旋转成为了正向的图片,6的噪声信息没有被识别进入。
spatial transformer其实就是注意力机制的实现,因为训练出的spatial transformer能够找出图片信息中需要被关注的区域,同时这个transformer又能够具有旋转、缩放变换的功能,这样图片局部的重要信息能够通过变换而被框盒提取出来。模型结构
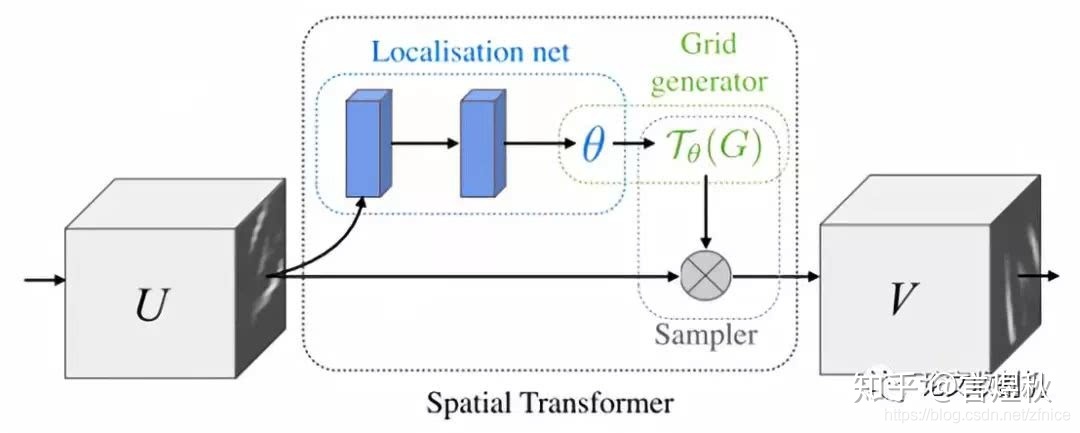
这是空
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2181
2181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









