







1. How Expressive are Graph Neural Networks?
图神经网络核心思想:节点使用神经网络聚合来自其本地网络邻域的信息生成节点嵌入。
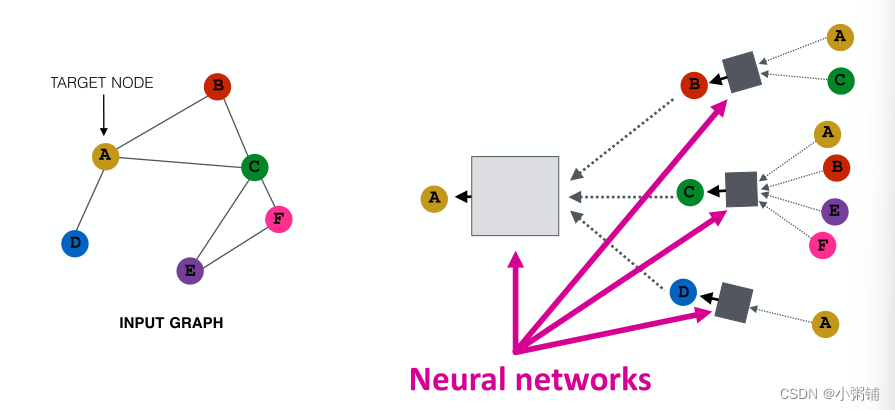
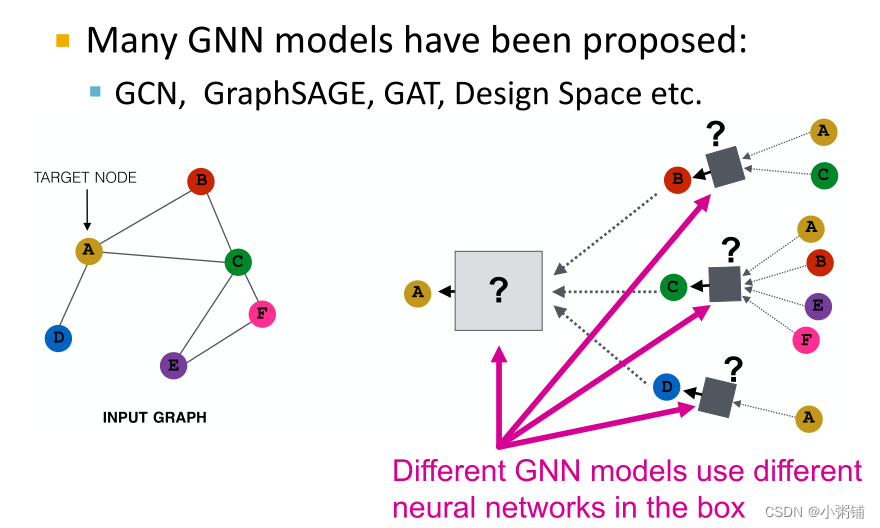
到目前为止已经提出了许多 GNN 模型(例如,GCN、GAT、GraphSAGE以及这类模型的整个设计空间):
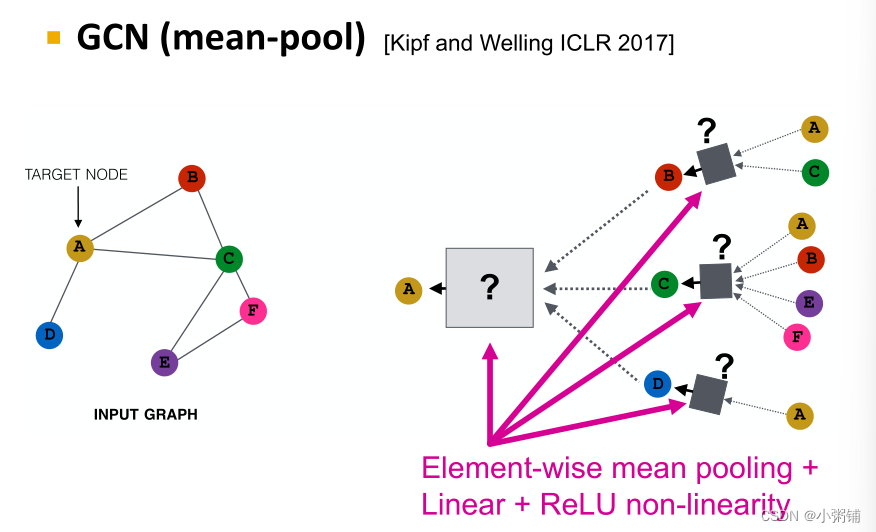
GCN:mean-pool + 线性变换 +ReLU
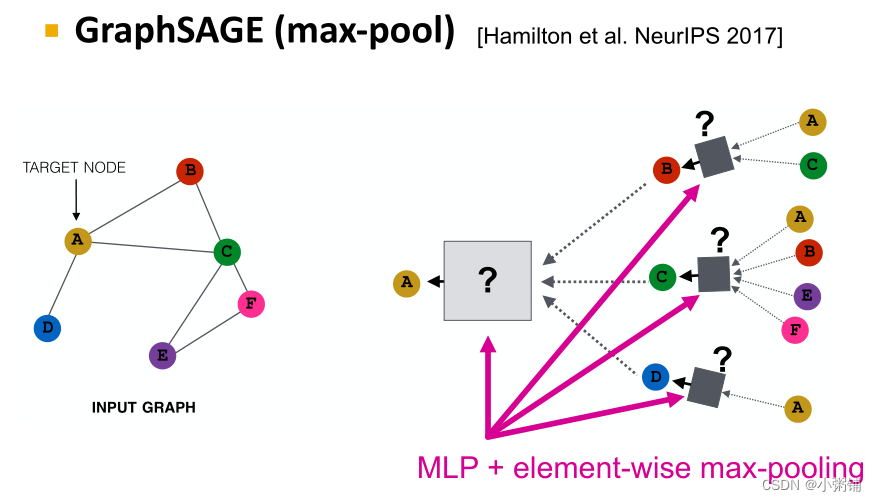
GraphSAGE:MLP + max-pool
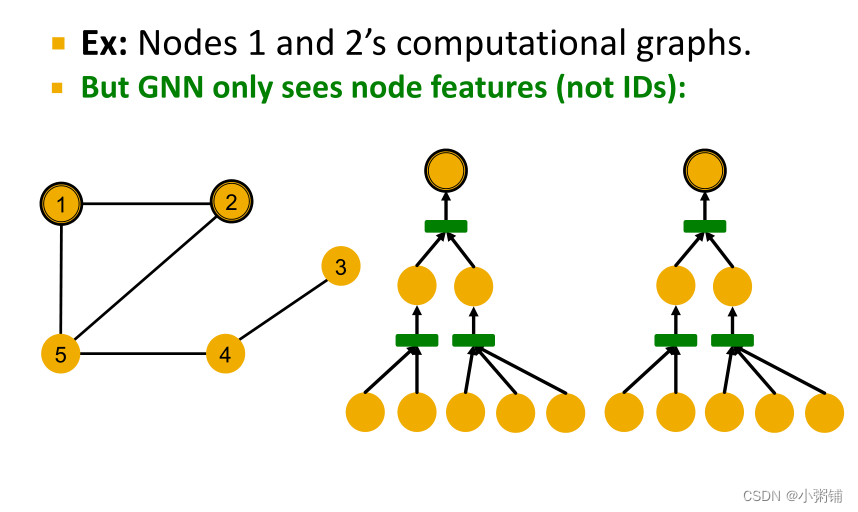
注意:在本节中,我们使用节点的颜色表示其特征向量,相同颜色的结点共享相同的特征
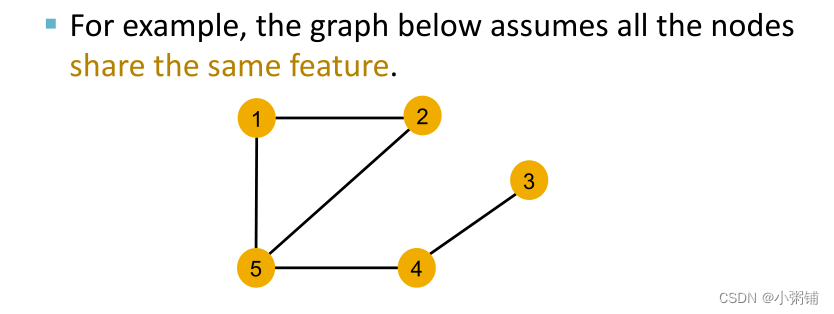
如果所有节点的特征向量相同,我们如何来区分不同的节点呢?利用图结构
我们考虑图中每个节点周围的局部邻域结构:
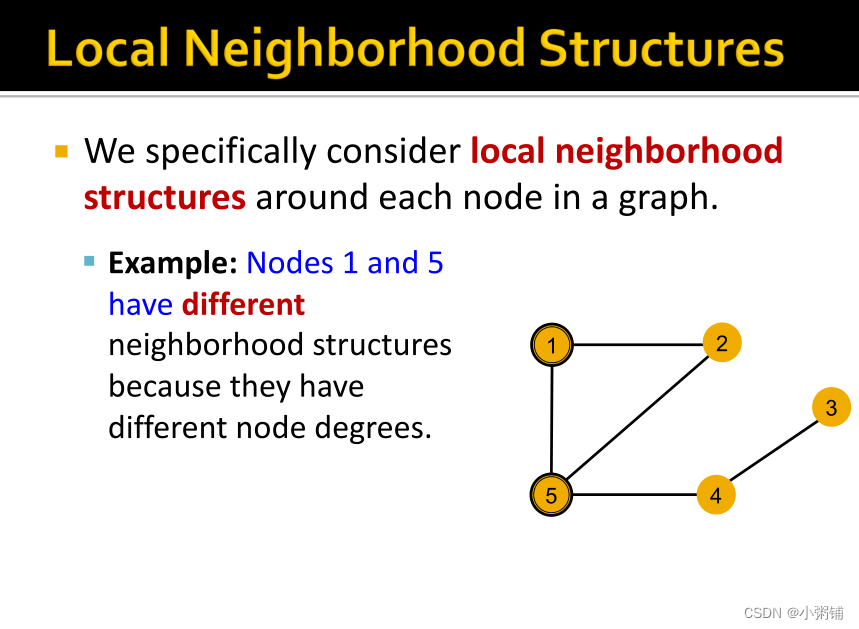
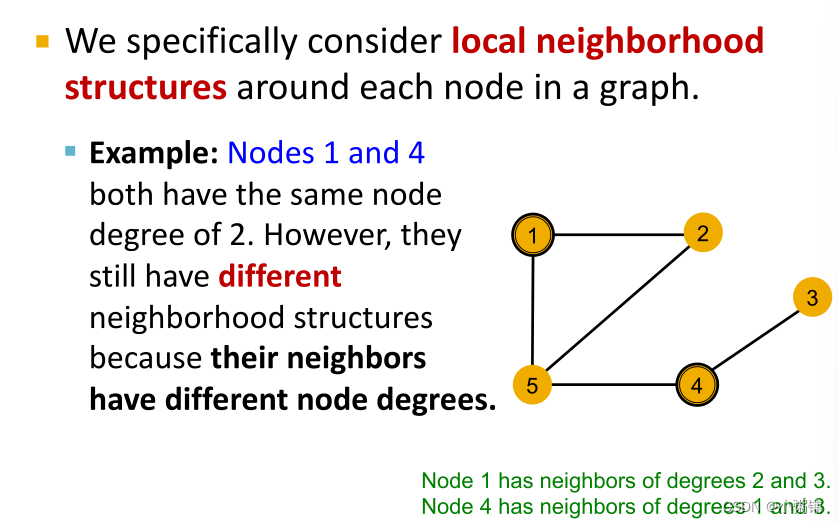
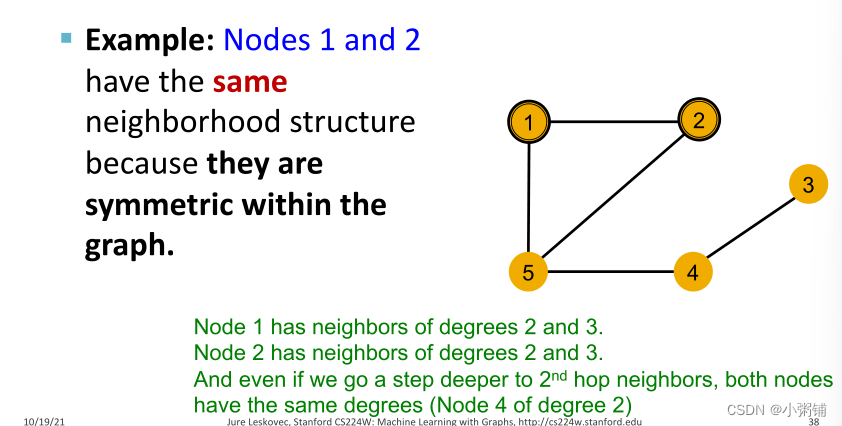
关键问题:GNN 节点嵌入能否区分不同节点的局部邻域结构?
-
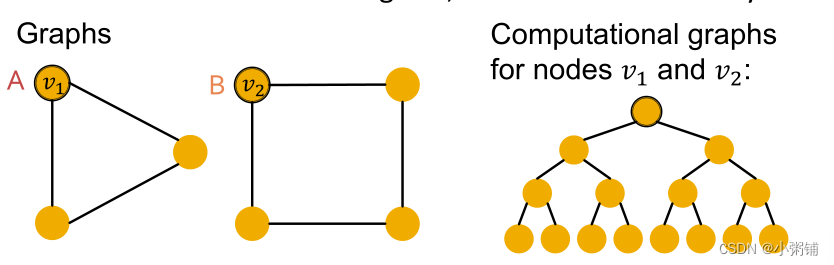
GNN通过计算图捕获节点的局部邻域结构并生成节点嵌入
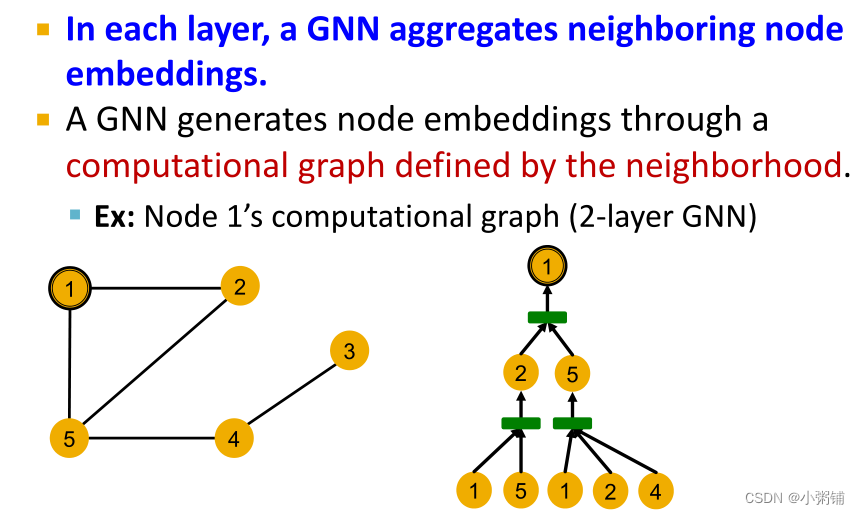
- 如果两个节点的计算图相同,那么这两个节点将嵌入到嵌入空间的同一点,GNN将无法区分这两个节点
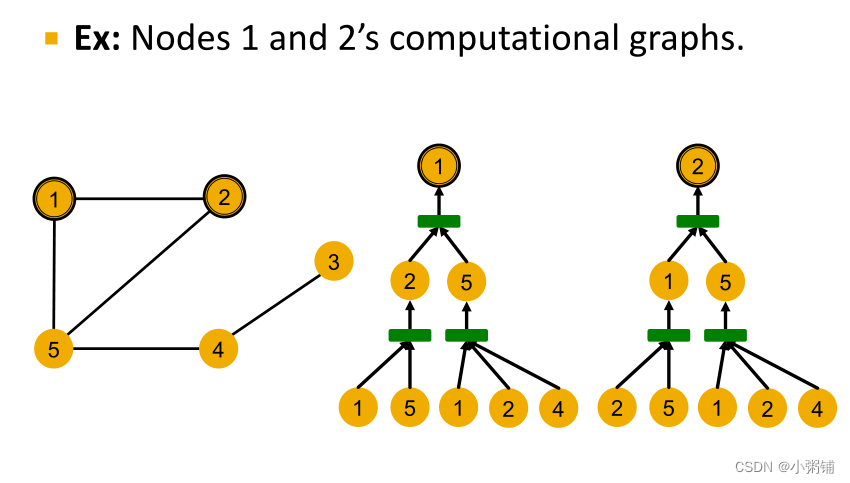
- 一般来说,不同的局部邻域定义不同的计算图,计算图与每个节点周围的有根子树结构相同。
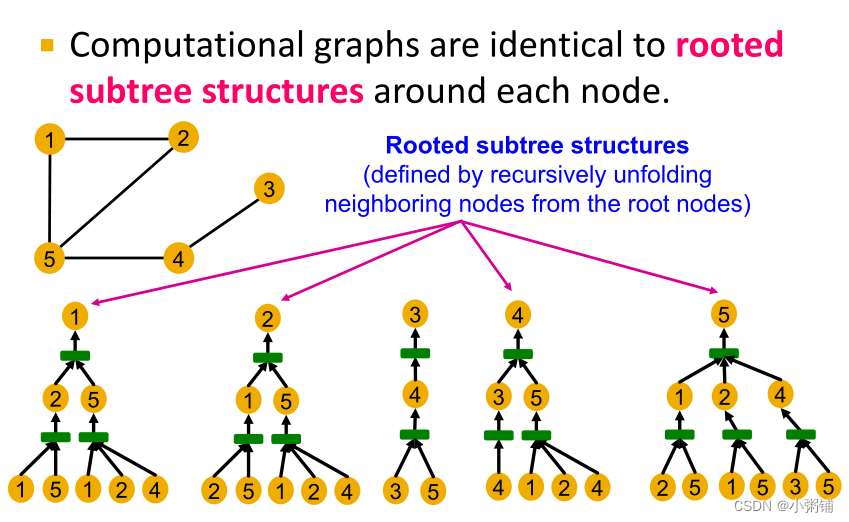
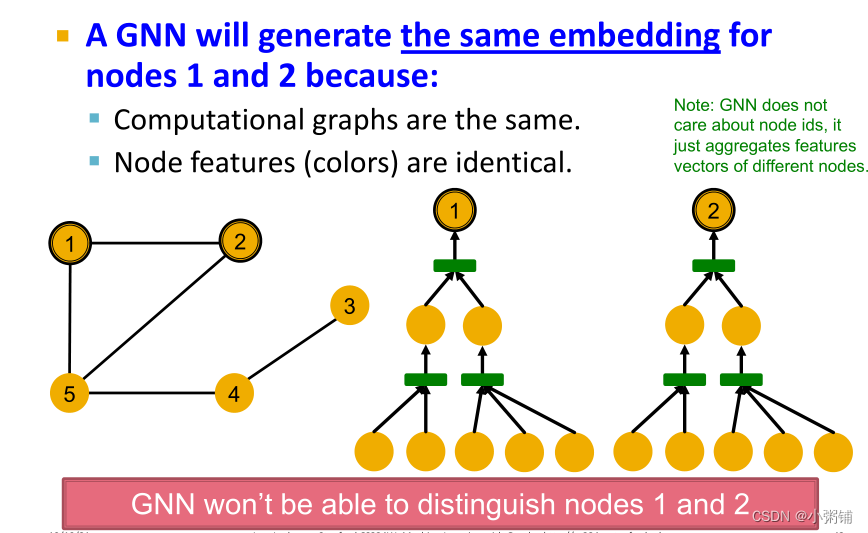
- 如果两个节点的计算图相同,那么这两个节点将嵌入到嵌入空间的同一点,GNN将无法区分这两个节点
-
单射函数(Injective Function)
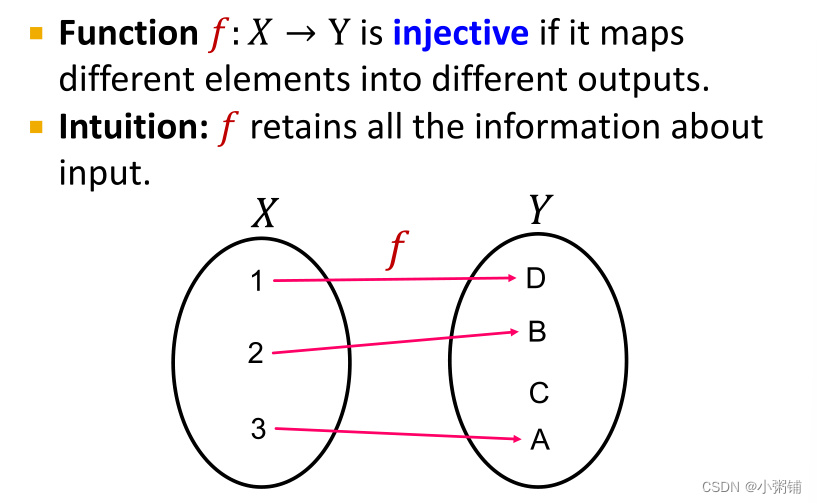
-
最具表现力的 GNN 将不同的有根子树映射到不同的节点嵌入中
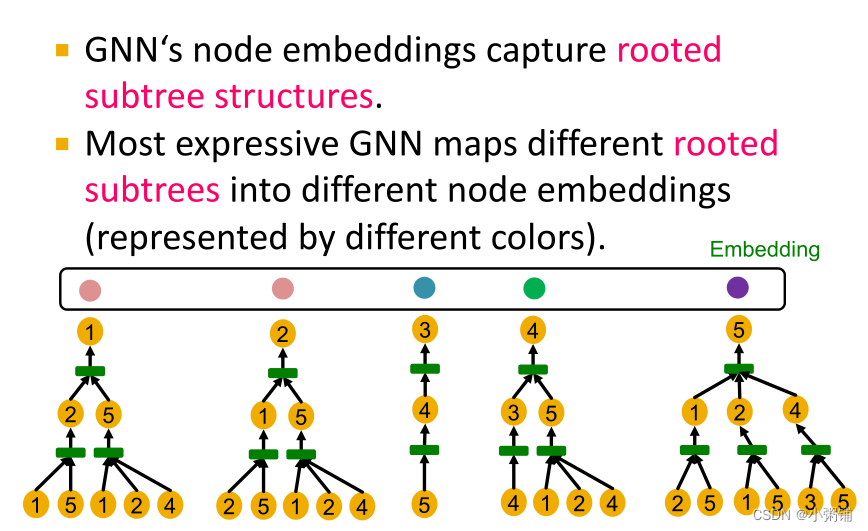
-
具体方法:先捕获树的单个级别的结构,然后利用递归算法捕获树的整个结构。
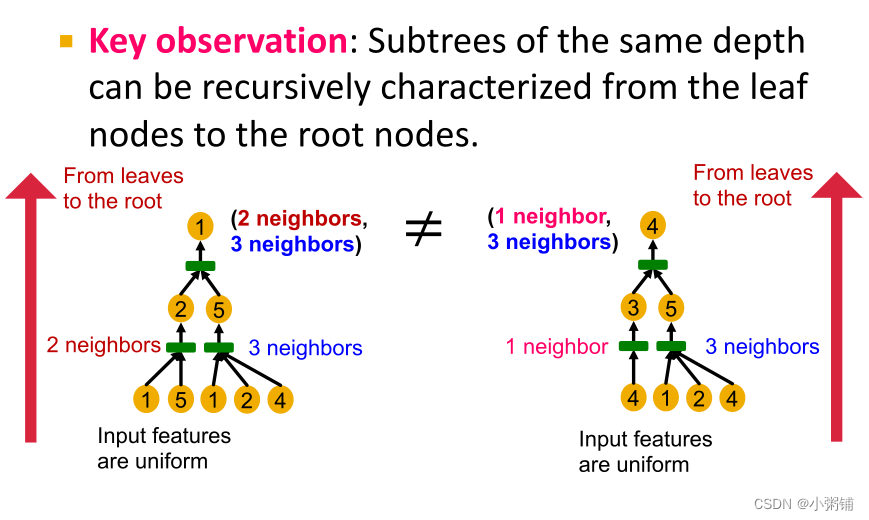
-
如果 GNN 聚合的每一步都可以完全保留相邻信息,则生成的节点嵌入可以区分不同的有根子树
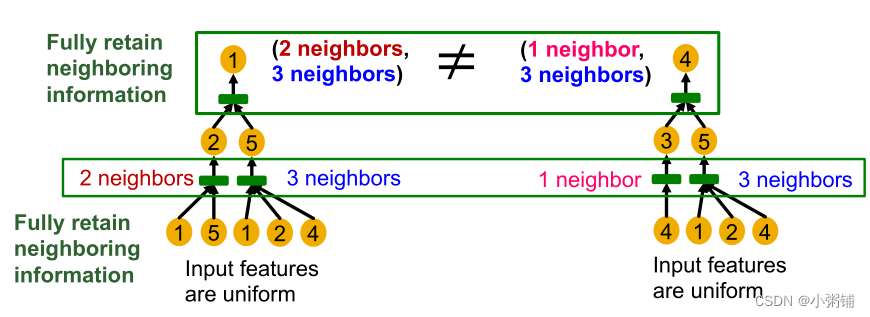
-
换句话说,最具表现力的 GNN 在每一步都会使用单射邻居聚合函数,将不同的邻居映射到不同的嵌入

-
重点在于,我们能否汇总来自孩子的信息并以某种方式存储这些信息将其传递给树中的父代。
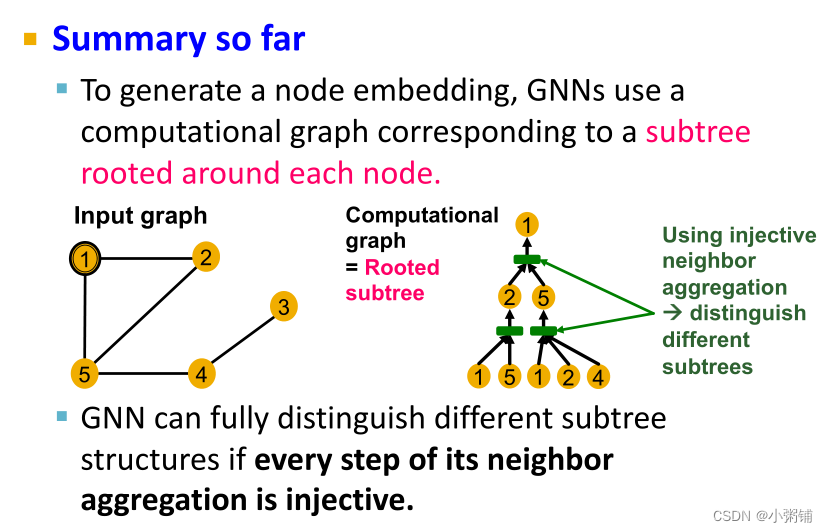
2. Designing the Most Powerful Graph Neural Network
到目前为止,我们可以得出结论:GNN 的表达能力可以通过它们使用的邻居聚合函数来表征
- 更具表现力的聚合函数会导致 GNN 更具表现力
- 内射聚合函数导致最具表现力的 GNN
- 邻里聚合是内射的, 意味着无论孩子的数量和特征是什么,都可以将它们映射到不同的输出,因此不会丢失任何信息
2.1 从理论上分析不同聚合函数的表达能力
邻居聚合可以抽象为多重集(具有重复元素的集和)上的函数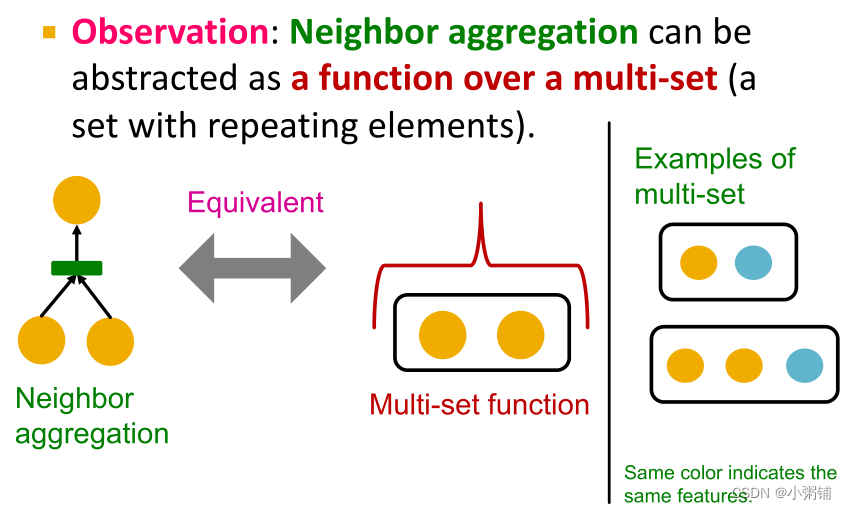
我们通过两个例子来具体讨论:
- GCN(mean-pool)
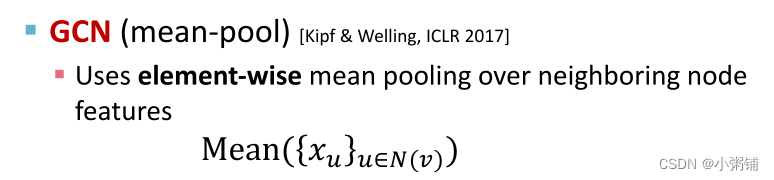
- GCN的聚合功能(平均池化层)无法区分颜色比例相同的不同多集
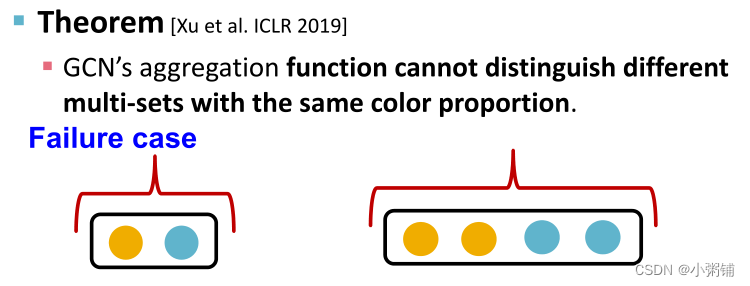
- 例子:为简单起见,我们假设节点颜色由 one-hot 编码表示
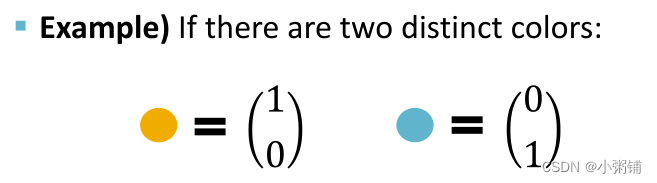
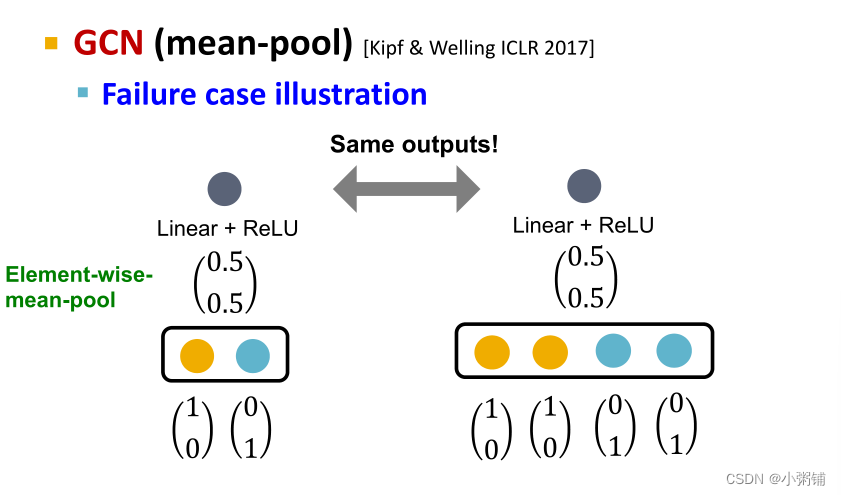
- 例子:为简单起见,我们假设节点颜色由 one-hot 编码表示
- GCN的聚合功能(平均池化层)无法区分颜色比例相同的不同多集
- GraphSAGE(max-pool)
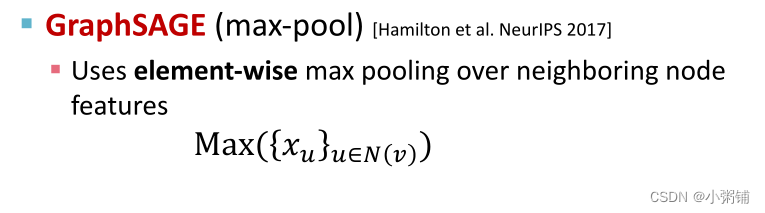
- GraphSAGE 的聚合函数无法区分不同的多集与同一组不同的颜色
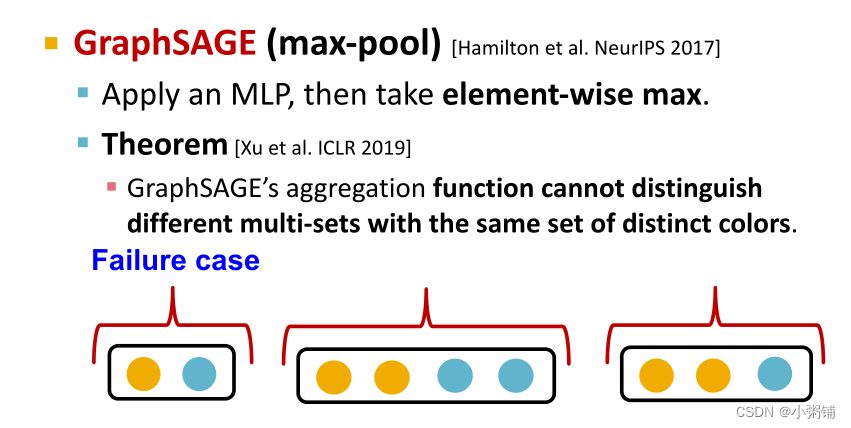
- 例子:
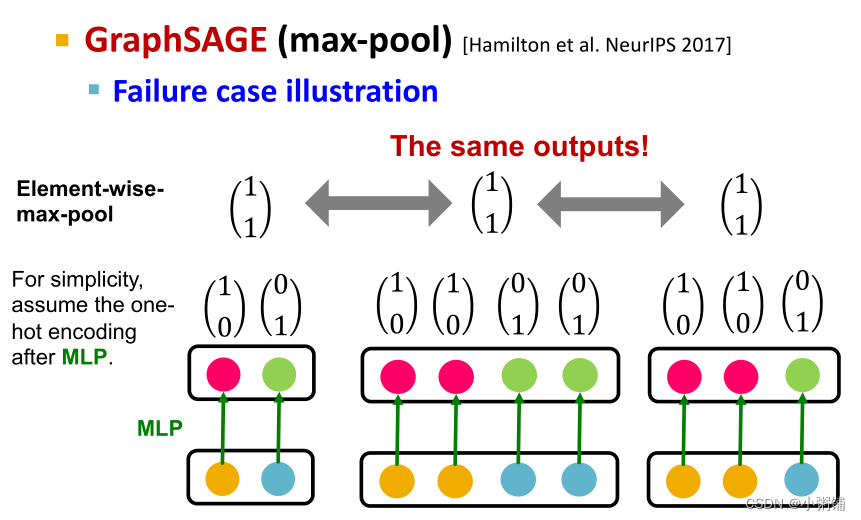
- 例子:
- GraphSAGE 的聚合函数无法区分不同的多集与同一组不同的颜色
- summary:
- GNN 的表达能力可以通过邻居聚合函数来表征
- 邻居聚合是多集(具有重复元素的集合)上的函数
- GCN 和 GraphSAGE 的聚合函数无法区分一些基本的多集,因此它们不是内射函数
- 因此,GCN 和 GraphSAGE 并不是最强大的 GNN
2.2 Designing Most Expressive GNNs
目标:在消息传递 GNN 类中设计最强大的 GNN
实现方法:通过在多集上设计单射邻域聚合函数来实现。在这里,我们设计了一个可以对单射多集函数进行建模的神经网络。
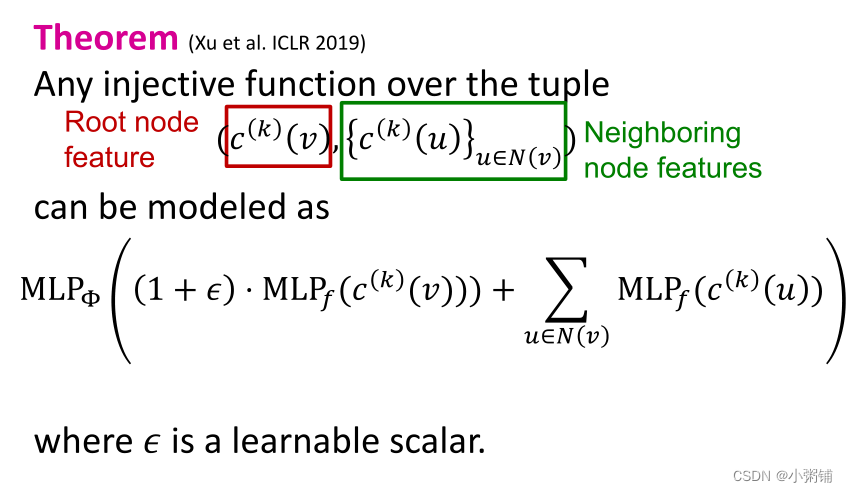
定理:任何单射多集函数都可以表示为如下的形式: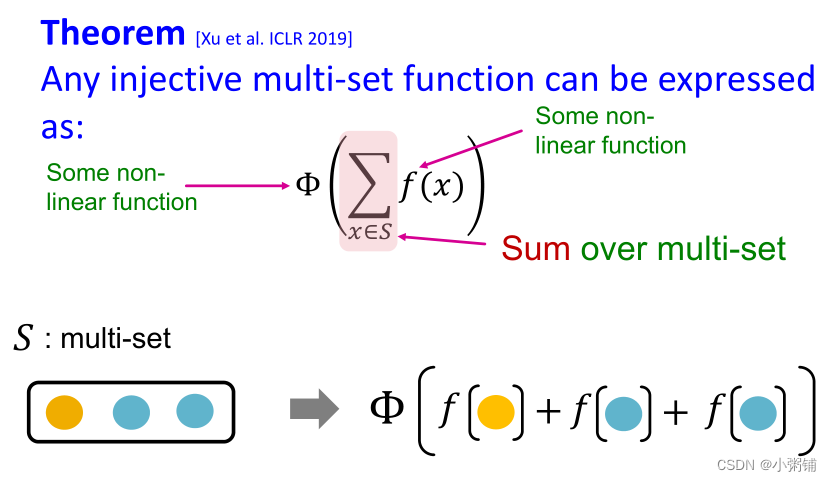
证明:
f
f
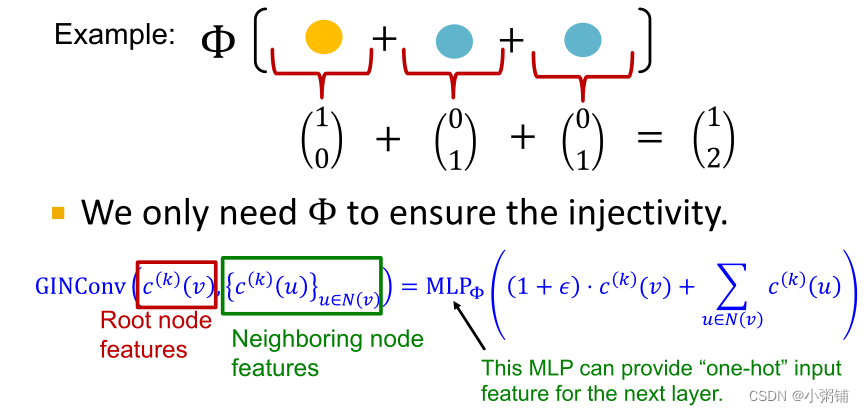
f产生颜色的独热编码。所以f对于不同的节点是内射的,因为它对不同的输入会产生不同的输出, one-hot 编码的总和保留了有关输入多集的所有信息。
-
如何定义 ϕ \phi ϕ 和 ϕ ( ∑ x ∈ S f ( x ) ) \phi(\sum_{x \in S}f(x)) ϕ(∑x∈Sf(x))中的 f f f函数
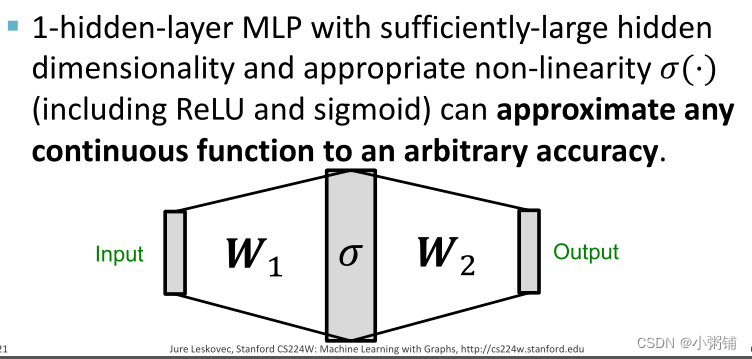
- 我们用多层感知机来定义
- 使用多层感知机的原因
- 万能逼近定理: 具有足够大的隐藏维数和适当的非线性
σ
(
⋅
)
\sigma(·)
σ(⋅)(包括 ReLU 和 sigmoid)的 1 隐藏层 MLP 可以将任何连续函数逼近到任意精度。
- 使用多层感知机建立的可以对任何单射多集函数进行建模的神经网络如下(实践中,100 到 500 的 MLP 隐藏维度就足够了):
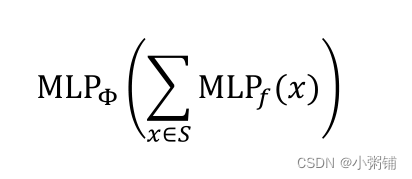
- 以此作为消息聚合和传播机制的图神经网络称为图同构网络(Graph Isomorphism Network GIN) ,理论上来说GIN 是消息传递 GNN 类中最具表现力的 GNN
- 理论:GIN的邻居聚合函数是单射的
- 无失败案例
- 我们用多层感知机来定义
-
GIN的完整模型:我们现在通过将 GIN 与 Weisfeiler-Lehman 图内核(获取图级特征的传统方法)相关联来描述 GIN 的完整模型
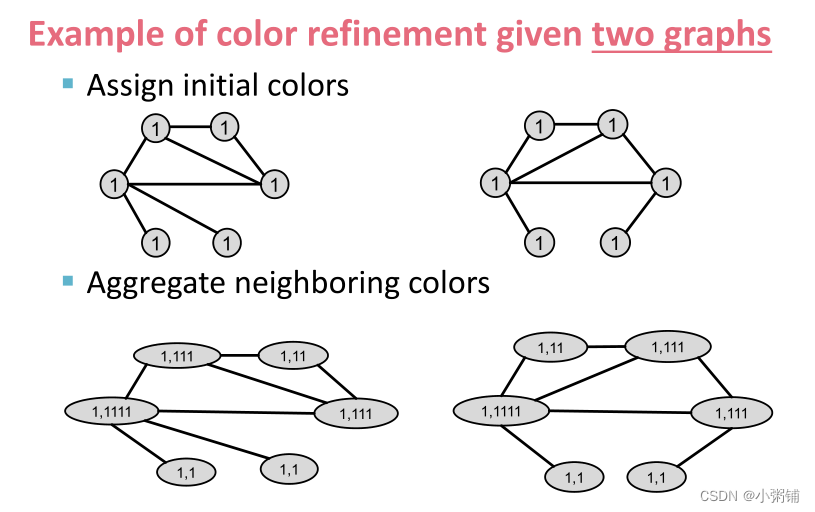
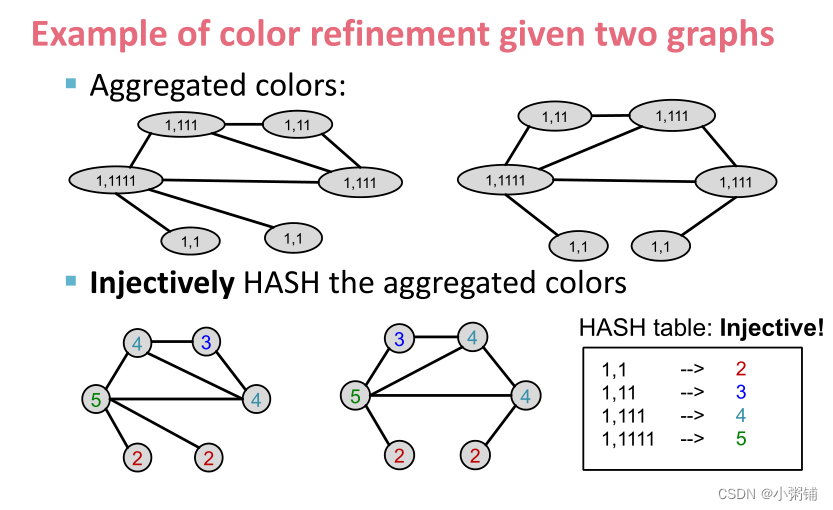
- WL 图内核(也称为Color refinement algorithm 色彩优化算法):首先对节点颜色进行初始化,然后根据邻居信息迭代地更新节点颜色,并通过哈希函数进行映射,反复迭代,直到达到稳定的着色为止。

- 收集邻居信息
- HASH映射
- Repeat until convergence
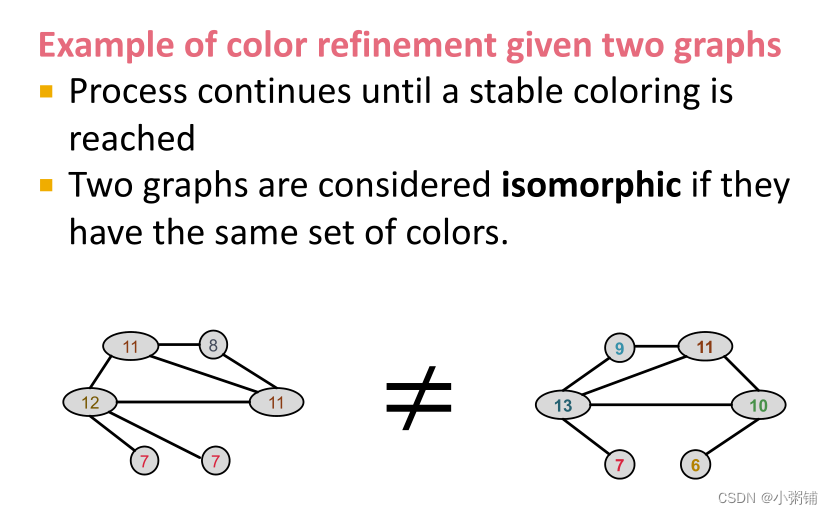
- 收集邻居信息
- GIN 使用神经网络对单射 HASH 函数进行建模,具体来说,我们将在元组上对单射函数进行建模
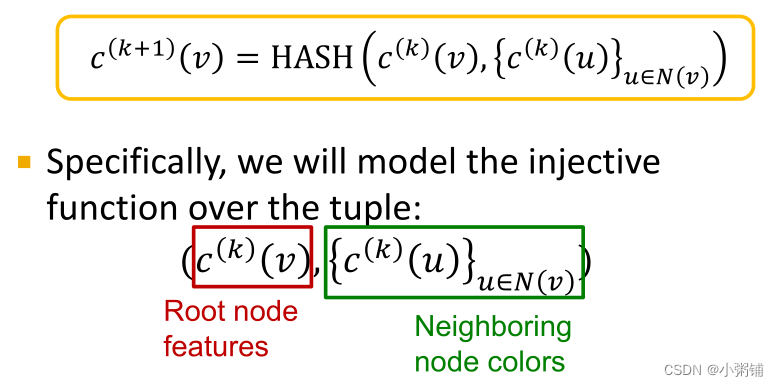
- 如果输入特征
c
(
0
)
(
v
)
c^{(0)}(v)
c(0)(v)表示为独热向量,那么直接求和的函数就是单射的,GIN卷积层可以表示如下:
- WL 图内核(也称为Color refinement algorithm 色彩优化算法):首先对节点颜色进行初始化,然后根据邻居信息迭代地更新节点颜色,并通过哈希函数进行映射,反复迭代,直到达到稳定的着色为止。
-
总结:GIN的完整模型如下

k次迭代之后, C ( K ) ( v ) C^{(K)}(v) C(K)(v)可以总结K跳邻域的结构。 -
GIN and WL Graph Kernel
- GIN 可以理解为 WL graph Kernel 的可微神经版本

- GIN 相对于 WL 图内核的优点是:
- 节点嵌入是低维的;因此,它们可以捕获不同节点的细粒度相似性
- 可以为下游任务学习更新函数的参数
- 由于 GIN 和 WL 图核之间的关系,它们的表达能力是完全一样的:如果两个图可以通过 GIN 来区分,那么它们也可以通过 WL 内核来区分,反之亦然。
- GIN 和WL图内核足以区分大多数真实图形
- GIN 可以理解为 WL graph Kernel 的可微神经版本
3. Summary
我们设计了一个可以模拟单射多集函数的神经网络。
- 我们将神经网络用于邻居聚合函数,并得出 GIN——最具表现力的 GNN 模型。
- 关键是使用 element-wise sum pooling,而不是 mean-/max-pooling
- GIN与WL图核密切相关
- GIN和WL图核都可以区分大部分真实图
各类池化层的辨别能力如下:

我们可以提高GNN 的表达能力吗?
- 存在现有 GNN 框架无法区分的基本图结构,例如循环差异
- 可以提高 GNN 的表达能力来解决上述问题,这样的话GNN不仅需要传递消息,还需要更多的信息和更高级的操作,在后续的课程将会涉及如何提高GNN的表达能力,使其比GIN和WL更具表现力。














 462
462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









