






Improving Taxonomy-based Categorization with Categorical Graph Neural Networks

摘要
在搜索和检索中,一个关键的子任务是将用户搜索查询分类到预定义的类别中。
传统的监督多类分类算法通常独立对待每个类别。然而,在实际应用中,类别具有隐式关系。类别被组织为基于树的分类法,可以将其视为图形。在这项工作中,我们探索了一种利用语义信息来改进基于分类法的分类的方法。我们提出了一类基于图的网络结构,我们称之为分类图神经网络 (CaGNN)。 CaGNNs 利用相邻类别之间的关系信息并叠加每个类别的语义信息,从而提高查询分类的性能。 CaGNN 框架可以将基线分类器与任何图神经网络集成,例如常用的图注意力网络和图卷积网络。在一个 2k 类别的查询分类数据集和另一个 5k 类别的广告标题分类数据集上,与没有 CaGNN 结构的基线深度神经网络模型相比,CaGNN 显着提高了分类器的性能。
通过检查学习到的类别嵌入和消息传递流,我们表明 CaGNN 有效地封装了有用的图结构信息。
我们的贡献如下:
- 我们将我们提出的 CaGNN 模型应用于产品广告查询分类。结果表明,CaGNN 显着提高了没有 GNN 结构的基线模型的性能。
- 我们在不同的生产制度中测试CaGNN 方法,结果表明我们的 CaGNN 模型在所有数据集上都有改进。
- 我们提供了一种在我们的 CaGNN 框架内使用图注意力网络的注意力机制来检查学习的嵌入和消息传递流的方法。
相关工作
使用类别结构信息:
在分类过程中,有多种方法可以利用类别之间的结构信息。一些通过显式的基于图形的正则化将图形信息编码为损失函数,例如通过使用图拉普拉斯正则化项。其他人通过将层次表示嵌入到双曲空间中来学习层次表示。然而,这些方法无法利用除图形信息之外的类别中的其他特征,如本文中的语义特征和手工特征。在 GNN 的背景下,Lanchantin 等人 [7] 提出了用于多标签分类的标签消息传递 (LaMP) 神经网络,它将类别视为类别交互图上的节点。
然后,他们使用基于注意力的神经消息传递计算以输入为条件的每个标签节点的隐藏表示。这种方法的一个限制是它不能生成类别嵌入,因为类别交互以输入为条件。 Wang 等人 [8] 使用语义嵌入和类别图在视觉分类问题中使用 GCN 实现零样本分类。
这种方法需要两个独立的学习步骤。首先,他们学习已见类别的分类器,然后他们使用 GCN 从已见类别中学习未见类别的分类器。相反,我们的方法在监督学习设置下一次性训练标签嵌入和查询分类器。
方法
在我们的设置中,我们得到了一个包含 n 个项目的数据集: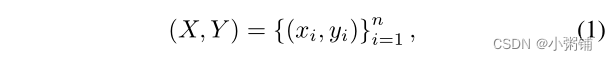
其中
x
i
x_i
xi 表示项目 i 的文本字符串,
y
i
∈
{
1
,
.
.
.
C
}
y_i ∈ \{1, . . . C\}
yi∈{1,...C}代表它的标签,C是类别总数。类别分类法可以看作是树结构(即森林)的集合,从根类别开始,内部类别然后是叶类别。请注意,标签
y
i
y_i
yi 可以是任何类别,包括根类别。给定一个输入 x,我们想要学习一个映射函数 f (x) 来预测它的目标 y。我们使用不同的神经网络模型来逼近这个映射函数并评估它们的性能。
我们的不同实验模型的架构在图 1 中进行了总结和说明。我们总共探索了五种不同模型的变体,由图 1 从左到右的各种路径表示。所有模型都使用相同的分类交叉熵损失函数进行训练。数据预处理因数据集而异。
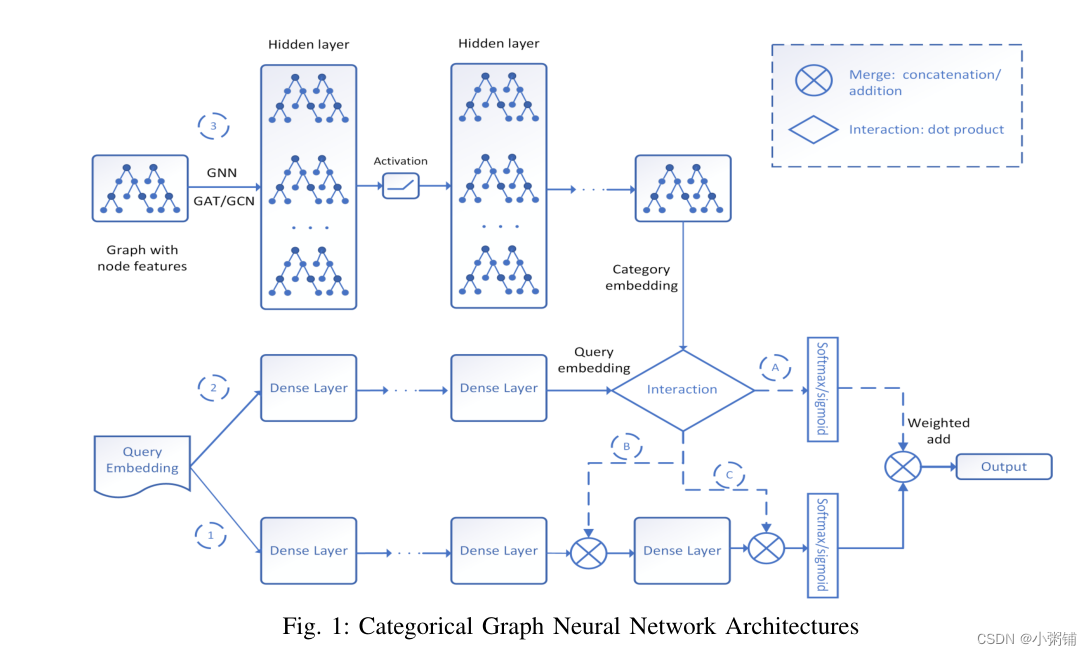
基线 DNN 模型:
我们的基线模型是一个完全连接的深度神经网络 (DNN),具有 3 个大小为 2048 的隐藏层加上一个具有输出维度大小(类别数C)和softmax 激活的输出层。基线网络的输入是 FastText 嵌入特征。这是图 1 的网络架构中的路径1。每个全连接层之后添加批量归一化和丢弃层,丢弃率为0.3。对于所有隐藏层激活函数,我们应用负斜率为 0.3 的 LeakyReLU 。我们首先使用内部卷积神经网络 (CNN) 模型生成查询嵌入,然后查询嵌入之后是一个完全连接的 DNN 来进行最终预测(参数针对生产进行了优化)。
具有图卷积网络的分类图神经网络:
CaGNN)的动机是通过与图神经网络集成来提高基线分类模型的性能,图神经网络利用相邻类别之间的关系信息并叠加每个类别的语义信息类别。因此,CaGNN 的模型架构建立在基线分类模型之上,通过添加额外的 GNN 路径来添加来自关系的额外信息和来自类别的语义信息,如图 1 所示。CaGCN)的分类图神经网络有两个图卷积层。 GCN 网络的输入是每个类别的特征。 CaGCN 模型如图 1 所示。路径 2是一个全连接的深度神经网络,具有 3 个隐藏层,大小相同为 2048,用于输出查询嵌入。设置与路径1相同。路径 1 和路径2中的网络不共享权重。直观上,查询转换需要一条单独的路径将查询转换到与路径3相同的空间。路径 3有两个大小为 2048 的图卷积层来生成类别嵌入。在类别嵌入之后,查询嵌入与路径 3 中的每个类别嵌入交互为每个类别生成分数(参见图 1)。在这里,我们使用的交互是点积,用于为每个类别生成标量分数。
交互可以是一个预定义的函数,也可以是一个网络来获取交互输出。
- 选项A是两条路径的softmax层的加权相加。
- 选项B与路径 2 的密集层输出串联
- 选项C是与密集层输出的加法。
具有图注意力网络的分类图神经网络
总结
我们引入了一类新的基于图的网络结构,我们称之为分类图神经网络 (CaGNN)。 CaGNN 旨在利用分类法中类别之间的语义信息和关系信息。类别的类别嵌入是在训练阶段生成的。可以集成这些嵌入以提高下游应用程序的性能。我们的结果表明,所提出的 CaGNN 可以显着提高分类模型的性能。此外,我们还表明注意力机制 (CaGAT) 可以提高模型的整体可解释性。
随着在线性能的提高,我们已将模型部署到生产环境中。
CaGNN 有几个潜在的改进和扩展可以作为未来的工作来解决,例如使用像 GNN 模型这样的 GraphSAGE 来处理更大的图 [31],利用注意力机制对模型的可解释性进行彻底的分析,并整合CaGNN 在最先进的基于 Transformer 的 NLP 模型之上,例如 BERT [27]。我们也应该在类似 BERT 的模型上看到类似的改进。我们还计划研究异构图,例如带有产品名称等辅助信息的类别。














 8137
8137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









