






TaxoExpan: Self-supervised Taxonomy Expansion with Position-Enhanced Graph Neural Network

摘要
分类法由机器可解释的语义组成,并为许多 Web 应用程序提供有价值的知识。例如,在线零售商使用分类法进行产品推荐,网络搜索引擎利用分类法来增强查询理解。在手动或半自动构建分类法方面已经付出了巨大的努力。然而,随着网络内容量的快速增长,现有的分类法将变得过时并且无法捕捉新兴知识。因此,在许多应用中,对现有分类法的动态扩展的需求很大。
在本文中,我们研究了如何通过添加一组新概念来扩展现有的分类法。我们提出了一个 名为 TaxoExpan 的新型自监督框架,它从现有分类法中自动生成一组⟨query concept,anchor concept⟩对作为训练数据。 使用此类自我监督数据,TaxoExpan 学习一个模型来预测查询概念是否是锚概念的直接下位词。我们在 TaxoExpan 中开发了两项创新技术:
- (1) 位置增强图神经网络,对现有分类法中锚点概念的局部结构进行编码
- (2) 噪声鲁棒训练目标,使学习模型不敏感自我监督数据中的标签噪声。
对来自不同领域的三个大型数据集进行的大量实验证明了 TaxoExpan 在分类扩展方面的有效性和效率。
介绍
几个世纪以来,分类法一直是组织知识的基础 [39]。在当今的网络中,分类法提供了宝贵的知识来支持许多应用程序,例如查询理解 [14]、内容浏览 [46]、个性化推荐 [15、55] 和网络搜索 [24、45]。例如,许多在线零售商(例如 eBay 和亚马逊)将产品组织成不同粒度的类别,以便客户可以轻松地搜索和导航此类别分类法以找到他们想要购买的商品。此外,网络搜索引擎(例如 Google 和 Bing)利用分类法更好地理解用户查询并提高搜索质量。
现有的分类法大多由人类专家或以众包方式构建。此类手动管理既费时又费力,而且很少能完成。为了减少人力,提出了许多自动分类法构建方法。他们首先使用文本模式或分布相似性识别“is-A”关系(例如,“iPad”是“电子产品”),然后将提取的概念对组织成有向无环图( DAG) 作为输出分类。随着网络内容和人类知识的不断增长,人们需要扩展现有的分类法以包括新出现的概念。然而,以前的大多数方法都是完全从头开始构建分类法,因此当我们添加新概念时,我们必须重新运行整个分类法构建过程。虽然很直观,但这种方法有几个局限性.
- 首先,许多分类法都有由领域专家提供的顶层设计,这种设计应该被保留。
- 其次,新构建的分类法可能与旧分类法不一致,这可能导致其依赖的下游应用程序不稳定。
- 最后,针对从头开始构建分类法的场景,之前的大多数方法都是无监督的,无法利用现有分类法的信号来构建新的分类法。
在本文中,我们研究了分类法扩展任务:给定现有分类法和一组新出现的概念,我们的目标是自动扩展分类法以合并这些新概念(不改变给定分类法中的现有关系)。图 1显示了一个示例,其中计算机科学领域的分类法扩展到包括新的子领域(例如,“量子计算”)和新技术(例如,“元学习”和“UDA”)。
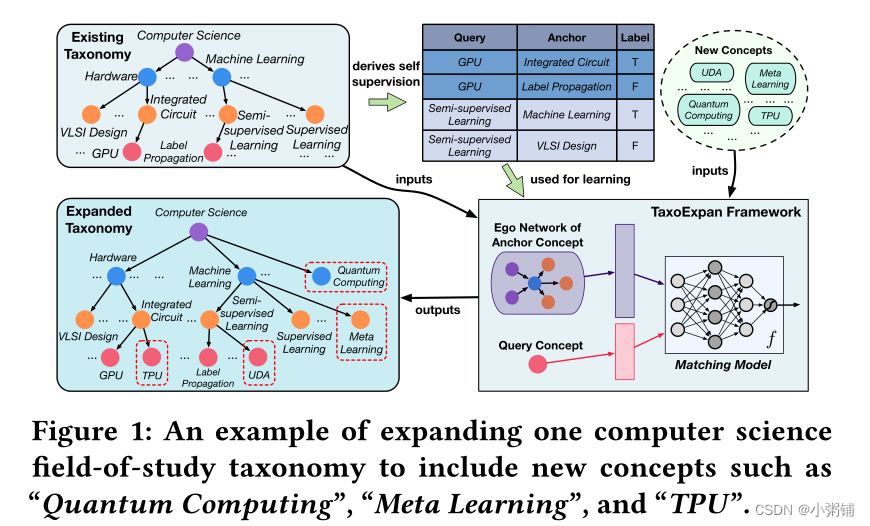
一些先前的研究通过使用一组额外的标记概念及其在现有分类法中的真实插入位置来尝试完成这项任务。然而,此类标记数据通常很小,因此禁止我们学习更强大的模型来捕获现有分类法中的包含语义。
为了充分利用上述自我监督数据,我们在 TaxoExpan 中开发了两种新技术。
- 第一个是位置增强图神经网络 (GNN),它使用现有分类法中的自我网络 (egonet) 对锚点概念的局部结构进行编码。如果我们将这个锚点概念视为查询概念的“父母”,那么这个自我网络包括查询概念的潜在“兄弟姐妹”和“祖父母”。我们应用图神经网络 (GNN) 来模拟这个自我网络。然而,常规 GNN 无法区分与查询具有不同相对位置的节点(即,一些节点是查询的祖父节点,而其他节点是查询的兄弟节点)。为了解决这个限制,我们提出了一种简单但有效的增强功能,可以使用位置嵌入将此类位置信息注入 GNN。我们表明,这种嵌入可以很容易地与现有的 GNN 架构集成,并显着提高预测性能。
- 第二种技术是一种基于 InfoNCE 损失的新型抗噪声训练方案。我们不是预测每个单独的⟨query concept,anchor concept⟩对是否是正的,而是首先将共享相同查询概念的所有对分组到一个训练实例中,并学习一个模型以从组中的其他负对中选择正对。我们表明,这种训练方案对标签噪声具有鲁棒性,并能提高性能。
我们测试了 TaxoExpan 框架在来自不同领域的三个真实世界分类法上的有效性。我们的结果表明,TaxoExpan 可以在科学领域生成高质量的概念分类法,并在 WordNet 分类法扩展挑战中取得最先进的性能。
总而言之,我们的主要贡献包括:
- (1)一个自我监督的框架,无需手动标记数据即可自动扩展现有分类法;
- (2) 一种通过合并层次位置信息来增强图神经网络的有效方法;
- (3) 一个新的训练目标,使学习的模型能够对自监督数据中的标签噪声具有鲁棒性;
- (4) 广泛的实验验证了 TaxoExpan 框架在来自不同领域的三个真实世界的大规模分类法上的有效性和效率。
相关工作
分类法构建与扩展:大多数现有的分类法构建方法都侧重于通过首先提取上位词-下位词对,然后将所有上位词关系组织成树或 DAG 结构来构建整个分类法。对于第一个上位词发现步骤,方法分为两类:(1) 基于模式的方法,利用预定义模式 从语料库中提取上位词关系,以及 (2) 计算成对的分布式方法基于术语嵌入 的术语相似性度量,并使用它们来预测两个术语是否具有上位关系。对于第二个上位词关系组织步骤,大多数方法将其表述为图优化问题。他们首先使用提取的上位词对构建一个嘈杂的上位词图,然后将输出分类推导为特定的树或 DAG 结构(例如,最大生成树和最小成本流)。最后,有一些方法利用实体集扩展技术从头开始或从微小的种子分类法逐步构建分类法。
在许多现实世界的应用程序中,一些现有的分类法可能已经由专家或通过众包精心策划,并部署在在线系统中。这些应用程序不需要从头开始构建整个分类法,而是需要动态扩展现有分类法的功能。存在一些关于使用来自维基百科的命名实体或来自不同语料库的特定领域概念扩展 WordNet 的研究。 SemEval 2016 挑战的任务专门设置为使用特定领域的概念丰富 WordNet。这些方法的一个限制是它们依赖于 WordNet 独有的同义词集结构,因此不能轻易推广到其他分类法。
为了解决上述限制,最近的工作尝试开发用于扩展通用分类法的方法。 Wang 等人 [44] 设计了一个分层 Dirichlet 模型,以使用查询日志扩展搜索引擎中的类别分类法。 Plachouras 等人 [30] 在外部释义数据集上学习释义模型,并应用学习的模型直接在现有分类法中找到概念的释义。 Vedula 等人 [42] 将多个特征(其中一些特征是从外部 Bing 搜索 API 检索到的)组合到一个排名模型中,根据候选位置与查询概念的匹配分数对候选位置进行评分。与这些方法相比,我们的 TaxoExpan 框架明确地模拟了每个候选位置周围的局部结构,从而提高了扩展分类法的质量。
图神经网络:
我们的工作还与图神经网络 (GNN) 有关,这是一种学习图结构数据的通用方法。已经提出了许多 GNN 架构来学习单个节点嵌入 [12、19、43] 用于节点 487 分类和链接预测任务,或者学习整个图表示 [48、53] 用于图分类任务。在这项工作中,我们使用与之前任务完全不同的公式来处理分类扩展任务。我们利用一些现有的 GNN 架构,并用额外的相对位置信息丰富它们。最近,You 等人 [50] 提出了一种将位置信息添加到 GNN 中的方法。我们的方法与 You 等人不同。他们在没有任何特定参考点的情况下对节点在完整图中的绝对位置进行建模;而我们的技术捕获节点相对于查询节点的相对位置。最后,一些关于图形生成的工作 [21, 49] 涉及一个模块,用于将新节点添加到部分生成的图形中,这与我们的模型具有相似的目标。然而,这种图形生成模型通常需要完全标记的训练数据来学习。据我们所知,这是第一项关于如何使用自我监督学习扩展现有有向无环图(因为我们将分类法建模为 DAG)的研究。
问题表述
分类法:分类法
T
=
(
N
,
E
)
\mathcal{T = (N, E)}
T=(N,E) 是一个有向无环图,其中每个节点
n
∈
N
n ∈ \mathcal{N}
n∈N 代表一个概念(即一个词或短语),每个有向边
⟨
n
p
,
n
c
⟩
∈
E
⟨n_p, n_c ⟩ ∈ \mathcal{E}
⟨np,nc⟩∈E 表示表达该概念
n
p
n_p
np 的关系是比概念
n
c
n_c
nc 更普遍的最具体的概念。换句话说,我们将
n
p
n_p
np 称为
n
c
n_c
nc 的“父级”,将
n
c
n_c
nc 称为
n
p
n_p
np 的“子级”。
问题定义:
分类法扩展任务的输入包括两部分:
- (1)一个已有的分类法 T 0 = ( N 0 , E 0 ) \mathcal{T^0 = (N^0, E^0)} T0=(N0,E0)
- (2)一组新概念C。这个新概念集既可以由用户手动指定,也可以从文本语料库中自动提取。我们的目标是将现有的分类法 T \mathcal{T} T扩展为更大的分类法 T 0 = ( N 0 ∪ C , E 0 ∪ R ) \mathcal{T^0 = (N^0 \cup C, E^0 \cup R)} T0=(N0∪C,E0∪R),其中 R \mathcal{R} R 是一组新发现的关系,每个关系都包含一个新概念 c ∈ C \mathcal{c ∈ C} c∈C。
简化的问题:上述问题的一个简化版本是我们假设新概念的输入集只包含一个元素(即|C| = 1),我们的目标是找到这个新概念的一个父节点(即|R| = 1).
讨论:在这项工作中,我们遵循之前的研究 并假设 N 0 ∪ C \mathcal{N^0 \cup C} N0∪C中的每个概念都有一个从该概念的名称或其定义句子 [32] 和相关网页中学习的初始嵌入向量[44]。我们的问题表述假设现有分类法中的那些关系没有被修改。
TAXOEXPAN框架
在本节中,我们首先介绍我们的分类模型和扩展目标。然后,我们详细说明了如何表示查询概念和插入位置(即锚点概念),在此基础上我们提出了查询概念匹配模型。最后,我们讨论了如何从现有分类法中生成自我监督数据并使用它们来训练 TaxoExpan 框架。
分类模型和扩展目标
分类法
T
\mathcal{T}
T 描述了概念的层次结构。这些概念构成
T
\mathcal{T}
T 中的节点集
N
\mathcal{N}
N 。在数学上,我们将每个节点
n
∈
N
\mathcal{n \in N}
n∈N 建模为分类随机变量,将整个分类
T
\mathcal{T}
T 建模为贝叶斯网络。我们将分类法
T
\mathcal{T}
T 的概率定义为节点集
N
\mathcal{N}
N 的联合概率,它可以进一步分解为一组条件概率,如下所示:

其中 Θ 是模型参数集,
p
a
r
e
n
t
T
(
n
i
)
\mathcal{parent_T(n_i)}
parentT(ni) 是分类法
T
\mathcal{T}
T 中
n
i
n_i
ni 的父节点集。
给定学习模型参数 Θ、现有分类法
T
0
=
(
N
0
,
E
0
)
\mathcal{T^0 = (N^0, E^0)}
T0=(N0,E0)和一组新概念
T
0
=
(
N
0
,
E
0
)
\mathcal{T^0 = (N^0, E^0)}
T0=(N0,E0),我们可以通过解决以下优化问题理想地找到最佳分类法
T
∗
\mathcal{T^*}
T∗:

这种天真的方法有两个局限性。首先,概念集上所有可能分类的搜索空间
∣
N
0
∪
C
∣
\mathcal{|N^0 \cup C|}
∣N0∪C∣大得令人望而却步。其次,我们不能保证现有分类法
∣
T
0
∣
\mathcal{|T^0|}
∣T0∣的结构保持不变,从应用的角度来看,这可能是不可取的。
我们通过将输出分类法的搜索空间限制为现有分类法
∣
T
0
∣
\mathcal{|T^0|}
∣T0∣的精确扩展来解决上述限制。具体来说,我们保持每个现有分类法节点
n
∈
N
0
\mathcal{n\in N^0}
n∈N0 的父节点不变,并且只尝试找到
C
\mathcal{C}
C中每个新概念的节点的单个父节点。因此,我们将上述计算上棘手的问题分为以下一组|C|易于处理的优化问题:
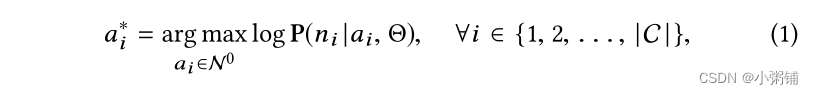
其中
a
i
a_i
ai 是新概念
n
i
∈
C
n_i \in C
ni∈C 的父节点,我们将其称为“锚点概念”。
上面的等式定义了|C|独立的优化问题,每个问题旨在找到一个新概念
n
i
n_i
ni 的单亲,实质上将更通用的分类法扩展问题简化为 |C|独立的简化问题,并通过将新概念一个一个地插入现有分类法来解决它。由于上述减少忽略了新概念之间可能的相互作用。接下来的章节将继续回答两个关键问题:
- (1) 如何对条件概率 P ( n i ∣ a i , Θ ) P(n_i |a_i, Θ) P(ni∣ai,Θ) 建模
- (2) 如何学习模型参数 Θ
建模Query-Anchor Matching
我们通过将查询概念
n
i
n_i
ni 和锚概念
a
i
a_i
ai 投影到向量空间来对它们之间的匹配分数进行建模,并且使用它们的矢量化表示计算匹配分数。
我们在图 3 中展示了 TaxoExpan 的整个模型架构。

g
e
m
b
g_{emb}
gemb是一个embedding模型,它提供查询概念的初始特征向量
h
q
h_q
hq和egonet中每个节点的初始特征向量。图传播模块将初始特征向量转换为更好的节点表示,图读出模块在此基础上输出 egonet 嵌入作为最终锚点表示。最后,匹配模块输入查询和锚点表示并输出它们的匹配分数。
查询概念表示:在这项研究中,我们假设每个查询概念都有一个初始特征向量,该向量是根据与该概念相关的一些文本学习的。这样的文本可以像概念名称一样简单,或者是在一些先前的研究中关于概念的定义句子和点击的网页。我们用初始特征向量 n i n_i ni 来表示每个查询概念 n i n_i ni 。我们将在实验部分讨论如何使用嵌入学习方法获得这样的初始特征向量。
锚概念表示:每个锚点概念对应于现有分类法
∣
T
0
∣
\mathcal{|T^0|}
∣T0∣中的一个节点,该节点可能是查询概念的“父节点”。表示锚点概念的一种朴素方法是直接使用其初始特征向量。这种方法的一个关键限制是它只捕获“父”节点信息并丢失其他周围节点的信号:假设给我们一个查询概念“高依赖病房”来预测它是否应该在现有分类法中的“病房”节点下。由于这两个概念基于它们的表面名称具有不同的嵌入,我们可能认为不应将此查询概念置于此锚点概念之下。但是,如果我们知道这个锚点概念有两个子节点,即“重症监护病房”和“低依赖病房”,它们与查询概念密切相关,我们更有可能将查询概念放在这个锚点概念下,正确。上面的例子演示了在锚点概念表示中捕获局部结构信息的重要性。因此我们使用其自我网络对锚点概念进行建模。具体来说,我们将锚概念视为查询概念的“父”节点。锚点概念的自我网络由查询概念的“兄弟”节点和“祖父”节点组成,如图 2 所示。我们使用图神经网络表示基于其自我网络的锚点概念。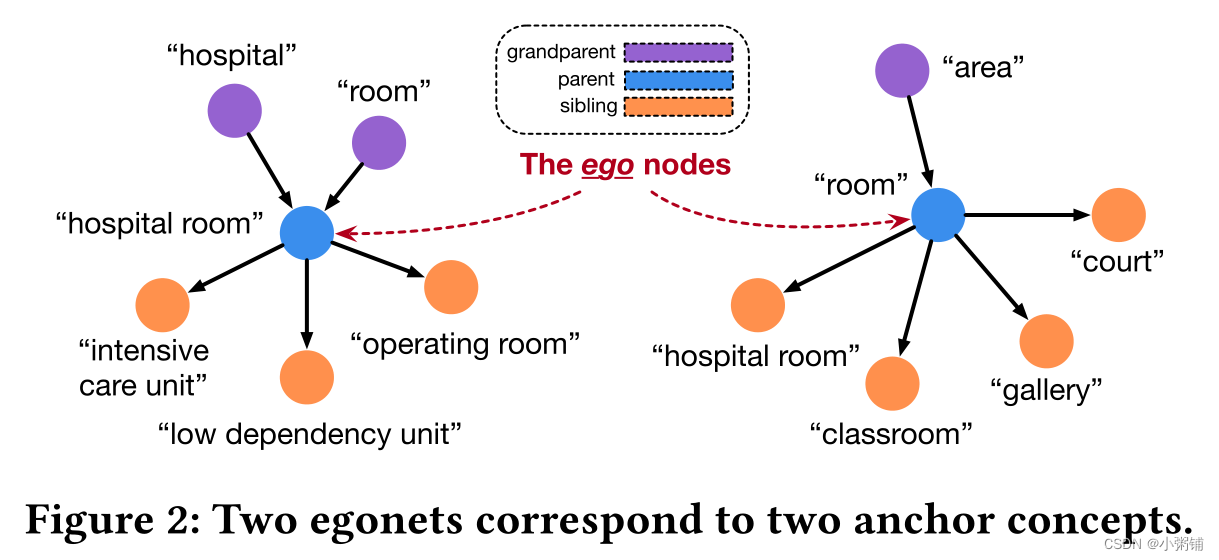
图神经网络架构:给定锚定概念
a
i
a_i
ai 及其对应的自我网络
G
a
i
G_{a_i}
Gai 及其初始表示
a
i
a_i
ai ,我们使用图神经网络 (GNN) 生成其最终表示
a
i
a_i
ai 。这个 GNN 包含两个组件:
- (1)一个图传播模块,它在图结构上转换和传播节点特征以计算 G a i G_{a_i} Gai 中的单个节点嵌入
- (2)一个图读出模块,它将节点嵌入组合到完整的自我网络嵌入中编码以锚点概念为中心的所有局部结构信息。
图传播模块使用邻域聚合策略通过聚合其邻居 N (u) 及其自身的表示来迭代更新节点 u 的表示。在 K 次迭代之后,节点的表示捕获其 K-hop 邻域内的结构信息。
形式上,我们定义具有 K 层的 GNN 如下:
我们可以使用两种流行的架构实例化 AGG(k):图卷积网络 (GCN) 和图注意力网络 (GAT) 。
GCN: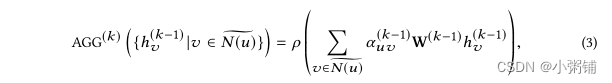
GAT:
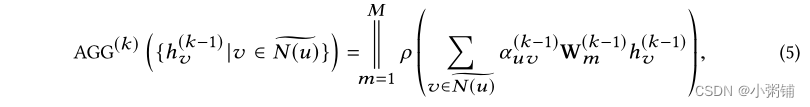 在获得每个节点的最终表示
h
u
(
K
)
h^{(K)}_u
hu(K) 后,我们使用图形读出模块生成自我网络的表示
h
G
h_G
hG,如下所示:
在获得每个节点的最终表示
h
u
(
K
)
h^{(K)}_u
hu(K) 后,我们使用图形读出模块生成自我网络的表示
h
G
h_G
hG,如下所示:

其中 READOUT 是置换不变函数 [51],例如逐元素均值或求和。
位置增强图神经网络:上述模型的限制是它们无法捕获每个节点相对于查询概念的位置信息(以图2为例,左侧自我网络中的“病房”节点是锚节点本身,而右侧自我网络中是锚节点的子节点)。此类位置信息将影响节点特征在自我网络中的传播方式以及最终图嵌入的聚合方式。TaxoExpan 的一项重要创新是位置增强图神经网络的设计。关键思想是学习一组“位置嵌入”并用其丰富每个节点特征。我们将节点 u 的位置表示为 p u p_u pu 并将其在第 k 层的位置嵌入表示为 p u ( k ) p^{(k)}_u pu(k) 。我们用位置增强版本 h u ( k − 1 ) ∣ ∣ p u ( k − 1 ) h^{(k−1)}_u||p^{(k-1)}_u hu(k−1)∣∣pu(k−1) 替换每个方程式中(3-5)的节点特征 h u ( k − 1 ) h^{(k−1)}_u hu(k−1)。 并相应地调整 W ( k − 1 ) W^{(k−1)} W(k−1) 的维数。这有助于我们从两个方面学习更好的节点表示。首先,我们可以捕获更多的邻里信息。取等式 (3)右边的 W ( k − 1 ) h v ( k − 1 ) W^{(k−1)}h^{(k−1)}_v W(k−1)hv(k−1)作为例子,我们将其增强为如下:
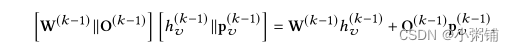
其中 O ( k − 1 ) O^{(k−1)} O(k−1) 是另一个用于转换位置嵌入的权重矩阵。上面的等式表明,节点的新表示由其邻域的内容(即 h v ( k − 1 ) h^{(k−1)}_v hv(k−1))和自我网络中的相对位置(即 p v ( k − 1 ) p^{(k−1)}_v pv(k−1))共同决定。其次,对于 GAT 架构,我们可以更好地将邻居重要性建模为等式(3) 中的项 α u v ( k − 1 ) α^{(k−1)}_{uv} αuv(k−1),取决于 p u ( k − 1 ) p^{(k−1)}_u pu(k−1)和 p v ( k − 1 ) p^{(k−1)}_v pv(k−1)。
此外,我们提出了两种在图形读出模块中注入位置信息的方案。第一个称为加权平均读数 (WMR),定义如下:
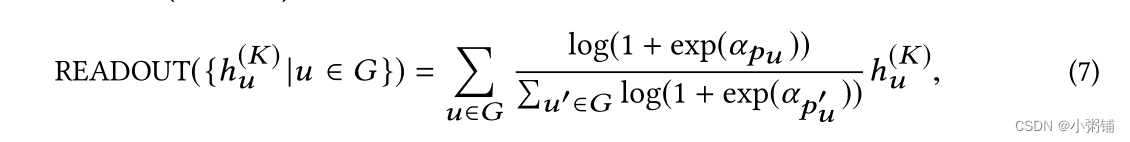
其中 α p u α_{p_u} αpu 是表示位置 p u p_u pu 重要性的参数。第二种方案称为串联读出(CR),它将具有相同位置的节点的平均嵌入组合在一起,如下所示:

其中 P 是我们正在建模的所有头寸的集合,I(·) 是一个指示函数,如果其内部语句为真则返回 1,否则返回 0。
匹配查询概念和锚点概念:基于学习到的查询概念表示
n
i
∈
R
D
1
n_i ∈ \mathbb{R}^{D_1}
ni∈RD1 和锚点概念表示
a
i
∈
R
D
2
a_i ∈ \mathbb{R}^{D_2}
ai∈RD2,我们使用匹配模块
f
(
⋅
)
:
R
D
2
×
R
D
1
→
R
f (·) :\mathbb{R}^{D_2} × \mathbb{R}^{D_1} → \mathbb{R}
f(⋅):RD2×RD1→R计算它们的匹配分数。我们研究了两种架构。第一个是具有一个隐藏层的多层感知器,定义如下:
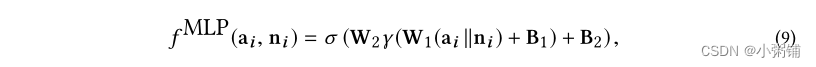
其中
W
1
,
B
1
,
W
2
,
B
2
{W_1, B_1, W_2, B_2}
W1,B1,W2,B2 是参数; σ(·)是sigmoid函数,γ(·)是LeakyReLU激活函数。第二种架构是对数双线性模型,定义如下: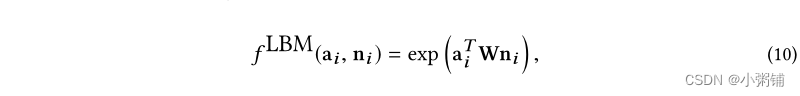 其中 W 是可学习的交互矩阵。我们选择 MLP 和 LBM,因为它们分别是线性和双线性交互模型中的代表性架构。
其中 W 是可学习的交互矩阵。我们选择 MLP 和 LBM,因为它们分别是线性和双线性交互模型中的代表性架构。
模型学习和推理
上一节讨论了如何使用参数化函数 f (·|Θ) 对查询锚点匹配进行建模。在本节中,我们首先介绍我们如何使用现有分类法中的自我监督来学习这些参数 Θ。然后,我们建立匹配分数与条件概率
P
(
n
i
∣
a
i
)
P(n_i |a_i )
P(ni∣ai)之间的联系,并讨论如何进行模型推理。
自我监督生成:图4展示了自我监督数据的生成过程。给定现有分类法
T
0
=
(
N
0
,
E
0
)
\mathcal{T^0 = (N^0, E^0)}
T0=(N0,E0)中的一条边
⟨
n
p
,
n
c
⟩
⟨n_p, n_c ⟩
⟨np,nc⟩,我们首先构造一个正 ⟨anchor, query⟩ 对,子节点
n
c
n_c
nc 作为“query”,父节点
n
p
n_p
np 作为“锚”。然后,我们通过固定查询节点
n
c
n_c
nc 并随机选择既不是
n
c
n_c
nc 的父母也不是后代的 N 个节点
{
n
r
l
∣
l
=
1
N
}
⊂
N
0
\{n^l_r |^N_{l=1}\} ⊂ \mathcal{N}^0
{nrl∣l=1N}⊂N0 来构造 N 个负对。
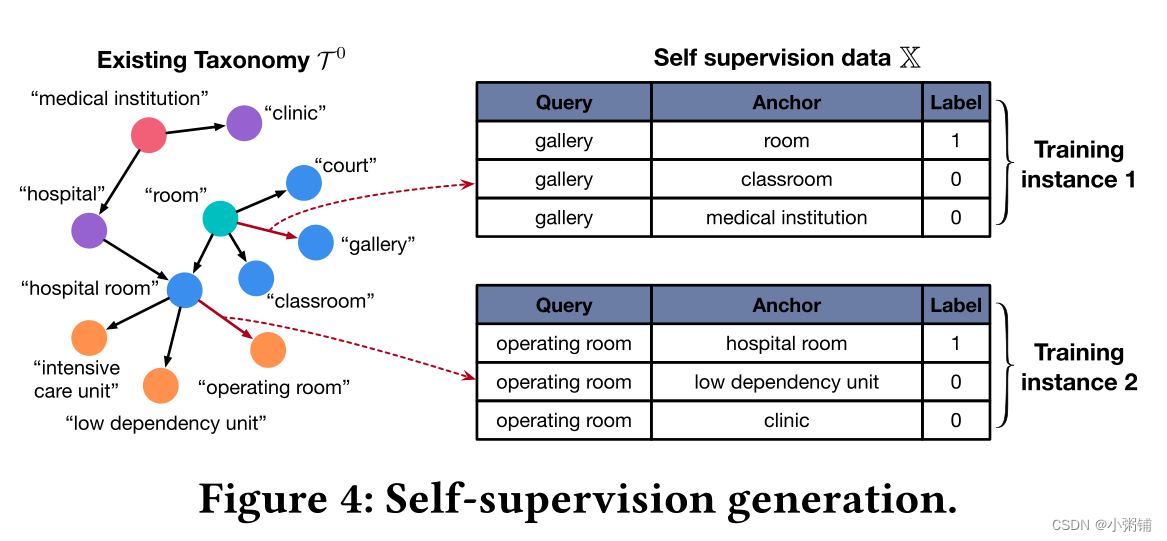
这 N + 1 对(一个正数和 N 个负数)共同组成一个训练实例
X
=
⟨
n
p
,
n
c
⟩
,
⟨
n
r
1
,
n
c
⟩
,
.
.
.
,
⟨
n
r
N
,
n
c
⟩
X = {⟨n_p, n_c ⟩, ⟨n^1_r , n_c ⟩, . . . , ⟨n^N_r , n_c ⟩}
X=⟨np,nc⟩,⟨nr1,nc⟩,...,⟨nrN,nc⟩.
通过对
T
0
\mathcal{T^0}
T0中的每条边重复上述过程,我们得到完整的自监督数据集
X
=
{
X
1
,
.
.
.
X
∣
E
0
∣
\mathbb{X} = \{X_1, . . . X_{|\mathcal{E^0}|}
X={X1,...X∣E0∣。请注意,在
T
0
\mathcal{T^0}
T0中具有 C 个父节点的节点将派生出
X
\mathbb{X}
X中的 C 个训练实例。
模型训练:我们使用 InfoNCE 损失在
X
\mathbb{X}
X上学习我们的模型,如下所示:
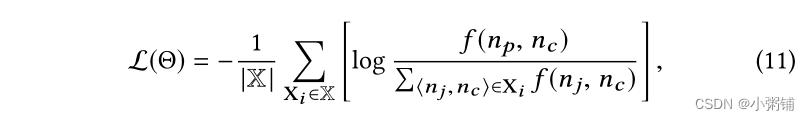
其中下标
j
∈
[
1
,
2
,
.
.
.
N
+
1
]
j ∈ [1, 2, . . . N + 1]
j∈[1,2,...N+1]。如果
j
=
1
,
⟨
n
j
,
n
c
⟩
j = 1,⟨n_j, n_c⟩
j=1,⟨nj,nc⟩ 是正对,否则,
⟨
n
j
,
n
c
⟩
⟨n_j, n_c⟩
⟨nj,nc⟩ 是负对。上述损失是正确分类正对
⟨
n
j
,
n
c
⟩
⟨n_j, n_c⟩
⟨nj,nc⟩的交叉熵,以
f
(
n
p
,
n
c
)
∑
⟨
n
j
,
n
c
⟩
∈
X
i
f
(
n
j
,
n
c
)
\frac{f(n_p,n_c)}{\sum_{⟨n_j, n_c⟩∈X_i} f(n_j,n_c)}
∑⟨nj,nc⟩∈Xif(nj,nc)f(np,nc)作为模型预测。优化此损失导致
f
(
a
i
,
n
i
)
f (a_i, n_i )
f(ai,ni) 估计以下概率密度(直到乘法常数):

我们在附录中证明了上述结果,并在算法 1 中总结了我们的自学习过程。我们在等式 1 中建立了匹配分数
f
(
a
i
,
n
i
)
f (a_i, n_i )
f(ai,ni)与概率
P
(
n
i
∣
a
i
)
P(n_i |a_i )
P(ni∣ai) 之间的联系,如下:

模型推理:在推理阶段,我们得到一个新的查询概念
n
i
n_i
ni 并应用学习模型 f (·|Θ) 来预测其在现有分类法
T
0
\mathcal{T^0}
T0中的父节点。从数学上讲,我们的目标是找到使
P
(
n
i
∣
a
i
)
P(n_i |a_i )
P(ni∣ai) , 等价于最大化
f
(
a
i
,
n
i
)
f (a_i, n_i )
f(ai,ni) 以及
P
(
n
i
)
P(n_i)
P(ni)在所有位置都相同的事实。因此,我们根据与
n
i
n_i
ni 的匹配分数对所有候选位置
a
i
a_i
ai 进行排序,并选择排名靠前的位置作为该查询概念的预测父节点。
虽然我们目前只选择顶部的一个作为查询的单亲,但如果需要,我们也可以选择前 k 个作为查询的父节点。
总结:给定现有分类法和一组新概念,我们的 TaxoExpan 首先生成一组自监督数据并使用算法 1 学习其内部模型参数。对于每个新概念,我们运行推理过程并在现有分类法中找到其最佳父节点。最后,我们将这些新概念一次一个地放在它们预测的父概念之下,并输出扩展的分类法。
















 630
630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









