






Scrapy框架学习
一、什么是scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量的代码,就能够快速的抓取
Scrapy使用了Twisted[‘twistid’]异步网络框架,可以加快我们的下载速度
补充:异步和非阻塞的区别

异步:调用在发出之后,这个调用就直接返回,不管有无结果
非阻塞:关注的是程序在等待调用结果(消息、返回值)时的状态,指在不能立刻得到结果之前,该调用不会阻塞当前的线程
二、scrapy的工作流程


使用框架:一、帮助提升速率,效率。二、减少代码量,简介方便
三、scrapy入门
1.创建一个scrapy
打开cmd界面中输入:scrapy startproject mySpider
mySpider是项目名
此时是在c盘中打开的项目
如果将文件夹移动到d盘,或者其他地方,在cmd中则需要进行一系列命令操作。
此时我们的文件夹时放在了D:\python练习中,因此:
补充:打开cmd是默认是在c盘内操作,而我们将此项目放在d盘中时,则要先c盘转化为d盘:

在cmd界面中输入 cd python练习 :
会进入到python练习文件夹中
在输入 cd mySpider :
便会进入到了mySpider文件中,

创建完成后,在pycharm编译器中会得到:
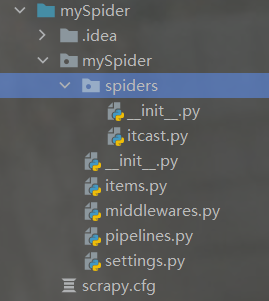
会得到两个内容:一个是mySpider文件夹,另一个是scrapy.cfg
scrapy.cfg :是项目的配置文件
items.py :可以预先在其中定义我们要爬取哪些东西 (爬虫)
pipelines.py :管道,进行数据的处理、储存
settings.py :整个项目的配置
2.生成一个爬虫
在cmd界面中,输入:scrapy genspider itcast itcast.cn
genspider 生成一个爬虫或者新建一个爬虫
itcast 为文件名字
itcast.cn 为允许爬虫的范围
项目建成后对应会在mySPider文件下的spiders文件中
新建立一个python项目:

在新建项目中,通过注释了解,可以进行项目书写
请求相应网站,通过xpath挖掘数据,并输出数据
在cmd界面中,输入:scrapy crawl itcast
便可以运行爬虫,爬取内容 如图:

通过编写代码后,得到数据,将数据传给管道,进行数据处理、储存
3.提取数据

extract() 返回一个包含有字符串数据的列表
extract_first() 返回列表中的第一个字符串
注意:spider中的parse方法名不能修改
4.保存数据、处理数据
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mcD4Mg4w-1636823120508)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20210710231246771.png)]](https://img-blog.csdnimg.cn/07b2ae9c6b864e81b47cc9375cb1b5c0.png)
yield item :将item 传给管道pipelines.py
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zmEwkhsZ-1636823120509)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20210710231402464.png)]](https://img-blog.csdnimg.cn/2cc84651bf61425e9147113e8e02151b.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA57uI6Lqr5a2m5LmgKg==,size_19,color_FFFFFF,t_70,g_se,x_16)
然后输出item,但是此时输出的会是空,我们在scrapy中不能这样直接输出,应该在setting中先开启后才能使用
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bmt6Or27-1636823120510)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20210710231614000.png)]](https://img-blog.csdnimg.cn/06d9b5f4eab94b68a416929501bc40e5.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA57uI6Lqr5a2m5LmgKg==,size_20,color_FFFFFF,t_70,g_se,x_16)
也可以将数据保存成各种形式
scrapy crawl fang -o fang.json 这样就是保存为json格式了
scrapy crawl fang -o fang.csv 保存为csv格式
四、使用pipline
pipline实际上是有多个的,在我们做爬虫项目时,往往不会只需要我们爬取一个网站的内容,所以一个爬虫是不够的,因此我们需要建立多个爬虫。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yLnjuUhz-1636823120511)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20210711082456717.png)]](https://img-blog.csdnimg.cn/af2c2ca1164942bc8886647e93cbfa85.png)
建立了多个爬虫
那pipline如何定义多个呢?
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XoddZX2v-1636823120512)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20210711082742657.png)]](https://img-blog.csdnimg.cn/da1bad9144ee431f8109a8bdd25d0e3a.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA57uI6Lqr5a2m5LmgKg==,size_20,color_FFFFFF,t_70,g_se,x_16)
可以直接在一个通道中进行识别,使用条件判断语句
另一种方式:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I2cBFEmp-1636823120513)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20210711083127148.png)]](https://img-blog.csdnimg.cn/2c3ee4bfb8ce458bbfc910891002d5c3.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA57uI6Lqr5a2m5LmgKg==,size_20,color_FFFFFF,t_70,g_se,x_16)
可以直接建立多个pipline管道使用。
为什么我们需要多个pipline:
1.可能会有多个spider,不同的pipline处理不同的item的内容
2.一个spider的内容可能要做不同的操作,比如存入不同的数据库中
注意:
1、pipline的权重越小优先级越高
2、pipline中process_item方法名不能修改其他的名称
五、实例演示
以汽车之家为目标,爬取宝马车系的车名和所对应价格
1.准备阶段
建立scrapy项目
打开cmd终端,将路径转移到相对应的路径下
输入:scrapy startproject scrapy_carhome
这样一个项目就建立起来了
然后转移到项目路径下,在新建一个爬虫程序
输入:scrapy genspider car “域名”
这样便成功完成了准备阶段
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pP3qWuie-1636823120514)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20211113173013260.png)]](https://img-blog.csdnimg.cn/d0cff02af7ff4c41aa4ba934b51b3529.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jeYwfrTP-1636823120516)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20211113173048195.png)]](https://img-blog.csdnimg.cn/a2f1e8c5b74a431bb217778135caf57d.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA57uI6Lqr5a2m5LmgKg==,size_20,color_FFFFFF,t_70,g_se,x_16)
2.提取数据
在新建的car.py程序中进行数据提取,通过xpath方法提取我们所需要的数据
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tAIAuqqt-1636823120517)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20211113173200195.png)]](https://img-blog.csdnimg.cn/6e90f914333848dc81cd3f92d0e3d222.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA57uI6Lqr5a2m5LmgKg==,size_20,color_FFFFFF,t_70,g_se,x_16)
其中需要注意的点在于,我们使用response爬取出来的数据类型是selector对象
所以我们需要用到extract方法,这个方法的作用是提取selector对象中的data属性值
六、scrapy shell
1.什么是scrapy shell?
Scrapy终端,是一个交互终端,供您在未启动spider的情况下尝试及调试您的爬取代码。其本意是 用来测试提取
数据的代码,不过您可以将其作为正常的Python终端,在上面测试任何的Python代码。
该终端是用来测试XPath或CSS表达式,查看他们的工作方式及从爬取的网页中提取的数据。在编写您的spider时, 该
终端提供了交互性测试您的表达式代码的功能,免去了每次修改后运行spider的麻烦。
一-旦熟悉了Scrapy终端后,您会发现其在开发和调试spider时发挥的巨大作用。
2.使用scrapy shell
我们直接在cmd终端就可以使用
直接输入:scrapy shell 域名
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SFeQ972b-1636823120518)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20211113192848182.png)]](https://img-blog.csdnimg.cn/0f1d60b7a1c8481b8b1b1af5d303bc61.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA57uI6Lqr5a2m5LmgKg==,size_20,color_FFFFFF,t_70,g_se,x_16)
我们输入的是百度的网址,然后能够得到以下内容
从图中我们就可以得到网站的response,如果需要网站中的一些东西,我们可以直接进行获取
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QCQuk1xS-1636823120518)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20211113192958305.png)]](https://img-blog.csdnimg.cn/3df6cdb06296465997636a20573b6a3d.png)
这里我输入了:response.url
获取了百度的网址
同时还可以有很多的功能
response.body 网页的主体
response.text 网页的文本内容
response.status 网页的状态
当然也可以提取我们所需要的数据
输入:response.xpath("//input[@id=“su”]/@value")

也能够得到我们需要的数据
使用scrapy shell 本身没什么用处,主要是用来进行调试,不用每次在测试时要去运行程序,对于老练的程序员来说没什么用处,不过可以用来给新手练手,因为它能够更简单,也更直接的调试scrapy程序
七、日志信息
大多数时候我们在执行scrapy程序中都会看到很多我们不想看到,并且也看不懂的东西,那些其实就是日志信息
当然我们也可以设置让它变得看不见
这里就讲到了日志信息和日志等级
日志等级分为:
CRITICAL :严重错误
ERROR :一般错误
WARNING :警告
INFO : 一般信息
DEBUG :调试信息
默认的日志等级是DEBUG,所以出现了DEBUG及以上等级的都会显示出来
所以我们可以再settings中修改等级,如果我们不想看到太多,可以改成一般错误,或者警告
输入:LOG_LEVEL = 'ERROR’
这样error等级以下的就不会显示出来了,但是我们这样会使得当发生错误时无法知道到底错在哪
所以我们使用更有效的一种方法
我们可以建立日志文件:
输入:LOG_FILE = 'log.log’
将程序中所有日志信息新建一个文件保存,程序中不在显示,注意的是文件的后缀一定是.log
八、scrapy的post请求

post请求是需要参数的,所有parse和start_urls是无效的
我们需要使用start_requests()方法
自行创建url,data
然后使用FormRuquest()方法

返回数据后,回调函数自行创建
在新的回调函数中,我们就可以进行网页操作,因为已经得到了post请求网站的信息了
















 1262
1262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











