







 本文详细介绍了如何配置环境,安装libbunwind和gperftool,以及如何在程序中使用这些工具进行性能测试、专注与忽视、生成报告和分析结果。重点展示了pprof的使用技巧和选项,适合性能优化开发者参考。
本文详细介绍了如何配置环境,安装libbunwind和gperftool,以及如何在程序中使用这些工具进行性能测试、专注与忽视、生成报告和分析结果。重点展示了pprof的使用技巧和选项,适合性能优化开发者参考。
一、配置环境
1、安装基本编译环境
sudo apt-get install autoconf automake libtool
2、安装libbunwind
下载安装包,我这里是下载libunwind-1.6.2.tar.gz
http://download.savannah.gnu.org/releases/libunwind/
(1)解压后进入文件夹执行
./configure
make
sudo make install
(2) 更新配置包
sudo echo ‘/usr/local/lib’> etcld.so.conf/local.conf
sudo ldconfig

3、安装图形可视化graphviz gv
(1) sudo apt-get install graphviz gv
4、安装gperftool工具
(1)Github下载源码
git clone http://github.com/gperftools/gperftools
(2)编译代码
./autogen.sh
./configure
make
sudo make install
(3)配置环境变量
gedit ~/.bashrc
把/usr/local/bin配到path里:export PATH=/usr/local/bin
把/usr/local/lib配到LD_LIBRARY_PATH里:export LD_LIBRAR_PATH=/uar/local/lib:$LD_LIBRAR_PATH

二、使用
1、在程序中测试指定位置的源码性能
(1)首先在头文件引入,默认路径为/usr/local/include
#include<gperftools/profiler.h>
(2)然后在想要测试性能的位置加入
ProfilerStart(“xxx.prof”);//输出profile的路径及文件名
ProfilerStop();
可以对多个代码段作profile,但输出文件名称要不同,不然最后一次的profile输出会完全覆盖前一次的输出。
例如如下testperf.cpp:
#include<stdio.h>
#include<stdlib.h>
#include<gperftools/profiler.h>
int b()
{
int count = 500000000;
int i = 0;
for(i = 0;i<count;++i)
{
}
return 0;
}
int a()
{
int count = 1000000000;
int i = 0;
for(i = 0;i<count;++i)
{
}
b();
return 0;
}
int main ()
{
ProfilerStart("test_capture.prof");
a();
ProfilerStop();
return 0;
}
(3)加入库-lprofiler和 -lunwind编译testperf.cpp,生成可执行文件test
-lprofiler 连接选项得到链接了cpu profiler代码的可执行程序,另外推荐使用-o作为编译选项,可以得到函数调用关系图。

(4)设置变量运行可执行文件test生成性能报告
HEAPCHECK=normal ./test
2、专注与忽视
如果程序函数较多,而只想关注某个函数的调用关系,可以加上- -focus ,例如只想关注与a相关的调用关系,
可以加上- -focis=a,如果不想关注某个函数,可以加上–ignore=a
pprof --gv --focus=a test test.prof
3、查看报告
(1)以web的方式查看报告
pprof ./test test_capture.prof –web
(2)以pdf的方式查看报告
pprof ./test test_capture.prof –pdf>prof.pdf
(3)使用性能分析工具Analyzing Callgrind查看报告
pprof --callgrind ./test test.prof >test.callgrind
kcachegrind test.callgrind
三、分析报告结果
1、text的结果分析
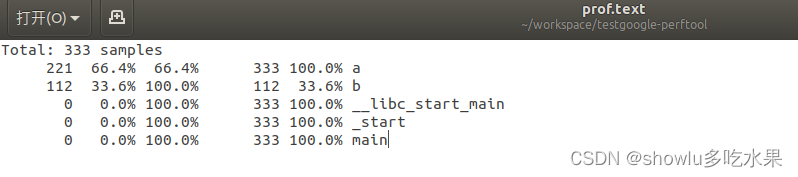
每行对应一个函数的统计,第一二列是该函数的本地采样(不包括该函数调用的函数中的采样次数)次数和比例,第三列是该函数本地采样次数占当前所有已统计函数的采样次数之和的比例。第四五列是该函数的累计采样次数(包括其调用的函数中的采样次数)和比例。
2、pdf或者web的可视化结果分析
在pprof的各种图形模式中,输出的是一个带有时间注释的调用图,如下所示:
整个图显示了函数间的调用关系,还显示了整个程序执行期间所消耗的cpu百分比。
图的左上角显示程序的名称,以及分析运行期间的采样次数;如果Focus选项处于打开状态,则图例还包含聚焦显示中显示的示例数量。
每个节点代表一个函数,节点的大小与本地计数成正比,有向边表示调用方到被调用方的关系,每个边标记的是调用花费的时间。每个结点的格式从上到下依次显示:函数所在的类名,函数名,函数消耗的cpu百分比(不包括调用的函数)、函数消耗的cpu百分比(包括其调用的函数)
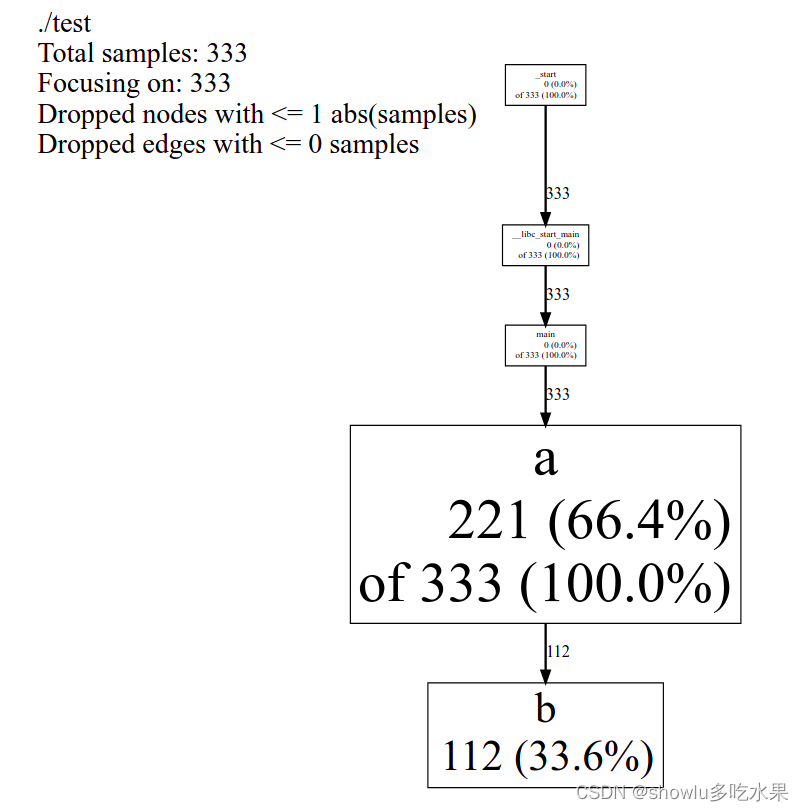
例如,这幅图的Total samples:333表明对程序进行了使用频率采样,一共进行333次,每秒采样100次(可以使用环境变量CPUPROFILE_FREQUENCY来控制,默认100),也就是说,每采样一次间隔10ms,程序采样了333次,说明程序执行3.33s
函数a自身消耗了66.4%的CPU,执行了2.21s,均不包括其调用的函数b,函数b自身消耗了33.6%的cpu,执行了1.12s,函数a自身加上调用的函数b一共消耗100%的cpu,执行类3.33s,结点a函数和结点b函数边上的数值112表示函数a调用函数b,函数b总共执行了1.48s
3、Analyzing Callgrind结果分析
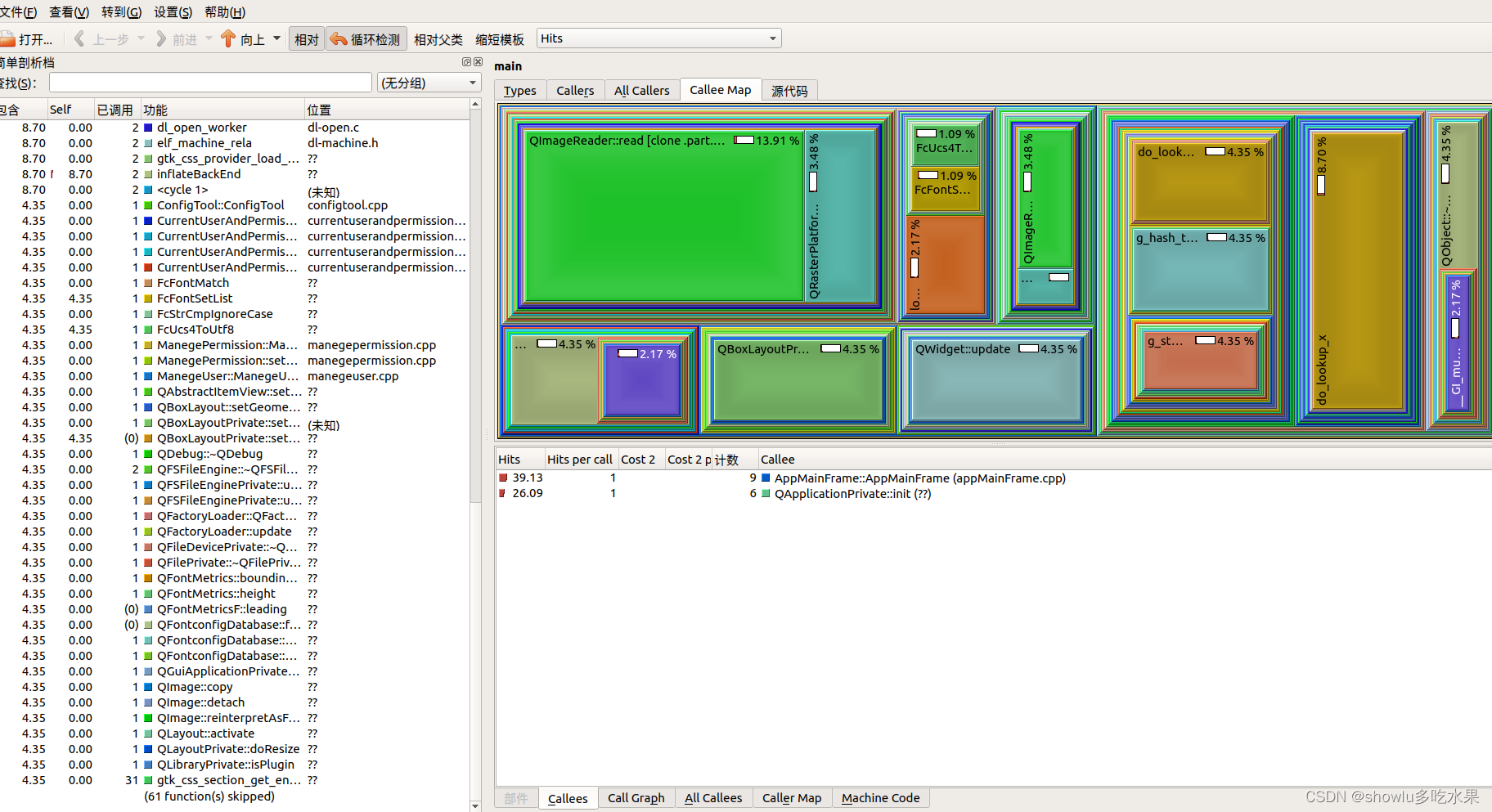
kcachegrind有几种模式查看,查看一个函数在记录的调用堆栈信息中出现的次数,从函数a到b的调用记录在堆栈中发现函数b的次数。
如果使用调试构建。则输出将包含文件和行号信息,并且它将显示带显示注释的源代码视图。
四、pprof选项
可以终端运行pprof --help查看详细信息
1、输出的部分类型
| 类型 | 解释 |
|---|---|
| - -gv | 生成带注释的调用图,转换为 postscript,并通过 gv 显示(要求安装 dot 和 gv) |
| - -dot | 以点格式生成带注释的调用图并发送到 stdout ,要求安装dot |
| - -ps | 以 Postscript 格式生成带注释的调用图并发送到 stdout (要求安装dot) |
| - -text | 产生文本列表(注意:如果你有x显示器,并且安装了dot和gv,那么使用- -gv输出会更有效 |
| - -list | 输出名称与 < regexp > 匹配的例程的源代码列表。清单中的每一行都注释了平面和累积的样本计数 |
2、报告粒度
默认情况下,pprof 为每个过程生成一个条目。但是,可以使用下列选项之一来更改输出的粒度
| 粒度 | 解释 |
|---|---|
| - -functions | 每个函数生成一个节点(这是默认值) |
| - -addresses | 每个程序地址生成一个节点 |
| - -lines | 每行生成一个节点 |
| - -files | 每个源文件生成一个结点 |
3、显示函数调用图
删除一些节点和边以减少输出显示中的杂乱,但删除的边和节点会导致显示中的一些计数不匹配。下面的选项控制这种效果:
| 选项 | 解释 |
|---|---|
| - -nodecount= | 此选项控制显示的节点数。首先通过减少累积计数对节点进行排序,然后只保留顶部的 N 个节点。默认值是80。 |
| - - nodefraction= | 此选项提供了从显示中丢弃节点的另一种机制。如果节点的累积计数小于此选项的值乘以配置文件的总计数,则删除该节点。默认值为0.005; 即删除占总时间不到0.5% 的节点。如果满足此条件或满足节点计数条件,则删除节点。 |
| - -edgefraction= | 此选项控制所显示边缘的数量。首先,如果删除源节点或目标节点,则删除边。否则,如果沿边缘的示例计数小于此选项的值乘以配置文件的总计数,则边缘将被删除。默认值为0.001; 即删除占总时间不到0.1% 的边。 |
| - -focus= | 根据该选项提供的正则表达式控制显示图形的哪个区域。对于调用图中的任何路径,我们根据提供的正则表达式检查路径中的所有节点。如果所有节点都不匹配,则从输出中删除路径 |
| –ignore= | 根据该选项提供的正则表达式控制显示图形的哪个区域。对于调用图中的任何路径,我们根据提供的正则表达式检查路径中的所有节点。如果任何节点匹配,则从输出中删除路径。 |
参考链接:
https://gperftools.github.io/gperftools/cpuprofile.html

















 226
226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









