






前言
DataLoader 是 PyTorch 中用于数据加载的工具类,它可以帮助我们有效地读取和处理数据集。
介绍与使用方式
简单来说,dataloader的作用就是将数据集变成可以进行遍历的对象,每次迭代可以从数据集中返回一组数据。在模型训练时,我们能可以用DataLoader批量读取数据。
结合代码来理解
首先我们先准备测试数据
测试数据是由pytorch官方提供的CIFAR10数据
import torchvision
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
这行代码运行之后会下载CFAR10数据集到项目文件夹中的dataset文件夹下。其中train = False表示只下载测试数据,不下载训练数据。transform=torchvision.transforms.ToTensor()表述数据集转换成tensor数据类型。download=True会检测你的dataset文件夹中是否有该数据集,如果已经下载了,就不会继续下载了,如果是false就是不下载数据,所以这个代码运行之后并不需要删掉,不会重复下载数据的。
运行之后就会发现项目文件夹中多了一个文件夹dataset,里面就是存放的我们下载的CFAR10测试数据集
之后我们实例化一个dataload
from torch.utils.data import DataLoader
'''
batch_size=4表示每次取四个数据
shuffle= True表示开启数据集随机重排,即每次取完数据之后,打乱剩余数据的顺序,然后再进行下一次取
num_workers=0表示在主进程中加载数据而不使用任何额外的子进程,如果大于0,表示开启多个进程,进程越多,处理数据的速度越快,但是会使电脑性能下降,占用更多的内存
drop_last=False表示不丢弃最后一个批次,假设我数据集有10个数据,我的batch_size=3,即每次取三个数据,那么我最后一次只有一个数据能取,如果设置为true,则不丢弃这个包含1个数据的子集数据,反之则丢弃
'''
test_load = DataLoader(dataset=test_data, batch_size=4 , shuffle= True, num_workers=0,drop_last=False)
参数的意思已经标注
我们通过可视化的方式理解一下这个数据
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('logs')
step = 0
for data in test_load:
imgs,targets = data
print(imgs.shape)
print(targets)
writer.add_images('test_data', imgs, step)
step += 1
writer.close()通过tensorboard工具可视化这个dataload对象,前文说了dataload就是将数据集转换成一个可以迭代的方式,所以我们通过佛如循环来看一下每次迭代的都是啥玩意儿
每次迭代会返回两个东西,一个是imgs,表示图片集,前文实例化dataload的时候传入参数batch_size=4表示每次取四个数据,那么这里的imgs就是有四张图片(即每次迭代返回四张图片),而target返回的就是这四张图片对应的标签。
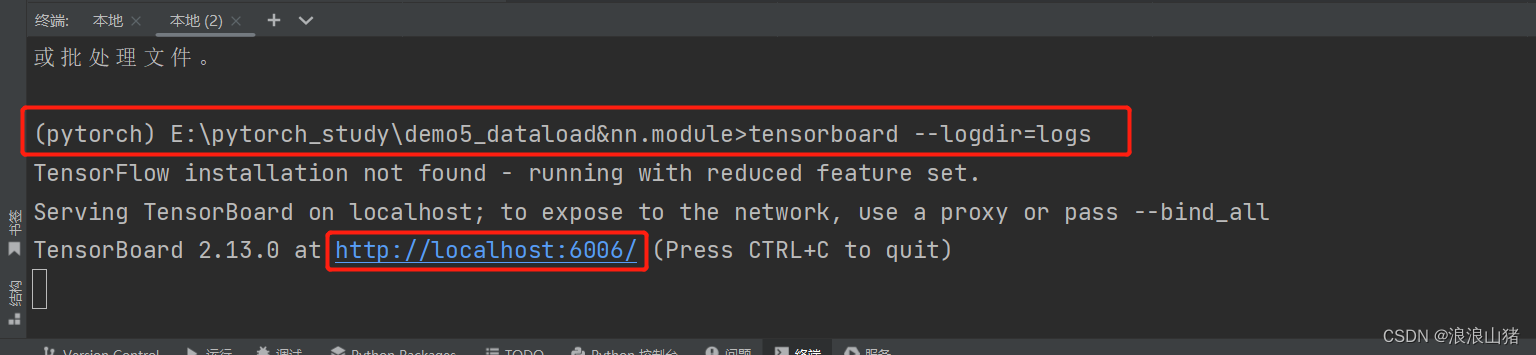
运行代码后会在项目文件夹下多一个logs文件夹(这个跟你实例化SummaryWriter传入的参数一致)里面存的就是运行日志,我们通过在终端中输入
tensorboard --logdir=logs
就可以得到一个链接,点击链接可查看图片
#logs指的是你日志文件夹的路径,路径是实例化summarywriter时设置的
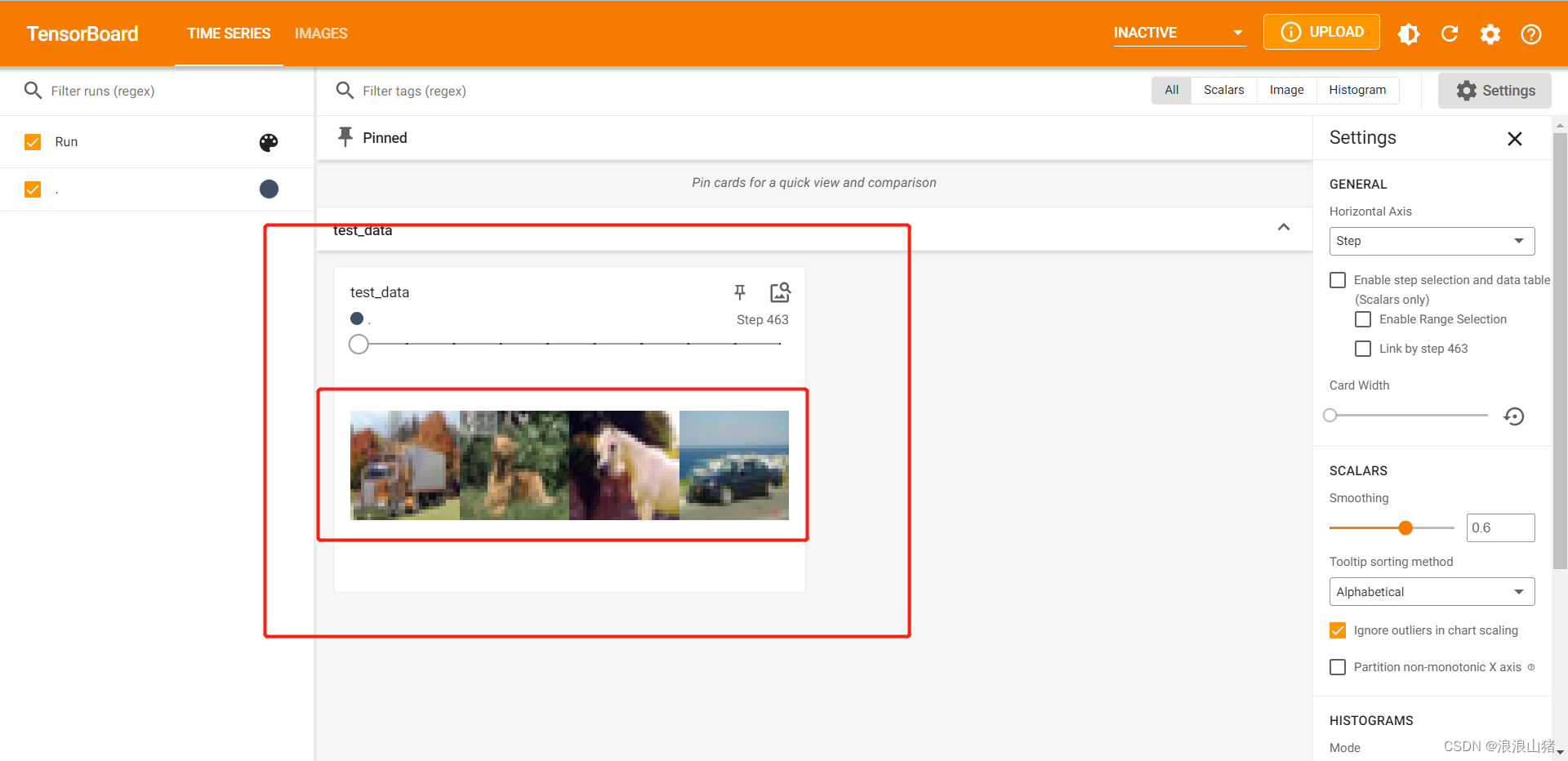 可以看到每个step都是四张图片,我们可以拖动上方的条查看每个step的图片。
可以看到每个step都是四张图片,我们可以拖动上方的条查看每个step的图片。















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









