






文章目录
前言
本文简要记录了作者在实现BP神经网络过程,学到的各种知识。注意只是简单记录一下用到的知识点,内容以公式和结论为主。 神经网络相关知识较为复杂,作者能力有限,文章难免有不足和勘误。请读者多多包涵。
一.BP神经网络简介
BP神经网络简介是一种按照误差,逆向传播算法训练的多层前馈神经网络。其核心是用梯度下降法,通过反向传播来不断调整网络的权值和偏置值,使网络的误差和最小。
二.损失函数
损失函数是用来度量模型的预测值与真实值之间差异程度的可导函数,函数值必须是一个非负数,该值越小模型的鲁棒性就越好。
2.1 均方差损失函数
L = 1 2 ∑ i = 1 n ( Y i − O i ) 2 L=\frac{1}{2}\sum_{i=1}^{n}{(Y_{i}-O_{i})^{2}} L=21∑i=1n(Yi−Oi)2
L ′ = ( 1 2 ( Y i − O i ) 2 ) ′ = Y i − O i L'=(\frac{1}{2}{(Y_{i}-O_{i})^{2}})'=Y_{i}-O_{i} L′=(21(Yi−Oi)2)′=Yi−Oi
i i i:指的是的几个节点, n n n:指的是该层总的节点个数
Y i Y_{i} Yi:指的是第 i i i节点的输出值, O i O_{i} Oi:指的是第 i i i节点的真实值
2.2 交叉熵损失函数
交叉熵损失函数,主要用于分类问题。其大多数时候都和softmax激活函数一起使用。softmax激活函数先将输出层的各个输出值,转换为0~1的概率分布,再由交叉熵损失函数求出loss值
L = ∑ i = 1 n − Y i l n ( P i ) = ∑ i = 1 n − l n ( P i ) L=\sum_{i=1}^{n}{-Y_iln(P_i)}=\sum_{i=1}^{n}{-ln(P_i)} L=∑i=1n−Yiln(Pi)=∑i=1n−ln(Pi)
L ′ = ( − Y i l n ( p i ) ) ′ = − Y i P i L'=(-Y_iln(p_i))'=-\frac{Y_i}{P_i} L′=(−Yiln(pi))′=−PiYi
i i i:指的是的几个节点, n n n:指的是该层总的节点个数
Y i Y_{i} Yi:指的是第 i i i节点的真实值,注意这里的真实值是1或0的概率,0的情况不用计算
P i P_i Pi:指的是第 i i i节点的概率,一般为softmax的输出值
三.激活函数
帮助网络学习数据中的复杂模式,使网络可以处理更复杂的事物
3.1 Sigmoid激活函数
Sigmoid容易导致梯度消失问题,且计算量大,一般不建议使用。
f ( x ) = 1 1 + e − x f(x)=\frac{1}{1+e^-x} f(x)=1+e−x1
f ( x ) ′ = e − x ( 1 + e − x ) 2 = 1 1 + e − x − ( 1 1 + e − x ) 2 = f ( x ) ( 1 − f ( x ) ) f(x)'=\frac{e^-x}{(1+e^-x)^2}=\frac{1}{1+e^-x}-(\frac{1}{1+e^-x})^2=f(x)(1-f(x)) f(x)′=(1+e−x)2e−x=1+e−x1−(1+e−x1)2=f(x)(1−f(x))
3.2 Relu激活函数
ReLU激活函数,主要用于中间层,其很好的解决了梯度消失的问题,但学习率建议不要太大,不然很容易使神经元死亡。
f ( x ) = m a x ( 0 , x ) f(x)=max(0,x) f(x)=max(0,x)
f ( x ) ′ = { 1 , x > 0 0 , x ≤ 0 f(x)'=\left\{ \begin{array}{lr}1,&x>0 \\0,&x\le0\end{array}\right. f(x)′={1,0,x>0x≤0
3.3 LeakyReLU激活函数
LeakyReLU是ReLU的变体,为了解决神经元死亡问题。注意 a a a的值很小,一般取0.01~0.05。
f ( x ) = m a x ( a x , x ) f(x)=max(ax,x) f(x)=max(ax,x)
f ( x ) ′ = { 1 , x > 0 a , x ≤ 0 f(x)'=\left\{\begin{array}{lr} 1,&x>0 \\a,&x\le0\end{array}\right. f(x)′={1,a,x>0x≤0
3.4 softmax激活函数
主要用于输出层,处理分类问题,一般和交叉熵损失函数配合使用。注意softmax为指数运算,输出值可能超出范围,可以通过 y i = y i − m a x ( y i ) y_i=y_i-max(y_i) yi=yi−max(yi) 解决。以下为softmax激活函数导数与交叉熵损失函数导数之积的推导过程。
f ( x ) = e y i ∑ i = 1 n e y i f(x)=\frac{e^{y_i}}{\sum_{i=1} ^ {n}{e^{y_i}}} f(x)=∑i=1neyieyi
令神经网络的输出值为 o 1 o_1 o1和 o 2 o_2 o2
P 1 = e o 1 e o 1 + e o 2 P_1=\frac{e^{o_1}}{e^{o_1}+e^{o_2}} P1=eo1+eo2eo1
f l o s s ( P 1 ) ′ = ( e o 1 e o 1 + e o 2 ) ′ = e o 1 ( e o 1 + e o 2 ) − e o 1 e o 2 ( e o 1 + e o 2 ) 2 = e o 1 e o 1 + e o 2 − ( e o 1 e o 1 + e o 2 ) 2 = P 1 − P 1 2 = P 1 ( 1 − P 1 ) f_{loss}(P_1)'=(\frac{e^{o_1}}{e^{o_1}+e^{o_2}})'=\frac{e^{o_1}(e^{o_1}+e^{o_2})-e^{o_1}e^{o_2}}{(e^{o_1}+e^{o_2})^2}=\frac{e^{o_1}}{e^{o_1}+e^{o_2}}-(\frac{e^{o_1}}{e^{o_1}+e^{o_2}})^2=P_1-P_{1}^2=P_1(1-P_1) floss(P1)′=(eo1+eo2eo1)′=(eo1+eo2)2eo1(eo1+eo2)−eo1eo2=eo1+eo2eo1−(eo1+eo2eo1)2=P1−P12=P1(1−P1)
f a c t ( P 1 ) ′ = ( − l n ( P 1 ) ) ′ = − 1 P 1 f_{act}(P_1)'=(-ln(P_1))'=-\frac{1}{P_1} fact(P1)′=(−ln(P1))′=−P11
f l o s s ( P 1 ) ′ ⋅ f a c t ( P 1 ) ′ = P 1 ( 1 − P 1 ) ⋅ ( − 1 P 1 ) = P 1 − 1 = P 1 − Y 1 = > P i − Y i f_{loss}(P_1)'\cdot f_{act}(P_1)'=P_1(1-P_1)\cdot (-\frac{1}{P_1})=P_1-1=P_1-Y_1=>P_i-Y_i floss(P1)′⋅fact(P1)′=P1(1−P1)⋅(−P11)=P1−1=P1−Y1=>Pi−Yi
P 2 = e o 2 e o 1 + e o 2 P_2=\frac{e^{o_2}}{e^{o_1}+e^{o_2}} P2=eo1+eo2eo2
f l o s s ( P 2 ) ′ = ( e o 2 e o 1 + e o 2 ) ′ = 0 − e o 1 e o 2 ( e o 1 + e o 2 ) 2 = − e o 2 e o 1 + e o 2 ⋅ e o 1 e o 1 + e o 2 = − P 2 P 1 f_{loss}(P_2)'=(\frac{e^{o_2}}{e^{o_1}+e^{o_2}})'=\frac{0-e^{o_1}e^{o_2}}{(e^{o_1}+e^{o_2})^2}=\frac{-e^{o_2}}{e^{o_1}+e^{o_2}}\cdot\frac{e^{o_1}}{e^{o_1}+e^{o_2}}=-P_2P_1 floss(P2)′=(eo1+eo2eo2)′=(eo1+eo2)20−eo1eo2=eo1+eo2−eo2⋅eo1+eo2eo1=−P2P1
f a c t ( P 1 ) ′ = ( − l n ( P 1 ) ) ′ = − 1 P 1 f_{act}(P_1)'=(-ln(P_1))'=-\frac{1}{P_1} fact(P1)′=(−ln(P1))′=−P11
f l o s s ( P 2 ) ′ ⋅ f a c t ( P 1 ) ′ = − P 2 P 1 ⋅ ( − 1 P 1 ) = P 2 − 0 = P 2 − Y 2 = > P i − Y i f_{loss}(P_2)'\cdot f_{act}(P_1)'=-P_2P_1\cdot (-\frac{1}{P_1})=P_2-0=P_2-Y_2=>P_i-Y_i floss(P2)′⋅fact(P1)′=−P2P1⋅(−P11)=P2−0=P2−Y2=>Pi−Yi
综上可得: f l o s s ( P i ) ′ ⋅ f a c t ( P i ) ′ = P i − Y i f_{loss}(P_i)'\cdot f_{act}(P_i)'=P_i-Y_i floss(Pi)′⋅fact(Pi)′=Pi−Yi
四.初始化问题
1.权重weight,随机初始化的范围为
−
1.0
∼
1.0
-1.0\sim 1.0
−1.0∼1.0。
2.偏置值bias,一般初始化为0。
3.学习率learning,通常先设置为0.01,再逐步减小到0.001。但具体情况要具体分析。
专业的初始化方法可参考:He,Xavier初始化的方法
五.BP神经网络数学推导
建议看B站视频BV1Y64y1z7jM,视频作者手动推导很详细,作者的推导过程也借鉴于此。
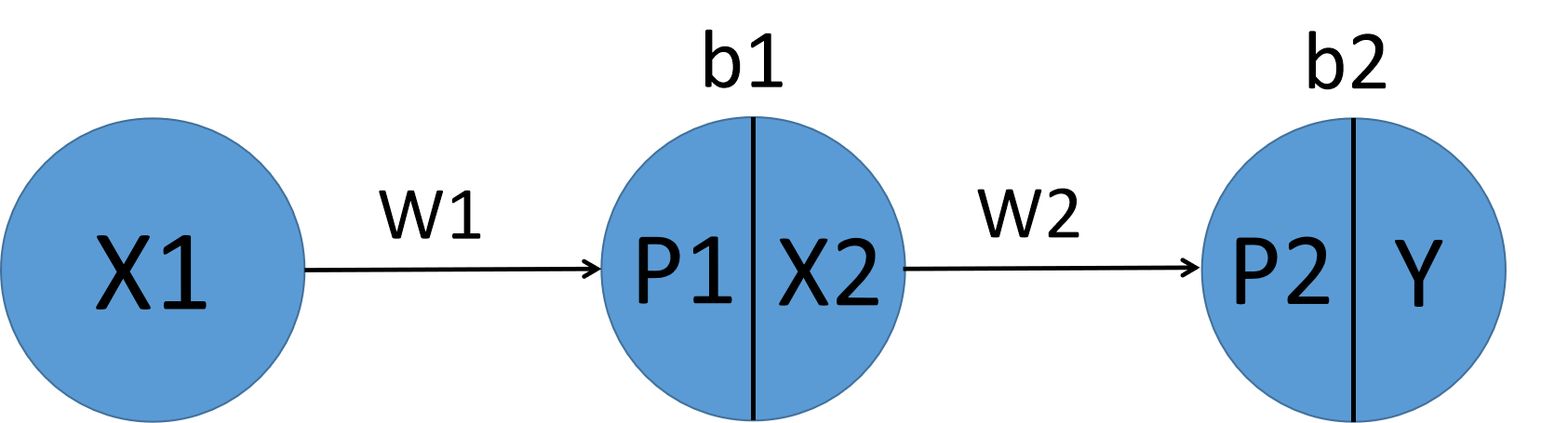
使用Sigmoid激活函数 f a c t f_{act} fact和均方差损失函数 f l o s s f_{loss} floss,令学习率为 η η η
f l o s s ( x ) ′ = ∑ i = 1 n ( O i − Y i ) f_{loss}(x)'=\sum_{i=1}^{n}{(O_{i}-Y_{i})} floss(x)′=∑i=1n(Oi−Yi) 带入 Y Y Y可得 f l o s s ( Y ) ′ = ( Y − O ) f_{loss}(Y)'=(Y-O) floss(Y)′=(Y−O)
Y = f a c t ( P 2 ) = f a c t ( X 2 ∗ W 2 + b 2 ) Y=f_{act}(P_{2})=f_{act}(X_{2}*W_{2}+b_{2}) Y=fact(P2)=fact(X2∗W2+b2)
X 2 = f a c t ( P 1 ) = f a c t ( X 1 ∗ W 1 + b 1 ) X_{2}=f_{act}(P_{1})=f_{act}(X_{1}*W_{1}+b_{1}) X2=fact(P1)=fact(X1∗W1+b1)
f a c t ( x ) ′ = f ( x ) ( 1 − f ( x ) ) f_{act}(x)'=f(x)(1-f(x)) fact(x)′=f(x)(1−f(x))
求 Δ b 2 Δb_{2} Δb2
Δ b 2 = η ⋅ ∂ f l o s s ( Y ) ∂ b 2 Δb_{2}=η\cdot\frac{∂f_{loss}(Y)}{∂b_{2}} Δb2=η⋅∂b2∂floss(Y)
= η ⋅ ∂ f l o s s ( Y ) ∂ Y ⋅ ∂ Y ∂ P 2 ⋅ ∂ P 2 ∂ b 2 =η\cdot\frac{∂f_{loss}(Y)}{∂Y}\cdot\frac{∂Y}{∂P_{2}}\cdot\frac{∂P_{2}}{∂b_{2}} =η⋅∂Y∂floss(Y)⋅∂P2∂Y⋅∂b2∂P2
= η ⋅ ( Y − O ) ⋅ f a c t ( P 2 ) ( 1 − f a c t ( P 2 ) ) ⋅ 1 =η\cdot(Y-O)\cdot f_{act}(P_{2})(1-f_{act}(P_{2}))\cdot1 =η⋅(Y−O)⋅fact(P2)(1−fact(P2))⋅1
= η ⋅ ( Y − O ) ⋅ Y ( 1 − Y ) =η\cdot(Y-O)\cdot Y(1-Y) =η⋅(Y−O)⋅Y(1−Y)
即 Δ b 2 = η ⋅ f l o s s ( Y ) ′ ⋅ f a c t ( P 2 ) ′ Δb_{2}=η\cdot f_{loss}(Y)'\cdot f_{act}(P_{2})' Δb2=η⋅floss(Y)′⋅fact(P2)′
求 Δ W 2 ΔW_{2} ΔW2
Δ W 2 = η ⋅ ∂ f l o s s ( Y ) ∂ W 2 ΔW_{2}=η\cdot\frac{∂f_{loss}(Y)}{∂W_{2}} ΔW2=η⋅∂W2∂floss(Y)
= η ⋅ ∂ f l o s s ( Y ) ∂ Y ⋅ ∂ Y ∂ P 2 ⋅ ∂ P 2 ∂ W 2 =η\cdot\frac{∂f_{loss}(Y)}{∂Y}\cdot\frac{∂Y}{∂P_{2}}\cdot\frac{∂P_{2}}{∂W_{2}} =η⋅∂Y∂floss(Y)⋅∂P2∂Y⋅∂W2∂P2
= η ⋅ ( Y − O ) ⋅ f a c t ( P 2 ) ( 1 − f a c t ( P 2 ) ) ⋅ X 2 =η\cdot(Y-O)\cdot f_{act}(P_{2})(1-f_{act}(P_{2}))\cdot X_{2} =η⋅(Y−O)⋅fact(P2)(1−fact(P2))⋅X2
= η ⋅ ( Y − O ) ⋅ Y ( 1 − Y ) ⋅ X 2 =η\cdot(Y-O)\cdot Y(1-Y) \cdot X_{2} =η⋅(Y−O)⋅Y(1−Y)⋅X2
即 Δ W 2 = η ⋅ f l o s s ( Y ) ′ ⋅ f a c t ( P 2 ) ′ ⋅ X 2 = Δ b 2 ⋅ X 2 ΔW_{2}=η\cdot f_{loss}(Y)'\cdot f_{act}(P_{2})' \cdot X_{2}= Δb_{2} \cdot X_{2} ΔW2=η⋅floss(Y)′⋅fact(P2)′⋅X2=Δb2⋅X2
求 Δ b 1 Δb_{1} Δb1
Δ b 1 = η ⋅ ∂ f l o s s ( Y ) ∂ b 1 Δb_{1}=η\cdot\frac{∂f_{loss}(Y)}{∂b_{1}} Δb1=η⋅∂b1∂floss(Y)
= η ⋅ ∂ f l o s s ( Y ) ∂ Y ⋅ ∂ Y ∂ P 2 ⋅ ∂ P 2 ∂ X 2 ⋅ ∂ X 2 ∂ P 1 ⋅ ∂ P 1 ∂ b 1 =η\cdot\frac{∂f_{loss}(Y)}{∂Y}\cdot\frac{∂Y}{∂P_{2}}\cdot\frac{∂P_{2}}{∂X_{2}}\cdot\frac{∂X_{2}}{∂P_{1}}\cdot\frac{∂P_{1}}{∂b_{1}} =η⋅∂Y∂floss(Y)⋅∂P2∂Y⋅∂X2∂P2⋅∂P1∂X2⋅∂b1∂P1
= η ⋅ ( Y − O ) ⋅ f a c t ( P 2 ) ( 1 − f a c t ( P 2 ) ) ⋅ W 2 ⋅ f a c t ( P 1 ) ( 1 − f p ( P 1 ) ) ⋅ 1 =η\cdot(Y-O)\cdot f_{act}(P_{2})(1-f_{act}(P_{2}))\cdot W_{2}\cdot f_{act}(P_{1})(1-f_{p}(P_{1}))\cdot1 =η⋅(Y−O)⋅fact(P2)(1−fact(P2))⋅W2⋅fact(P1)(1−fp(P1))⋅1
= η ⋅ ( Y − O ) ⋅ Y ( 1 − Y ) ⋅ W 2 ⋅ X 2 ( 1 − X 2 ) =η\cdot(Y-O)\cdot Y(1-Y)\cdot W_{2}\cdot X_{2}(1-X_{2}) =η⋅(Y−O)⋅Y(1−Y)⋅W2⋅X2(1−X2)
即 Δ b 1 = η ⋅ f l o s s ( Y ) ′ ⋅ f a c t ( P 2 ) ′ ⋅ W 2 ⋅ f a c t ( P 1 ) ′ = Δ b 2 ⋅ W 2 ⋅ f a c t ( P 2 ) ′ Δb_{1}=η\cdot f_{loss}(Y)'\cdot f_{act}(P_{2})'\cdot W_{2}\cdot f_{act}(P_{1})'=Δb_{2}\cdot W_{2}\cdot f_{act}(P_{2})' Δb1=η⋅floss(Y)′⋅fact(P2)′⋅W2⋅fact(P1)′=Δb2⋅W2⋅fact(P2)′
求 Δ W 1 ΔW_{1} ΔW1
Δ b 1 = η ⋅ ∂ f l o s s ( Y ) ∂ W 1 Δb_{1}=η\cdot\frac{∂f_{loss}(Y)}{∂W_{1}} Δb1=η⋅∂W1∂floss(Y)
= η ⋅ ∂ f l o s s ( Y ) ∂ Y ⋅ ∂ Y ∂ P 2 ⋅ ∂ P 2 ∂ X 2 ⋅ ∂ X 2 ∂ P 1 ⋅ ∂ P 1 ∂ W 1 =η\cdot\frac{∂f_{loss}(Y)}{∂Y}\cdot\frac{∂Y}{∂P_{2}}\cdot\frac{∂P_{2}}{∂X_{2}}\cdot\frac{∂X_{2}}{∂P_{1}}\cdot\frac{∂P_{1}}{∂W_{1}} =η⋅∂Y∂floss(Y)⋅∂P2∂Y⋅∂X2∂P2⋅∂P1∂X2⋅∂W1∂P1
= η ⋅ ( Y − O ) ⋅ f a c t ( P 2 ) ( 1 − f a c t ( P 2 ) ) ⋅ W 2 ⋅ f a c t ( P 1 ) ( 1 − f p ( P 1 ) ) ⋅ X 1 =η\cdot(Y-O)\cdot f_{act}(P_{2})(1-f_{act}(P_{2}))\cdot W_{2}\cdot f_{act}(P_{1})(1-f_{p}(P_{1}))\cdot X_{1} =η⋅(Y−O)⋅fact(P2)(1−fact(P2))⋅W2⋅fact(P1)(1−fp(P1))⋅X1
= η ⋅ ( Y − O ) ⋅ Y ( 1 − Y ) ⋅ W 2 ⋅ X 2 ( 1 − X 2 ) ⋅ X 1 =η\cdot(Y-O)\cdot Y(1-Y)\cdot W_{2}\cdot X_{2}(1-X_{2})\cdot X_{1} =η⋅(Y−O)⋅Y(1−Y)⋅W2⋅X2(1−X2)⋅X1
即 Δ W 1 = η ⋅ f l o s s ( Y ) ′ ⋅ f a c t ( P 2 ) ′ ⋅ W 2 ⋅ f a c t ( P 1 ) ′ ⋅ X 1 = Δ b 2 ⋅ W 2 ⋅ f a c t ( P 2 ) ′ ⋅ X 1 = Δ b 1 ⋅ X 1 ΔW_{1}=η\cdot f_{loss}(Y)'\cdot f_{act}(P_{2})'\cdot W_{2}\cdot f_{act}(P_{1})'\cdot X_{1}=Δb_{2}\cdot W_{2}\cdot f_{act}(P_{2})'\cdot X_{1}=Δb_{1} \cdot X_{1} ΔW1=η⋅floss(Y)′⋅fact(P2)′⋅W2⋅fact(P1)′⋅X1=Δb2⋅W2⋅fact(P2)′⋅X1=Δb1⋅X1
整理出以下公式
Δ b 2 = η ⋅ f l o s s ( Y ) ′ ⋅ f a c t ( P 2 ) ′ Δb_{2}=η\cdot f_{loss}(Y)'\cdot f_{act}(P_{2})' Δb2=η⋅floss(Y)′⋅fact(P2)′
Δ b 1 = Δ b 2 ⋅ W 2 ⋅ f a c t ( P 2 ) ′ Δb_{1}=Δb_{2}\cdot W_{2}\cdot f_{act}(P_{2})' Δb1=Δb2⋅W2⋅fact(P2)′
Δ W 2 = Δ b 2 ⋅ X 2 ΔW_{2}= Δb_{2} \cdot X_{2} ΔW2=Δb2⋅X2
Δ W 1 = Δ b 1 ⋅ X 1 ΔW_{1}=Δb_{1} \cdot X_{1} ΔW1=Δb1⋅X1
综上,令最后一个节点的编号为0,并使编号倒序排列,即 Δ b 0 Δb_{0} Δb0为最后一个点可得
Δ b 0 = η ⋅ f l o s s ( Y ) ′ ⋅ f a c t ( P 0 ) ′ Δb_{0}=η\cdot f_{loss}(Y)'\cdot f_{act}(P_{0})' Δb0=η⋅floss(Y)′⋅fact(P0)′
Δ b k = Δ b 0 ⋅ ( ∏ i = 0 k ⋅ W i ⋅ f a c t ( P i ) ′ ) = Δ b k − 1 ⋅ W k − 1 ⋅ f a c t ( P k − 1 ) ′ Δb_{k}=Δb_{0}\cdot(\prod_{i=0}^{k}\cdot W_{i}\cdot f_{act}(P_{i})')=Δb_{k-1}\cdot W_{k-1}\cdot f_{act}(P_{k-1})' Δbk=Δb0⋅(∏i=0k⋅Wi⋅fact(Pi)′)=Δbk−1⋅Wk−1⋅fact(Pk−1)′
Δ W k = Δ b k ⋅ X k ΔW_{k}=Δb_{k} \cdot X_{k} ΔWk=Δbk⋅Xk
注意:1.计算时一般不会计算出 P k P_k Pk的值,而是努力寻求 f a c t ( P k − 1 ) ′ f_{act}(P_{k-1})' fact(Pk−1)′或 f a c t ( P k − 1 ) f_{act}(P_{k-1}) fact(Pk−1)即与 Y k Y_k Yk或 X k X_{k} Xk的关系。
2.根据神经网络的实现不同,以上公式中的下标会有所变化(向后偏移1),但公式的形式是正确的。
3.计算过程的核心特点是,在求 Δ b 0 Δb_{0} Δb0或 Δ W k ΔW_{k} ΔWk时,其所在公式中的参数,一定来自于后面的节点,或自身节点,注意此为反向传播时的后面的节点,即先计算完成的节点。
六.项目代码
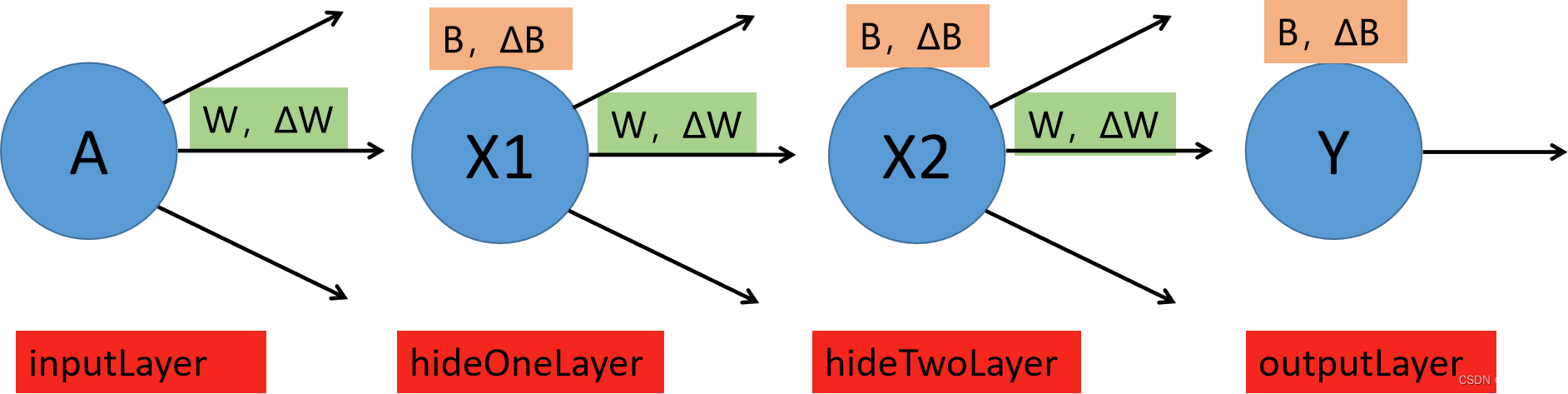
1.在该项目中损失函数用交叉熵损失函数,激活函数用LeakyReLU和softmax激活函数。
2.weight随机初始化的范围为
−
0.1
∼
0.1
-0.1\sim 0.1
−0.1∼0.1
4.学习率learning为0.04
5.建议在Release模式下运行,速度快很多。
6.GitHub仓库(内有项目用到的数据集)
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<math.h>
#include<time.h>
#define INNODE 20*20
#define HIDENODE_1 12
#define HIDENODE_2 12
#define OUTNODE 4
typedef struct {
double value;
double bias;
double bias_delta;
double* weight;
double* weight_delta;
}Node;
typedef struct {
Node* nodeArr;
size_t nodeNum;
}Layer;
typedef struct {
Layer* inputLayer;
Layer* hideLayerOne;
Layer* hideLayerTwo;
Layer* outputLayer;
}Networks;
typedef struct {
double* inputData;
double* outputData;
}Data;
typedef struct {
unsigned char blue;
unsigned char green;
unsigned char red;
unsigned char transparency;
}BGRA;
void GetfileData(Data* data, const char* filename, size_t outputDataID)
{
// 读取24位bmp位图数据
FILE* fp = NULL;
if ((fp = fopen(filename, "rb")) == NULL)
printf("打开%s文件失败!\n", filename);
BGRA* bgra = (BGRA*)malloc(sizeof(BGRA) * INNODE);
fseek(fp, 54, SEEK_SET);
// 计算每行补几个字节零
int k = 4 * (3 * 20 / 4 + 1) - 3 * 20;
for (size_t i = 0; i < INNODE; i++)
{
if (k != 4 && (ftell(fp) - 54 + k) % (3 * 20 + k) == 0)
fseek(fp, ftell(fp) + k, SEEK_SET);
fread(&bgra[i].blue, sizeof(unsigned char), 1, fp);
fread(&bgra[i].green, sizeof(unsigned char), 1, fp);
fread(&bgra[i].red, sizeof(unsigned char),1 , fp);
bgra[i].transparency = (unsigned char)0xFF;
}
fclose(fp);
for (size_t i = 0; i < INNODE; i++) // 已是灰度图,可直接赋值
data->inputData[i] = bgra[i].blue / 255.0;
for (size_t i = 0; i < OUTNODE; i++) // 已是灰度图,可直接赋值
data->outputData[i] = 0;
data->outputData[outputDataID] = 1;
free(bgra);
}
void InitInputLayer(Layer* inputLayer, size_t nextLayerNodeNum)
{
for (size_t i = 0; i < inputLayer->nodeNum; i++) {
inputLayer->nodeArr[i].weight = (double*)malloc(sizeof(double) * nextLayerNodeNum);
inputLayer->nodeArr[i].weight_delta = (double*)malloc(sizeof(double) * nextLayerNodeNum);
inputLayer->nodeArr[i].value = 0.f;
for (size_t j = 0; j < nextLayerNodeNum; j++)
inputLayer->nodeArr[i].weight[j] = (double)(rand() % 201 - 100) / 1000.0;
for (size_t j = 0; j < nextLayerNodeNum; j++)
inputLayer->nodeArr[i].weight_delta[j] = 0.f;
}
}
void InitHideLayer(Layer* hideLayer, size_t nextLayerNodeNum)
{
for (size_t i = 0; i < hideLayer->nodeNum; i++) {
hideLayer->nodeArr[i].weight = (double*)malloc(sizeof(double) * nextLayerNodeNum);
hideLayer->nodeArr[i].weight_delta = (double*)malloc(sizeof(double) * nextLayerNodeNum);
hideLayer->nodeArr[i].bias = 0;
hideLayer->nodeArr[i].bias_delta = 0;
hideLayer->nodeArr[i].value = 0;
for (size_t j = 0; j < nextLayerNodeNum; j++)
hideLayer->nodeArr[i].weight[j] = (double)(rand() % 201 - 100) / 1000.0;
for (size_t j = 0; j < nextLayerNodeNum; j++)
hideLayer->nodeArr[i].weight_delta[j] = 0.f;
}
}
void InitOutputLayer(Layer* outLayer)
{
for (size_t i = 0; i < outLayer->nodeNum; i++) {
outLayer->nodeArr[i].bias = 0;
outLayer->nodeArr[i].bias_delta = 0;
outLayer->nodeArr[i].value = 0;
outLayer->nodeArr->weight = NULL; // 不会用到,就赋值为NULL,便于最后释放资源
outLayer->nodeArr->weight_delta = NULL;
}
}
Networks* InitNetworks()
{
Networks* networks = (Networks*)malloc(sizeof(Networks));
// 初始化 inputLayer
networks->inputLayer = (Layer*)malloc(sizeof(Layer));
networks->inputLayer->nodeNum = INNODE;
networks->inputLayer->nodeArr = (Node*)malloc(sizeof(Node) * networks->inputLayer->nodeNum);
InitInputLayer(networks->inputLayer, HIDENODE_1);
// 初始化 hideLayerOne
networks->hideLayerOne = (Layer*)malloc(sizeof(Layer));
networks->hideLayerOne->nodeNum = HIDENODE_1;
networks->hideLayerOne->nodeArr = (Node*)malloc(sizeof(Node) * networks->hideLayerOne->nodeNum);
InitHideLayer(networks->hideLayerOne, HIDENODE_2);
// 初始化 hideLayerTwo
networks->hideLayerTwo = (Layer*)malloc(sizeof(Layer));
networks->hideLayerTwo->nodeNum = HIDENODE_2;
networks->hideLayerTwo->nodeArr = (Node*)malloc(sizeof(Node) * networks->hideLayerTwo->nodeNum);
InitHideLayer(networks->hideLayerTwo, OUTNODE);
// 初始化 outputLayer
networks->outputLayer = (Layer*)malloc(sizeof(Layer));
networks->outputLayer->nodeNum = OUTNODE;
networks->outputLayer->nodeArr = (Node*)malloc(sizeof(Node) * networks->outputLayer->nodeNum);
InitOutputLayer(networks->outputLayer);
return networks;
}
double ActivationFunction(const double num)
{
// return max(0, num); // ReLU激活函数
return num > 0 ? num : num * 0.05; // LeakyReLU激活函数
}
double BP_ActivationFunction(const double num)
{
// return (num > 0); // ReLU激活函数
return num > 0 ? 1 : 0.05; // LeakyReLU激活函数
}
void Forward_Propagation_Layer(Layer* nowLayer, Layer* nextLayer)
{
for (size_t i = 0; i < nextLayer->nodeNum; i++) {
double temp = 0.f;
for (size_t j = 0; j < nowLayer->nodeNum; j++) {
temp += nowLayer->nodeArr[j].value * nowLayer->nodeArr[j].weight[i];
}
temp += nextLayer->nodeArr[i].bias;
nextLayer->nodeArr[i].value = ActivationFunction(temp);
}
}
void Forward_Propagation(Networks* networks, Data* data)
{
// 给 inputLayer 赋值
for (size_t i = 0; i < networks->inputLayer->nodeNum; i++) {
networks->inputLayer->nodeArr[i].value = data->inputData[i];
}
// 核心 nextLayer 先不变,遍历nowLayer
/*看不懂 Forward_Propagation_Layer 函数就看这个*/
//for (size_t i = 0; networks->hideLayerOne->nodeNum; i++) {
// double temp = 0.f;
// for (size_t j = 0; networks->inputLayer->nodeNum; j++) {
// temp += networks->inputLayer->nodeArr[j].value * networks->inputLayer->nodeArr[j].weight[i];
// }
// temp += networks->hideLayerOne->nodeArr[i].bias;
// networks->hideLayerOne->nodeArr[i].value=ActivationFunction(temp);
//}
Forward_Propagation_Layer(networks->inputLayer, networks->hideLayerOne);
Forward_Propagation_Layer(networks->hideLayerOne, networks->hideLayerTwo);
// Forward_Propagation_Layer(networks->hideLayerTwo, networks->outputLayer);
// softmax 激活函数
double sum = 0.f;
for (size_t i = 0; i < networks->outputLayer->nodeNum; i++) {
double temp = 0.f;
for (size_t j = 0; j < networks->hideLayerTwo->nodeNum; j++) {
temp += networks->hideLayerTwo->nodeArr[j].value * networks->hideLayerTwo->nodeArr[j].weight[i];
}
temp += networks->outputLayer->nodeArr[i].bias;
networks->outputLayer->nodeArr[i].value = exp(temp);
sum += networks->outputLayer->nodeArr[i].value;
}
for (size_t i = 0; i < networks->outputLayer->nodeNum; i++) {
networks->outputLayer->nodeArr[i].value /= sum;
}
}
double* Back_Propagation_Layer(Layer* nowLayer, double* biasDeltaArr, size_t biasDeltaArrSize)
{
for (size_t i = 0; i < nowLayer->nodeNum; i++) {
for (size_t j = 0; j < biasDeltaArrSize; j++) {
double weight_delta = biasDeltaArr[j] * nowLayer->nodeArr[i].value;
nowLayer->nodeArr[i].weight_delta[j] += weight_delta;
}
}
double* bias_delta_arr = (double*)malloc(sizeof(double) * nowLayer->nodeNum);
for (size_t i = 0; i < nowLayer->nodeNum; i++) {
for (size_t j = 0; j < biasDeltaArrSize; j++) {
double bias_delta = biasDeltaArr[j] * nowLayer->nodeArr[i].weight[j] * BP_ActivationFunction(nowLayer->nodeArr[i].value);
nowLayer->nodeArr[i].bias_delta += bias_delta;
bias_delta_arr[i] = bias_delta;
}
}
free(biasDeltaArr);
return bias_delta_arr;
}
void Back_Propagation(Networks* networks, Data* data)
{
// 计算顺序: b0 ==> w1 b1 ==> w2 b2 ==> w3
// 求 outputLayer 的bias_delta,即b0
double* bias_delta_arr = (double*)malloc(sizeof(double) * networks->outputLayer->nodeNum);
for (size_t i = 0; i < networks->outputLayer->nodeNum; i++) {
double bias_delta = networks->outputLayer->nodeArr[i].value - data->outputData[i]; // softmax和交叉熵函数得求导结果为 yi-y
networks->outputLayer->nodeArr[i].bias_delta += bias_delta;
bias_delta_arr[i] = bias_delta;
}
// 计算 w1 b1 和 w2 b2
double* bias_delta_arr1 = Back_Propagation_Layer(networks->hideLayerTwo, bias_delta_arr, networks->outputLayer->nodeNum);
double* bias_delta_arr2 = Back_Propagation_Layer(networks->hideLayerOne, bias_delta_arr1, networks->hideLayerTwo->nodeNum);
// 计算 w3
for (size_t i = 0; i < networks->inputLayer->nodeNum; i++) {
for (size_t j = 0; j < networks->hideLayerOne->nodeNum; j++) {
double weight_delta = bias_delta_arr2[j] * networks->inputLayer->nodeArr[i].value;
networks->inputLayer->nodeArr[i].weight_delta[j] += weight_delta;
}
}
free(bias_delta_arr2);
}
void Update_Weights_Layer(Layer* nowlayer, Layer* nextlayer, double learning, size_t data_size)
{
// 计算 bais_delta
for (size_t i = 0; i < nowlayer->nodeNum; i++) {
double bais_delta = learning * nowlayer->nodeArr[i].bias_delta / data_size;
nowlayer->nodeArr[i].bias_delta -= bais_delta;
}
// 计算 weight_delta
for (size_t i = 0; i < nowlayer->nodeNum; i++) {
for (size_t j = 0; j < nextlayer->nodeNum; j++) {
double weight_delta = learning * nowlayer->nodeArr[i].weight_delta[j] / data_size;
nowlayer->nodeArr[i].weight[j] -= weight_delta;
}
}
}
void Update_Weights(Networks* networks, double learning, size_t data_size)
{
// w0 ==> b1 w1 ==> b2 w2 ==>b3
// num = num - learning * num_delta / data_size // 梯度的负方向,所以要减
// 更新 inputLayer 的 weight_delta
for (size_t i = 0; i < networks->inputLayer->nodeNum; i++) {
for (size_t j = 0; j < networks->hideLayerOne->nodeNum; j++) {
double weight_delta = learning * networks->inputLayer->nodeArr[i].weight_delta[j] / data_size;
networks->inputLayer->nodeArr[i].weight[j] -= weight_delta;
}
}
Update_Weights_Layer(networks->hideLayerOne, networks->hideLayerTwo, learning, data_size);
Update_Weights_Layer(networks->hideLayerTwo, networks->outputLayer, learning, data_size);
// 更新 outputLayer 的 bias_delta
for (size_t i = 0; i < networks->outputLayer->nodeNum; i++) {
double bais_delta = learning * networks->outputLayer->nodeArr[i].bias_delta / data_size;
networks->outputLayer->nodeArr[i].bias_delta -= bais_delta;
}
}
void empty_WB_Layer(Layer* layer, size_t weight_delta_arr_size)
{
for (size_t i = 0; i < layer->nodeNum; i++)
layer->nodeArr[i].bias_delta = 0.f;
for (size_t i = 0; i < layer->nodeNum; i++)
memset(layer->nodeArr[i].weight_delta, 0, sizeof(double) * weight_delta_arr_size);
}
void empty_WB(Networks* network)
{
// W0 ==> b1 w1 ==> b2 w2 ==>b3
for (size_t i = 0; i < network->inputLayer->nodeNum; i++)
memset(network->inputLayer->nodeArr[i].weight_delta, 0, sizeof(double) * network->hideLayerOne->nodeNum);
empty_WB_Layer(network->hideLayerOne, network->hideLayerTwo->nodeNum);
empty_WB_Layer(network->hideLayerTwo, network->outputLayer->nodeNum);
for (size_t i = 0; i < network->outputLayer->nodeNum; i++)
network->outputLayer->nodeArr[i].bias_delta = 0.f;
}
void SaveLayer(Layer* layer,size_t nextLayerSize ,FILE* fp)
{
for (size_t i = 0; i < layer->nodeNum; i++)
fwrite(layer->nodeArr[i].weight, sizeof(double) * nextLayerSize, 1, fp);
for (size_t i = 0; i < layer->nodeNum; i++)
fwrite(&layer->nodeArr[i].bias, sizeof(double), 1, fp);
}
void SaveNetworks(Networks* networks, const char* filename)
{
// b,w
FILE* fp = NULL;
if ((fp = fopen(filename, "wb")) == NULL)
printf("打开%s文件失败!\n", filename);
for (size_t i = 0; i < networks->inputLayer->nodeNum; i++)
fwrite(networks->inputLayer->nodeArr[i].weight, sizeof(double) * networks->hideLayerOne->nodeNum, 1, fp);
SaveLayer(networks->hideLayerOne, networks->hideLayerTwo->nodeNum, fp);
SaveLayer(networks->hideLayerTwo, networks->outputLayer->nodeNum, fp);
for (size_t i = 0; i < networks->outputLayer->nodeNum; i++)
fwrite(&networks->outputLayer->nodeArr[i].bias, sizeof(double), 1, fp);
fclose(fp);
}
void LoadLayer(Layer* layer, size_t nextLayerSize, FILE* fp)
{
for (size_t i = 0; i < layer->nodeNum; i++)
fread(layer->nodeArr[i].weight, sizeof(double) * nextLayerSize, 1, fp);
for (size_t i = 0; i < layer->nodeNum; i++)
fread(&layer->nodeArr[i].bias, sizeof(double), 1, fp);
}
void LoadNetworks(Networks* networks, const char* filename)
{
// b,w
FILE* fp = NULL;
if ((fp = fopen(filename, "rb")) == NULL)
printf("打开%s文件失败!\n", filename);
for (size_t i = 0; i < networks->inputLayer->nodeNum; i++)
fread(networks->inputLayer->nodeArr[i].weight, sizeof(double) * networks->hideLayerOne->nodeNum, 1, fp);
LoadLayer(networks->hideLayerOne, networks->hideLayerTwo->nodeNum, fp);
LoadLayer(networks->hideLayerTwo, networks->outputLayer->nodeNum, fp);
for (size_t i = 0; i < networks->outputLayer->nodeNum; i++)
fread(&networks->outputLayer->nodeArr[i].bias, sizeof(double), 1, fp);
fclose(fp);
}
void Free_Networks_Layer(Layer* layer)
{
for (size_t i = 0; i < layer->nodeNum; i++) {
if (layer->nodeArr[i].weight == NULL) {
free(layer->nodeArr[i].weight);
free(layer->nodeArr[i].weight_delta);
}
}
free(layer);
}
void Free_Networks(Networks* networks)
{
Free_Networks_Layer(networks->inputLayer);
Free_Networks_Layer(networks->hideLayerOne);
Free_Networks_Layer(networks->hideLayerTwo);
Free_Networks_Layer(networks->outputLayer);
free(networks);
}
void Free_Data(Data* data, size_t dataArrSize)
{
for (size_t i = 0; i < dataArrSize; i++) {
free(data[i].inputData);
free(data[i].outputData);
}
free(data);
}
int main()
{
// 真正测试时用release版
srand((size_t)time(NULL));
size_t maxTimes = 10000000;
double learning = 0.04;
double maxError = 0.2; // 单次最大误差
size_t train_data_size = 24;
size_t test_data_size = 8;
unsigned char cmd = 0; // 控制模型文件的读取和保存
char filename[260] = { 0 }; // 模型文件名
Data* trainData = (Data*)malloc(sizeof(Data) * train_data_size);
for (size_t i = 0; i < train_data_size; i++) {
trainData[i].inputData = (double*)malloc(sizeof(double) * INNODE);
trainData[i].outputData = (double*)malloc(sizeof(double) * OUTNODE);
}
for (size_t i = 0; i < 4; i++) {
for (size_t j = 0; j < train_data_size / 4; j++) {
char str[260] = { 0 };
sprintf(str, "%s%d_%d%s", "trainData\\", i + 1, j + 1, ".bmp");
GetfileData(&trainData[j + i * (train_data_size / 4)], str, i);
}
}
Data* testData = (Data*)malloc(sizeof(Data) * test_data_size);
for (size_t i = 0; i < test_data_size; i++) {
testData[i].inputData = (double*)malloc(sizeof(double) * INNODE);
testData[i].outputData = (double*)malloc(sizeof(double) * OUTNODE);
}
for (size_t i = 0; i < 4; i++) {
for (size_t j = 0; j < test_data_size / 4; j++) {
char str[260] = { 0 };
sprintf(str, "%s%d_%d%s", "testData\\", i + 1, j + 1, ".bmp");
GetfileData(&testData[j + i * (test_data_size / 4)], str, i); // 传入OUTNODE等于无结果
}
}
Networks* networks = InitNetworks();
// 控制语句
printf("是否加载已有的模型 ( Y | N )\n");
scanf("%c%*c", &cmd); // %*c去掉cmd
if (cmd == 'Y') {
printf("请输入模型文件名 ( Y | N )\n");
scanf("%[^\n]%*c", filename); // %[^\n]读取filename,%*c去掉'\n'
LoadNetworks(networks, filename);
goto test;
}
else {
system("cls");
printf("开始训练\n");
}
for (size_t times = 0; times < maxTimes; times++)
{
double max_error = 0.f;
for (size_t dataNum = 0; dataNum < train_data_size; dataNum++)
{
// 前向传播
Forward_Propagation(networks, &trainData[dataNum]);
// 用交叉熵损失函数计算误差
double error = 0.f;
for (size_t i = 0; i < networks->outputLayer->nodeNum; i++) {
double temp = -trainData[dataNum].outputData[i] * log(networks->outputLayer->nodeArr[i].value);
error += temp * temp / 2;
}
max_error = max(error, max_error);
// 反向传播
Back_Propagation(networks, &trainData[dataNum]);
}
// 更新权值
Update_Weights(networks, learning, train_data_size);
// 清空 weight_delta 和bias_delta
empty_WB(networks);
if (times / 10000 > 0 && times % 10000 == 0) {
printf("\n===========================================\n");
printf("%d %lf\n", times / 10000, max_error);
printf("\n===========================================\n");
}
// 每次结束判断误差是否小于maxError
if (max_error < maxError) {
printf("\n===========================================\n");
printf("%d %lf\n", times / 10000, max_error);
printf("\n===========================================\n");
break;
}
}
test:
// 测试
printf("\n");
for (size_t dataNum = 0; dataNum < test_data_size; dataNum++)
{
// 前向传播
Forward_Propagation(networks, &testData[dataNum]);
size_t maxID = 0;
for (size_t i = 0; i < OUTNODE; i++){
printf("%lf ", networks->outputLayer->nodeArr[i].value);
if (networks->outputLayer->nodeArr[i].value > networks->outputLayer->nodeArr[maxID].value)
maxID = i;
}
printf(" 检测结果%d %s\n", maxID + 1, "错误\0正确\0" + 5 * (int)testData[dataNum].outputData[maxID]); // 注意中文占两个字节
}
// 控制语句
printf("是否保存该模型? ( Y | N )\n");
scanf("%c%*c", &cmd); // %*c去掉cmd
if (cmd == 'Y') {
printf("请输入模型文件名 ( Y | N )\n");
scanf("%[^\n]%*c", filename); // %[^\n]读取filename,%*c去掉'\n'
SaveNetworks(networks, filename);
}
Free_Networks(networks);
Free_Data(trainData, train_data_size);
Free_Data(testData, test_data_size);
return 0;
}
七.问题
1.学习率不好控制。在用高学习率且运气好时,则loss下降很快,但大多数时候都是loss先上升,再缓慢下降,loss波动变化。用低学习率时,大多数时候loss下降很慢,loss变化趋于平缓。
2.训练的速度和运气有很大关系,如果运气好,loss下降很快,训练一般100万次以内就可完成,所以可以用高学习率赌运气。运气一般时,loss下降很慢,训练次数在500万次以内。运气很差时,训练次数在1000万次以内。
3.训练用的数据集太少了,导致大多数时候,数字2和3的识别出错,其它数字识别准确率变化不大。
八.结语
由于各种原因,该文章较为简短,后续作者可能会对其进行补充。
作者:墨尘_MO
时间:2022年9月4日















 2162
2162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









