







背景:
根据当前pod的负载,动态调整 pod副本数量,业务高峰期自动扩容pod的副本数以尽快响应pod的请求。
在业务低峰期对pod进行缩容,实现降本增效的目的。
动态伸缩控制器类型:
水平pod自动缩放器(HPA):基于pod 资源利用率横向调整pod副本数量。
垂直pod自动缩放器(VPA):基于pod资源利用率,调整对单个pod的最大资源限制,不能与HPA同时使用。
集群伸缩(Cluster Autoscaler,CA):基于集群中node 资源使用情况,动态伸缩node节点,从而保证有CPU和内存资源用于创建pod。
具体执行过程参照下图: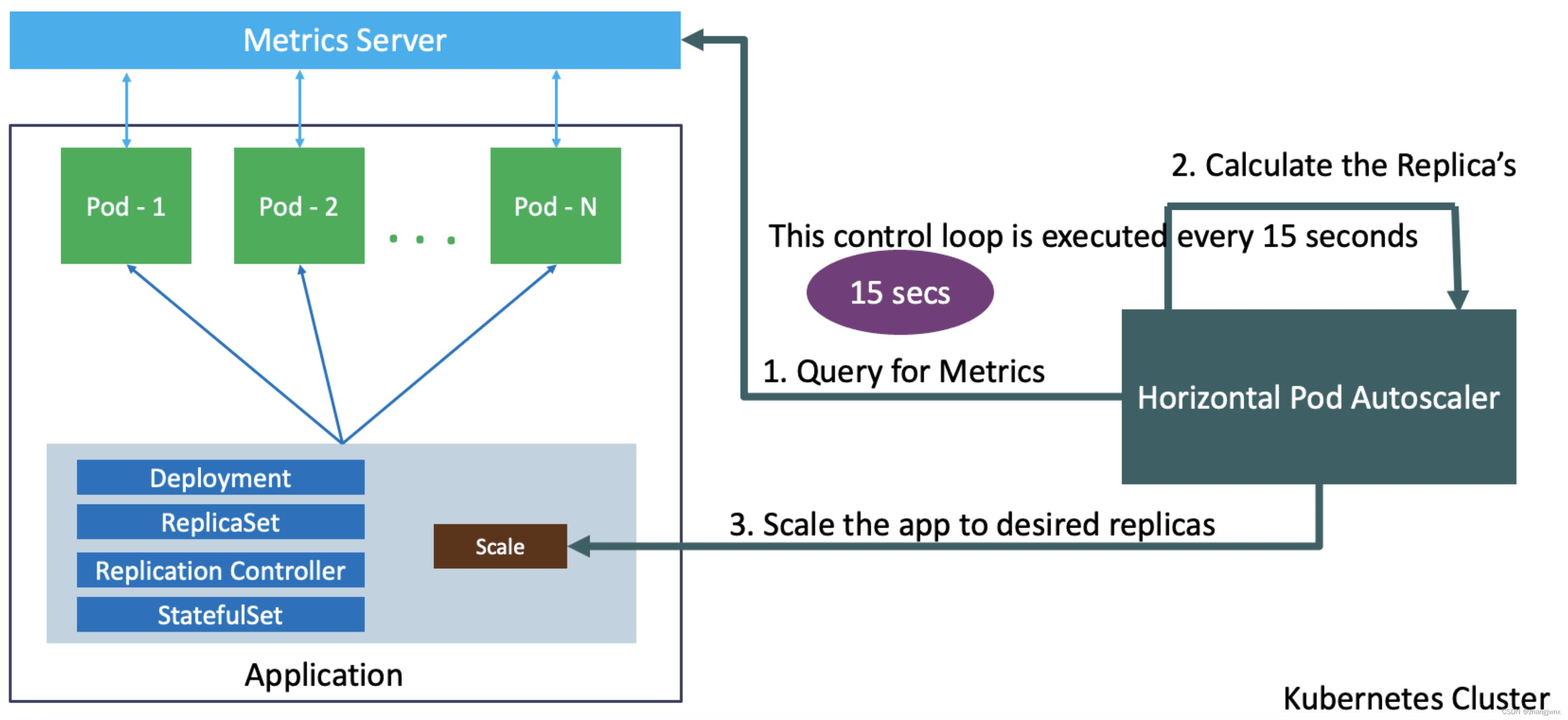
HPA控制器简介:
Horizontal Pod Autoscaling (HPA)控制器,根据预定义好的阈值及pod当前的资源利用率,自动控制在k8s集群中运行的pod数量(自动弹性水平自动伸缩).
指标说明:
horizontal-pod-autoscaler-sync-period #默认每隔15s(可以通过–horizontal-pod-autoscaler-sync-period修改)查询metrics的资源使用情况。
horizontal-pod-autoscaler-downscale-stabilization #缩容间隔周期,默认5分钟。
horizontal-pod-autoscaler-sync-period #HPA控制器同步pod副本数的间隔周期
horizontal-pod-autoscaler-cpu-initialization-period #初始化延迟时间,在此时间内 pod的CPU 资源指标将不会生效,默认为5分钟。
horizontal-pod-autoscaler-initial-readiness-delay #用于设置 pod 准备时间, 在此时间内的 pod 统统被认为未就绪及不采集数据,默认为30秒。
kube-controller-manager --help|grep horizontal-pod-autoscaler-downscale-stabilization #可以查看具体的默认值
注意:
horizontal-pod-autoscaler-tolerance #HPA控制器能容忍的数据差异(浮点数,默认为0.1),即新的指标要与当前的阈值差异在0.1或以上,即要大于1+0.1=1.1,或小于1-0.1=0.9,比如阈值为CPU利用率50%,当前为80%,那么80/50=1.6 > 1.1则会触发扩容,反之会缩容。即触发条件:avg(CurrentPodsConsumption) / Target >1.1 或 <0.9=把N个pod的数据相加后根据pod的数量计算出平均数除以阈值,大于1.1就扩容,小于0.9就缩容。
计算公式:TargetNumOfPods = ceil(sum(CurrentPodsCPUUtilization) / Target) #ceil是一个向上取整的目的pod整数。
指标数据需要部署metrics-server,即HPA使用metrics-server作为数据源。
部署metric-server
资源文件下载地址:
https://github.com/kubernetes-sigs/metrics-server
kubectl apply -f metrics-server.yaml #部署metric-server
kubectl top pod xxx -n ns #查看pod指标
kubectl top node xxx #查看node指标
实战案例【基于k8s1.24.2版本】:
tomcat.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: mytomcat
spec:
replicas: 5
selector:
matchLabels:
app: mytomcat
minReadySeconds: 1
progressDeadlineSeconds: 60
revisionHistoryLimit: 5
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
template:
metadata:
name: mytomcat
labels:
app: mytomcat
spec:
containers:
- name: mytomcat
image: tomcat:8
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: mytomcat
spec:
#type: NodePort
ports:
- port: 8080
#nodePort: 30090
selector:
app: mytomcat
hap.yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
namespace: demo
name: demo-tomcat-podautoscaler
labels:
app: demo-tomcat
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: mytomcat
minReplicas: 2
maxReplicas: 8
targetCPUUtilizationPercentage: 60
root@ubuntu01:/app# kubectl get pod -n demo
NAME READY STATUS RESTARTS AGE
myserver-nginx-deployment-56f4ccb9bd-9kjlc 1/1 Running 7 (47m ago) 14d
mytomcat-689d96db6f-4t9lh 1/1 Running 0 8m29s
mytomcat-689d96db6f-c29sl 1/1 Running 0 8m30s
mytomcat-689d96db6f-dhhmm 1/1 Running 0 6s
mytomcat-689d96db6f-vsmph 1/1 Running 0 7m35s
mytomcat-689d96db6f-w6fwq 1/1 Running 0 7m35s
root@ubuntu01:/app# kubectl describe hpa demo-tomcat-podautoscaler -n demo
Warning: autoscaling/v2beta2 HorizontalPodAutoscaler is deprecated in v1.23+, unavailable in v1.26+; use autoscaling/v2 HorizontalPodAutoscaler
Name: demo-tomcat-podautoscaler
Namespace: demo
Labels: app=demo-tomcat
Annotations: <none>
CreationTimestamp: Fri, 19 Aug 2022 21:32:01 +0800
Reference: Deployment/mytomcat
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 2% (2m) / 60%
Min replicas: 2
Max replicas: 8
Deployment pods: 2 current / 2 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ScaleDownStabilized recent recommendations were higher than current one, applying the highest recent recommendation
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited False DesiredWithinRange the desired count is within the acceptable range
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 3m40s horizontal-pod-autoscaler New size: 4; reason: All metrics below target
Normal SuccessfulRescale 54s horizontal-pod-autoscaler New size: 2; reason: All metrics below target
从上面可以看出由最初的5个pod副本数降为hpa控制器最小的2个
将上面deployment资源文件镜像修改为:
image: lorel/docker-stress-ng
args: [“–vm”,“2”,“–vm-bytes”,“256M”]
apiVersion: apps/v1
kind: Deployment
metadata:
name: mytomcat
spec:
replicas: 2
selector:
matchLabels:
app: mytomcat
minReadySeconds: 1
progressDeadlineSeconds: 60
revisionHistoryLimit: 5
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
template:
metadata:
name: mytomcat
labels:
app: mytomcat
spec:
containers:
- name: mytomcat
image: lorel/docker-stress-ng
args: ["--vm","2","--vm-bytes","256M"]
ports:
- containerPort: 8080
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 100m
memory: 100Mi
root@ubuntu01:/app# kubectl describe hpa demo-tomcat-podautoscaler -n demo
Warning: autoscaling/v2beta2 HorizontalPodAutoscaler is deprecated in v1.23+, unavailable in v1.26+; use autoscaling/v2 HorizontalPodAutoscaler
Name: demo-tomcat-podautoscaler
Namespace: demo
Labels: app=demo-tomcat
Annotations: <none>
CreationTimestamp: Fri, 19 Aug 2022 21:50:01 +0800
Reference: Deployment/mytomcat
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 87% (87m) / 60%
Min replicas: 2
Max replicas: 8
Deployment pods: 7 current / 8 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True SucceededRescale the HPA controller was able to update the target scale to 8
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited True TooManyReplicas the desired replica count is more than the maximum replica count
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 32m horizontal-pod-autoscaler New size: 4; reason: All metrics below target
Normal SuccessfulRescale 30m horizontal-pod-autoscaler New size: 2; reason: All metrics below target
Warning FailedGetScale 4m39s horizontal-pod-autoscaler deployments/scale.apps "mytomcat" not found
Warning FailedGetResourceMetric 4m9s (x2 over 4m24s) horizontal-pod-autoscaler failed to get cpu utilization: unable to get metrics for resource cpu: no metrics returned from resource metrics API
Warning FailedComputeMetricsReplicas 4m9s (x2 over 4m24s) horizontal-pod-autoscaler invalid metrics (1 invalid out of 1), first error is: failed to get cpu utilization: unable to get metrics for resource cpu: no metrics returned from resource metrics API
Warning FailedGetResourceMetric 3m54s horizontal-pod-autoscaler failed to get cpu utilization: did not receive metrics for any ready pods
Warning FailedComputeMetricsReplicas 3m54s horizontal-pod-autoscaler invalid metrics (1 invalid out of 1), first error is: failed to get cpu utilization: did not receive metrics for any ready pods
Normal SuccessfulRescale 2m54s horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 98s horizontal-pod-autoscaler New size: 5; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 83s horizontal-pod-autoscaler New size: 7; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 20s horizontal-pod-autoscaler New size: 8; reason: cpu resource utilization (percentage of request) above target
root@ubuntu01:/app# kubectl get pod -n demo
NAME READY STATUS RESTARTS AGE
myserver-nginx-deployment-56f4ccb9bd-9kjlc 1/1 Running 7 (83m ago) 14d
mytomcat-76798bc994-2gxxf 1/1 Running 0 5m51s
mytomcat-76798bc994-2z5cm 1/1 Running 0 4m35s
mytomcat-76798bc994-5s2tf 1/1 Running 0 4m20s
mytomcat-76798bc994-dlbgf 1/1 Running 0 4m20s
mytomcat-76798bc994-dncl4 1/1 Running 0 5m51s
mytomcat-76798bc994-f5b5c 1/1 Running 0 7m36s
mytomcat-76798bc994-r59j7 1/1 Running 0 3m17s
mytomcat-76798bc994-rzl5w 1/1 Running 0 7m36s
从图中可以看出扩容到8个副本数后即使还是超过阀值,但由于hpa控制器最大pod副本数为8,故到8个后pod副本数不在进行扩容。

















 968
968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









