






HPA简介
HPA(Horizontal Pod Autoscaler),Pod水平自动缩放器,可以根据Pod的负载动态调整Pod的副本数量,业务高峰期自动扩容Pod副本以满足业务请求。在业务低峰期自动缩容Pod,实现节约资源的目的。
与HPA相对的是VPA (Vertical Pod Autoscaler),Pod垂直自动缩放器,可以基于Pod的资源利用率,调整对单个Pod的最大资源限制,不能与HPA同时使用。
HPA隶属于autoscaling API群组目前主要有v1和v2两个版本:
| 版本 | 描述 |
|---|---|
| autoscaling/v1 | 只支持基于CPU指标的缩放 |
| autoscaling/v2 | 支持基于Resource Metrics(资源指标,例如Pod 的CPU和内存)、Custom Metrics(自定义指标)和External Metrics(额外指标)的缩放 |
部署metrics Server
HPA需要通过Metrics Server来获取Pod的资源利用率,所以需要先部署Metrics Server。
Metrics Server是Kubernetes 集群核心监控数据的聚合器,它负责从kubelet收集资源指标,然后对这些指标监控数据进行聚合,并通过Metrics API将它们暴露在Kubernetes apiserver中,供水平Pod Autoscaler和垂直Pod Autoscaler使用。也可以通过kubectl top node/pod查看指标数据
准备镜像
nerdctl pull bitnami/metrics-server:0.6.1
nerdctl tag bitnami/metrics-server:0.6.1 harbor-server.linux.io/kubernetes/metrics-server:0.6.1
nerdctl push harbor-server.linux.io/kubernetes/metrics-server:0.6.1
部署文件如下:
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
rbac.authorization.k8s.io/aggregate-to-admin: "true"
rbac.authorization.k8s.io/aggregate-to-edit: "true"
rbac.authorization.k8s.io/aggregate-to-view: "true"
name: system:aggregated-metrics-reader
rules:
- apiGroups:
- metrics.k8s.io
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
rules:
- apiGroups:
- ""
resources:
- nodes/metrics
verbs:
- get
- apiGroups:
- ""
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server-auth-reader
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:metrics-server
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
ports:
- name: https
port: 443
protocol: TCP
targetPort: https
selector:
k8s-app: metrics-server
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: metrics-server
strategy:
rollingUpdate:
maxUnavailable: 0
template:
metadata:
labels:
k8s-app: metrics-server
spec:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
image: harbor-server.linux.io/kubernetes/metrics-server:0.6.1
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /livez
port: https
scheme: HTTPS
periodSeconds: 10
name: metrics-server
ports:
- containerPort: 4443
name: https
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /readyz
port: https
scheme: HTTPS
initialDelaySeconds: 20
periodSeconds: 10
resources:
requests:
cpu: 100m
memory: 200Mi
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
volumeMounts:
- mountPath: /tmp
name: tmp-dir
nodeSelector:
kubernetes.io/os: linux
priorityClassName: system-cluster-critical
serviceAccountName: metrics-server
volumes:
- emptyDir: {}
name: tmp-dir
---
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
labels:
k8s-app: metrics-server
name: v1beta1.metrics.k8s.io
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: metrics-server
namespace: kube-system
version: v1beta1
versionPriority: 100
创建之后查看Pod状态:
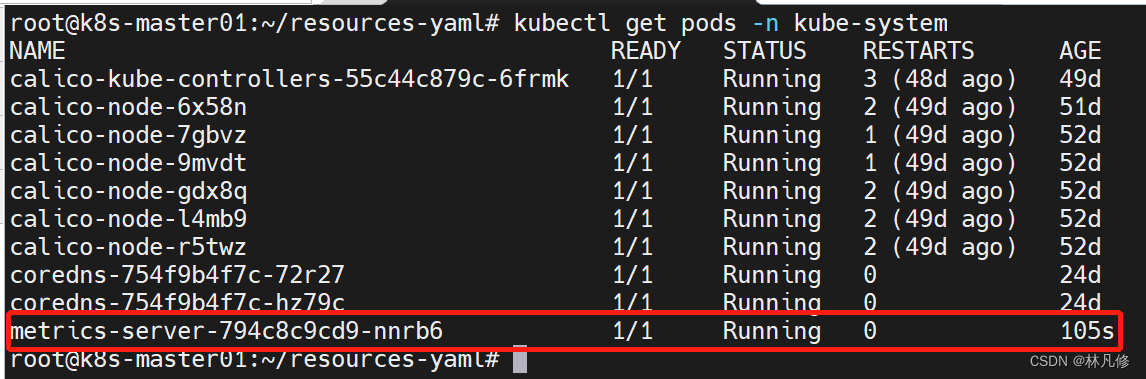
验证metrics-server是否工作
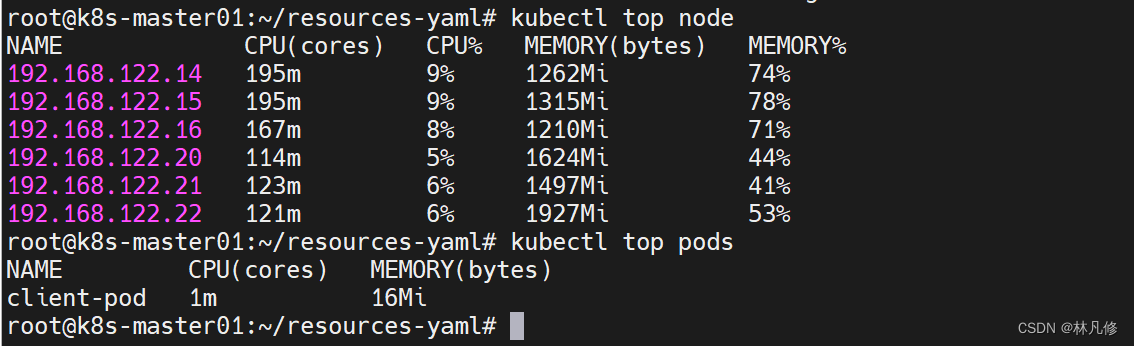
可以获取node和pod的资源指标就表示metrics-server可以正常工作
HPA配置参数
HPA控制器有一些重要配置参数,用于控制Pod缩放的行为,这些参数都可以在kube-controller的启动参数中配置:
- –horizontal-pod-autoscaler-sync-period:查询Pod资源利用率的时间间隔,默认15s查询一次
- –horizontal-pod-autoscaler-downscale-stabilization:两次缩容操作之间的最小间隔周期,默认5m
- –horizontal-pod-autoscaler-cpu-initialization-period:初始化延迟时间,在此期间内Pod的CPU指标将不生效,默认5m
- –horizontal-pod-autoscaler-initial-readiness-delay:用于设置Pod初始化时间,在此期间内内的Pod被认为未就绪不会被采集数据,默认30s
- –horizontal-pod-autoscaler-tolerance:HPA控制器能容忍的数据差异(浮点数,默认0.1),即当前指标与阈值的差异要在0.1之内,比如阈值设置的是CPU利率50%,如果当前CPU利用率为80%,那么80/50=1.6>1.1,就会触发扩容;如果当前CPU利用率为40%,40/50=0.8<0.9,就会触发缩容。大于1.1扩容,小于0.9缩容
HPA示例
下面使用HAP v1版本通过CPU指标实现Pod自动扩缩容。
自动缩容示例:
先部署一个5副本的nginx deployment,再通过HPA实现缩容:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deploy
labels:
app: nginx
spec:
replicas: 3
selector:
matchExpressions:
- {key: "app", operator: In, values: ["nginx"]}
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- name: http
containerPort: 80
resources: #如果要通过hpa实现pod的自动扩缩容,在必须对Pod设置资源限制,否则pod不会被hpa统计
requests:
cpu: 500m
memory: 512Mi
limits:
cpu: 1
memory: 1Gi
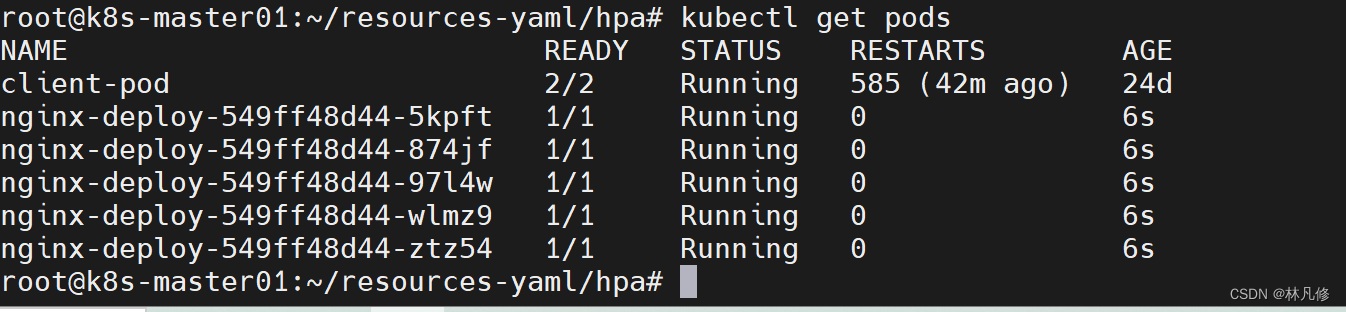
hpa部署文件如下,在hpa中定义了Pod cpu利用率阈值为80%,最小副本数为3,最大副本数为10:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: pod-autoscaler-demo
spec:
minReplicas: 3 #最小副本数
maxReplicas: 10 #最大副本数
scaleTargetRef: #hpa监控的资源对象
apiVersion: apps/v1
kind: Deployment
name: nginx-deploy
targetCPUUtilizationPercentage: 80 #cpu利用率阈值
创建完成后,查看hpa资源:

因为之前创建的nginx pod访问量较低,cpul利用率肯定不超过80%,所以等待一段时间就会触发缩容
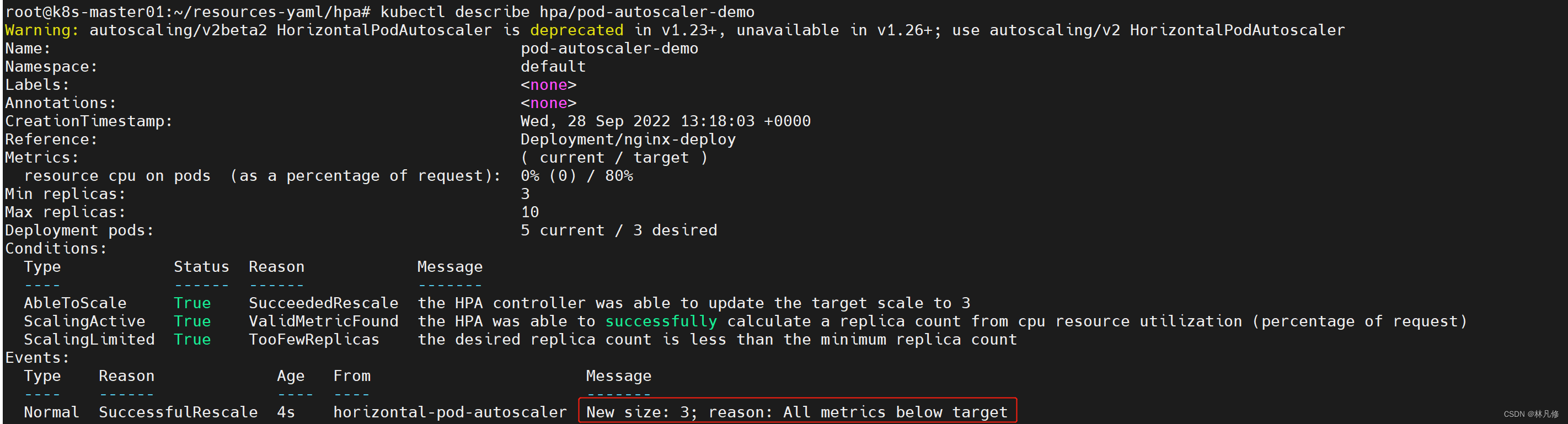
因为在hpa中定义的最小副本数为3,所以缩容到3个Pod就不会缩容了

自动扩容示例:
使用stress-ng镜像部署3个pod来测试自动扩容,stress-ng是一个压测工具:
apiVersion: apps/v1
kind: Deployment
metadata:
name: stress-ng-deploy
labels:
app: stress-ng
spec:
replicas: 3
selector:
matchExpressions:
- {key: "app", operator: In, values: ["stress-ng"]}
template:
metadata:
labels:
app: stress-ng
spec:
containers:
- name: stress-ng
image: lorel/docker-stress-ng
args: ["--vm", "2", "--vm-bytes", "512M"]
resources:
requests:
cpu: 500m
memory: 512Mi
limits:
cpu: 1
memory: 1Gi
hpa部署文件如下:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: pod-autoscaler-demo1
spec:
minReplicas: 3
maxReplicas: 10
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: stress-ng-deploy
targetCPUUtilizationPercentage: 80
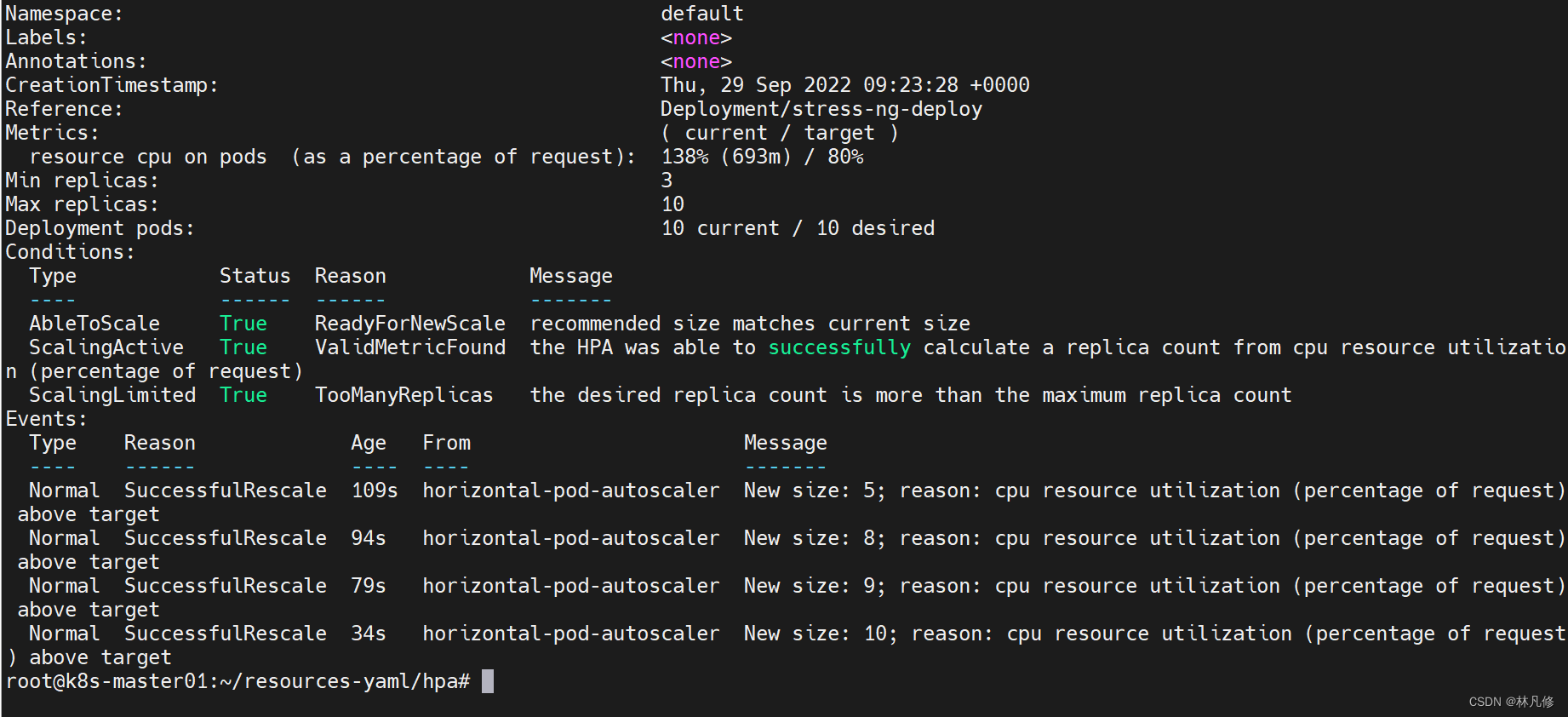
查看hpa资源:

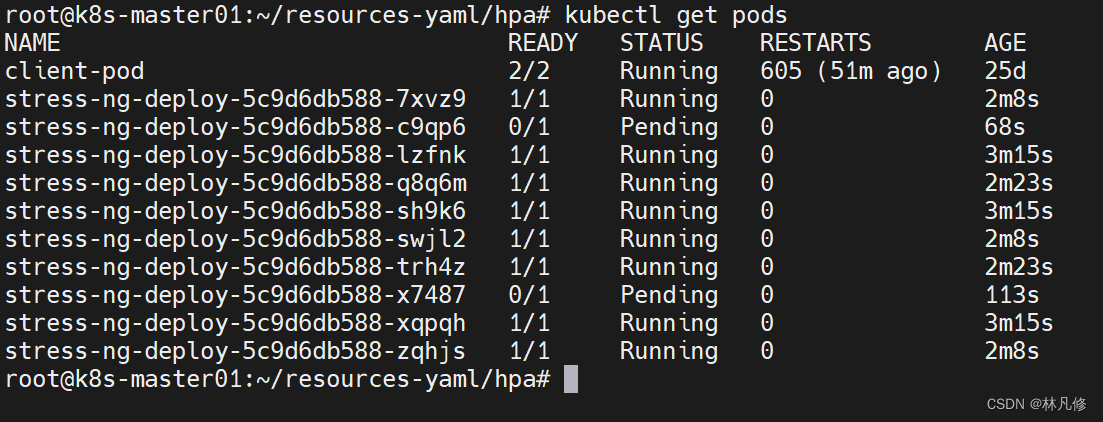
stress-ng会将Pod的cpu利用率打满,所以等待一段时间hpa就会逐步提高pod的副本数,如下图所示,但是在hpa中定义的最大副本数为10,所以最多扩容到10个Pod就不会扩容了















 423
423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









