






在该篇文章中,我将会对我使用C语言的正则表达式的过程进行一些记录,同时对其中的一些问题进行一定程度的解答,并对一些我无法回答的问题进行记录,希望有朝一日我能将这些问题成功解答出来。
首先我们的记录脉络是这样的,我会首先对C语言的脉络进行梳理,在C语言中使用正则表达式大抵是遵循以下的原则的:
(1) 编译规则,也就是将我们希望匹配的规则进行编译,以便处理更快速
regcomp就是这一步使用的函数
(2) 进行匹配,也就是我们根据我们的规则对我们的字符串进行匹配
regexec就是这一步使用的函数
接下来我们要看的是注意事项:
首先是使用regcomp时,int regcomp (regex_t *compiled, const char *pattern, int cflags)
这一步基本只有一点需要注意,那就是我们的cflags是什么意思:
REG_EXTENDED 以功能更加强大的扩展正则表达式的方式进行匹配。
REG_ICASE 匹配字母时忽略大小写。
REG_NOSUB 不用存储匹配后的结果。
REG_NEWLINE 识别换行符,这样'$'就可以从行尾开始匹配,'^'就可以从行的开头开始匹配。
说白了,这就是几种不同的匹配规则,就好像到底匹配的时候到底应该使用哪种匹配,一般我使用的时候就是使用扩展形式的正则表达式。
接下来是使用regexec时,
int regexec (regex_t *compiled, char *string, size_t nmatch, regmatch_t matchptr [], int eflags)
我主要的疑惑也就是由这一部分组成的:
其中nmatch和pmatch就是我们的匹配过程中最终会匹配得到的结果,这里经过我的验证,似乎使用的是以下的规则:
若是成功匹配得到,则会是以下的结果形式:
一是我们将会得到pmatch[0],其中储存的是我们的匹配的结果
而是我们若是使用pmatch[1],其代表的则是我们的子串,也就是第一次匹配结果中的其他子串部分:
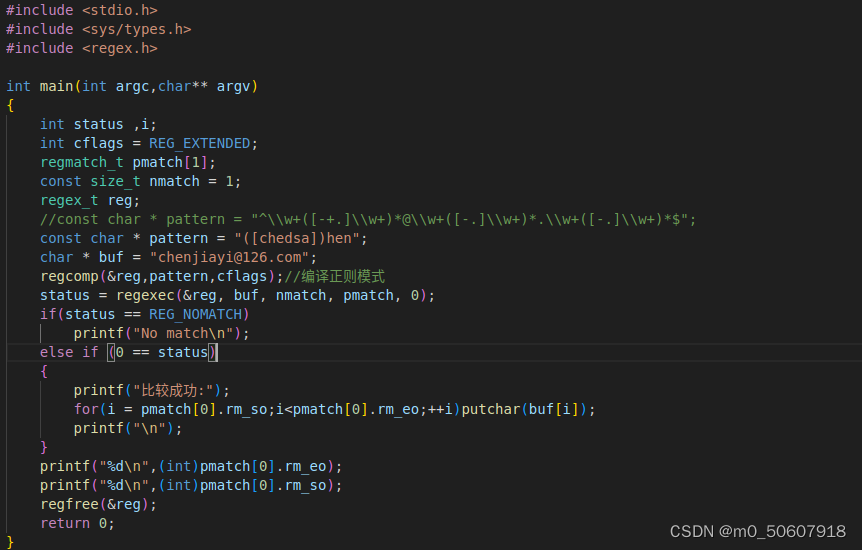
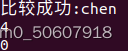
比如我们可以看到当我们进行匹配时,我们的pmatch[0]充当了我们的整体匹配结果的载体的效果,并且我们换为pmatch[1]后,我们的结果是如下的:

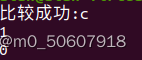
注意这里的区别只是到底使用的是pmatch的哪个元素罢了。
因此可以说我最大的疑惑就是:
到底怎么样才能匹配到所有的,全局的匹配呢,因为显然这里只能匹配到唯一一个符合标准的,真实令人头大啊!!
当然了,若是pmatch和nmatch不匹配,最后会报core dumped的错误,这是显然的,希望大家谨记。















 1608
1608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









