







一、MCPo介绍
1、MCPo (Model Context Protocol-to-OpenAPI Proxy Server) 概览
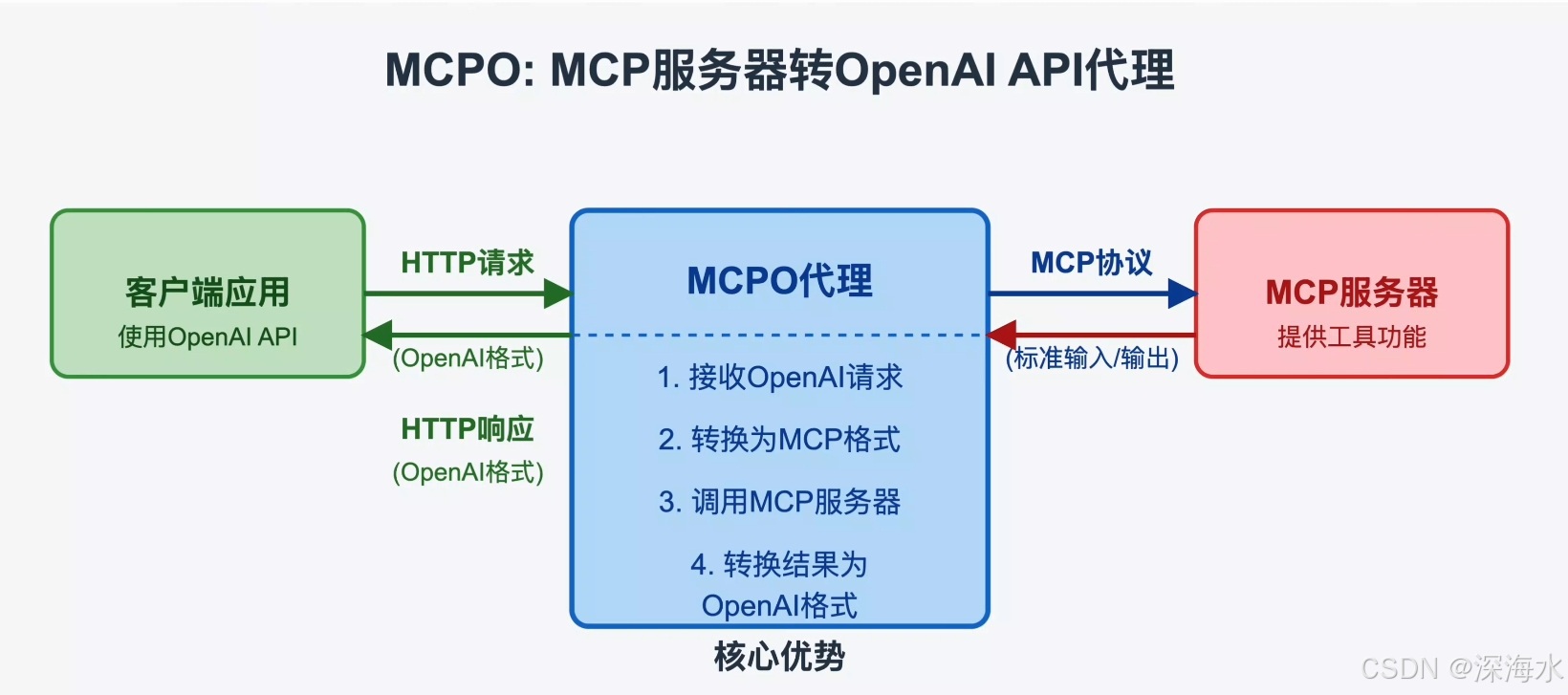
MCPo,全称为 Model Context Protocol-to-OpenAPI Proxy Server,是一个旨在弥合不同模型上下文协议(Model Context Protocol)与广泛使用的 OpenAPI 规范之间差距的代理服务器。简单来说,它的作用是将一种或多种特定的模型上下文协议转换为符合 OpenAPI 标准的接口描述,从而使得基于这些模型的服务能够更容易地被遵循 OpenAPI 规范的工具、平台和开发者所理解和使用。
2、核心概念解析
为了更好地理解 MCPo,我们先来了解一下其中涉及的关键概念:
- 模型上下文协议 (Model Context Protocol): 这是一个相对宽泛的概念,指的是用于描述和交互特定类型模型的协议或约定。这些模型可以是各种形式的数据模型、业务逻辑模型、AI 模型等等。不同的模型可能拥有不同的上下文信息、交互方式和数据格式,因此会存在不同的模型上下文协议。例如,一个特定的机器学习模型可能需要特定的输入格式和参数,并返回特定的输出结构,这就可以被视为一种模型上下文协议。
- OpenAPI (以前称为 Swagger): OpenAPI 规范是一种用于描述、生产、消费和可视化 RESTful API 的行业标准规范。它提供了一种机器可读的格式来定义 API 的所有方面,包括可用端点、操作、参数、请求体、响应体、安全方案等。OpenAPI 规范具有广泛的生态系统支持,包括代码生成工具、API 文档工具、测试工具等。
- 代理服务器 (Proxy Server): 在计算机网络中,代理服务器充当客户端和服务器之间的中介。当客户端向服务器发送请求时,请求首先到达代理服务器,然后代理服务器再将请求转发给目标服务器。代理服务器可以用于多种目的,例如安全、性能优化、协议转换等。
3、MCPo 的作用与解决的问题
MCPo 的主要作用是解决以下问题:
- 异构模型接口的标准化: 不同的模型可能使用不同的协议进行交互,这使得集成和管理这些模型变得复杂。MCPo 通过将这些协议转换为统一的 OpenAPI 规范,实现了接口的标准化。
- 提升模型服务的可发现性和易用性: OpenAPI 规范具有广泛的生态系统支持。通过将模型服务暴露为 OpenAPI 接口,可以更容易地使用各种 OpenAPI 工具(如 Swagger UI、Swagger Codegen 等)来发现、测试和集成这些服务。
- 简化模型服务的集成: 遵循 OpenAPI 规范的工具和平台可以自动理解和使用 MCPo 转换后的模型服务,从而简化了集成过程。
- 促进模型服务的生态建设: 通过提供一个标准的接口描述,MCPo 有助于构建围绕特定模型服务的生态系统,吸引更多的开发者和工具参与进来。
4、MCPo 的工作原理
MCPo 作为代理服务器,其核心工作原理是将接收到的符合特定模型上下文协议的请求,根据预先定义的转换规则,将其转化为符合 OpenAPI 规范的 HTTP 请求,并转发给实际的模型服务。同时,它也会将模型服务返回的响应按照 OpenAPI 规范进行封装,并返回给客户端。
具体来说,MCPo 的工作流程可能包括以下步骤:
- 接收模型上下文协议请求: MCPo 监听特定的端口或接口,接收来自客户端的符合某种模型上下文协议的请求。
- 协议解析与转换: MCPo 内部会包含针对不同模型上下文协议的解析逻辑。它会解析接收到的请求,提取关键信息(例如,需要调用的模型功能、输入参数等)。然后,根据预先配置的转换规则,将这些信息映射到符合 OpenAPI 规范的 HTTP 请求(例如,HTTP 方法、路径、请求参数、请求体等)。
- 转发给模型服务: 转换后的 HTTP 请求被转发给实际部署的模型服务。
- 接收模型服务响应: 模型服务处理请求后,将响应返回给 MCPo。
- 响应转换与封装: MCPo 接收到模型服务的响应后,会根据 OpenAPI 规范的要求,将响应数据进行转换和封装(例如,设置 HTTP 状态码、响应头、响应体等)。
- 返回给客户端: 最终,MCPo 将符合 OpenAPI 规范的响应返回给最初发起请求的客户端。
5、MCPo 的关键特性和功能
一个典型的 MCPo 可能会包含以下关键特性和功能:
- 多协议支持: 能够支持多种不同的模型上下文协议,并将其转换为 OpenAPI 规范。这可能需要针对每种协议实现特定的解析和转换逻辑。
- 灵活的转换规则配置: 允许用户自定义模型上下文协议到 OpenAPI 规范的映射规则,以适应不同的模型和服务。
- OpenAPI 规范兼容性: 生成的接口描述必须符合 OpenAPI 规范,以便能够被各种 OpenAPI 工具所使用。
- 请求和响应的拦截与处理: 能够拦截请求和响应,进行额外的处理,例如数据校验、安全认证、日志记录等。
- 可扩展性: 易于扩展以支持新的模型上下文协议或自定义的转换逻辑。
- 性能优化: 具备一定的性能优化能力,以确保请求的快速转发和响应。
- 安全特性: 可能包含一些安全特性,例如身份验证、授权等,以保护模型服务的安全。
- 监控和日志: 提供监控和日志记录功能,方便用户了解 MCPo 的运行状态和问题排查。
6、MCPo 的优势
使用 MCPo 可以带来以下优势:
- 统一的接口标准: 将各种不同的模型服务统一到 OpenAPI 规范下,方便管理和集成。
- 降低集成成本: 开发者可以使用标准的 OpenAPI 工具和流程来与模型服务进行交互,降低了学习和集成成本。
- 提升开发效率: 借助 OpenAPI 生态系统中的工具(如代码生成、文档生成等),可以显著提升开发效率。
- 促进模型服务的共享和重用: 通过标准化的接口描述,更容易发现和重用已有的模型服务。
- 增强互操作性: 使得不同系统和平台之间更容易地利用彼此的模型能力。
MCPo 是构建 智能企业代理系统(AI Agent) 的关键组成,可应用于:
-
智能问答系统对接业务系统
-
企业多系统数据整合
-
通过自然语言控制业务流程
-
接入 RPA / 自动化工作流平台
-
AI + BPM / AI + ERP 系统搭建
7、MCPo 的潜在应用场景
MCPo 可以应用于各种需要集成和管理不同类型模型的场景,例如:
- AI 模型服务化: 将各种机器学习、深度学习模型通过 MCPo 转换为 OpenAPI 接口,方便其他应用调用。
- 遗留系统集成: 将一些使用自定义协议的遗留系统模型通过 MCPo 暴露为标准的 OpenAPI 服务,方便与现代系统集成。
- 多模态数据处理: 对于涉及多种类型数据和模型的应用,可以使用 MCPo 统一接口,简化开发。
- 微服务架构: 在微服务架构中,不同的服务可能使用不同的协议,可以使用 MCPo 将其统一为 OpenAPI 接口,方便服务之间的调用和管理。
- 数据分析平台: 将各种数据分析模型通过 MCPo 暴露为 OpenAPI 接口,供数据科学家和业务用户使用。
8、 架构与功能组件
MCPo 的目的是:
让 LLM 像人类一样通过理解文档(如 OpenAPI 规范)来调用系统接口。
也就是说,它让模型可以「读懂接口文档」,然后根据用户的自然语言请求,自动转换为对应的 API 调用并执行,再将结果返回给模型或者用户。
MCPo 通常包含以下几个关键组成部分:
| 模块 | 说明 |
|---|---|
| OpenAPI Parser | 解析 OpenAPI 文档(通常是 YAML / JSON 格式),提取接口路径、参数、方法、说明等。 |
| Prompt Generator | 将结构化 API 描述转换为自然语言提示,供 LLM 理解或用于提示学习。 |
| Function Call Proxy | 如果模型支持函数调用(如 OpenAI GPT-4 Function Call),MCPo 会将 API 描述注册为函数签名,供模型调用。 |
| Request Executor | 接收到模型“决定”调用某接口后,MCPo 负责发起真实的 HTTP 请求。 |
| Response Normalizer | 将 API 响应结果转换为结构化(或语言模型适用的)格式。 |
| Context Memory(可选) | 记录调用历史、参数选择、模型偏好等,为多轮交互优化体验。 |
9、 工作流程示意
假设用户输入:
“帮我查一下张三在系统里的审批流程状态。”
MCPo 背后执行如下步骤:
-
识别意图: 这是一个“审批流程查询”类请求。
-
查找匹配接口: MCPo 查询 OpenAPI 文档,发现
/workflow/status?user_name=xxx是匹配的接口。 -
生成 Prompt / 函数调用:
{
"function_call": {
"name": "getWorkflowStatus",
"arguments": {
"user_name": "张三"
}
}
}
-
发起 API 请求: MCPo 发起真实 HTTP 请求。
-
处理返回结果: 将返回的 JSON 响应结构化或语言化返回给模型。
-
返回给用户: 模型将输出:“张三的审批流程当前状态是‘等待领导审批’。”
10、安全性与控制
由于 MCPo 会调用实际的系统 API,具备以下控制机制十分重要:
| 控制方式 | 描述 |
|---|---|
| 权限控制 | 限制哪些接口可以暴露给模型 |
| 参数白名单 | 限制用户输入参数范围 |
| 请求审计 | 日志记录模型发起的所有请求 |
| 沙箱环境 | 开发和测试时对接 mock API 或测试环境 |
11、开源实现参考
目前没有统一的“官方 MCPo”项目,但以下项目具备类似功能或可作为 MCPo 的构建基础:
-
LangChain + OpenAPI Toolkit
-
提供自动将 OpenAPI 规范变成工具的功能
-
-
OpenAI Function Calling + LangChain Tool Agent
-
把 OpenAPI 的接口变成可调用函数
-
-
Griptape、CrewAI、AutoGen 等 Agent Framework
-
支持将接口注册为工具、由智能体根据需要调用
-
12、总结
MCPo (Model Context Protocol-to-OpenAPI Proxy Server) 是一种关键的技术,它通过充当代理服务器,将各种特定的模型上下文协议转换为标准的 OpenAPI 规范。这极大地简化了不同模型服务的集成、管理和使用,提升了模型服务的可发现性和互操作性,并促进了围绕模型服务的生态建设。随着各种模型和 AI 技术的不断发展,MCPo 这类工具的重要性也将日益凸显。
二、 构建一个本地运行、支持 SQLite 数据智能分析的 MCPo 原型系统
1、目标架构:MCPo + SQLite 智能分析系统
系统能力:
-
读取并解析一个 SQLite 数据库结构
-
自动生成符合 OpenAPI 格式的接口(如:查询表、按条件筛选、聚合等)
-
LLM(如 GPT-4)通过自然语言调用这些 API
-
MCPo 作为中间件,翻译请求 → 执行 SQL → 返回结构化结果
-
可嵌入 Streamlit 或 Web UI 前端
2、项目结构设计
mcpo_sqlite_agent/
├── mcpo/
│ ├── openapi.yaml # 自动生成或手写的 OpenAPI 文档
│ ├── main.py # FastAPI MCPo Proxy Server
│ ├── db_utils.py # SQLite 工具类
│ ├── prompt_generator.py # 可选:自动构造 LLM 的提示内容
├── agent/
│ └── langchain_agent.py # LangChain 智能体,支持 Function Call
├── frontend/
│ └── app.py # Streamlit 可视化界面
├── data/
│ └── sample.db # 示例 SQLite 数据库
├── Dockerfile
├── requirements.txt
└── README.md
3、核心模块内容
1️⃣ openapi.yaml 示例(简版)
openapi: 3.0.0
info:
title: SQLite Query API
version: 1.0.0
paths:
/query_table:
get:
summary: 查询指定表的数据
parameters:
- in: query
name: table
schema:
type: string
required: true
- in: query
name: limit
schema:
type: integer
default: 10
responses:
'200':
description: 表数据
/query_custom:
post:
summary: 执行自定义 SQL 查询
requestBody:
content:
application/json:
schema:
type: object
properties:
query:
type: string
responses:
'200':
description: 查询结果
2️⃣ main.py(FastAPI 启动)
from fastapi import FastAPI, Request
from mcpo.db_utils import execute_query, get_table_data
import uvicorn
app = FastAPI()
@app.get("/query_table")
def query_table(table: str, limit: int = 10):
return get_table_data(table, limit)
@app.post("/query_custom")
async def query_custom(request: Request):
body = await request.json()
query = body.get("query", "")
return execute_query(query)
if __name__ == "__main__":
uvicorn.run("main:app", port=8000, reload=True)
3️⃣ db_utils.py
import sqlite3
DB_PATH = "./data/sample.db"
def get_table_data(table: str, limit: int = 10):
with sqlite3.connect(DB_PATH) as conn:
cursor = conn.cursor()
result = cursor.execute(f"SELECT * FROM {table} LIMIT ?", (limit,))
columns = [desc[0] for desc in cursor.description]
return [dict(zip(columns, row)) for row in result.fetchall()]
def execute_query(query: str):
with sqlite3.connect(DB_PATH) as conn:
cursor = conn.cursor()
result = cursor.execute(query)
try:
columns = [desc[0] for desc in cursor.description]
return [dict(zip(columns, row)) for row in result.fetchall()]
except:
return {"message": "query executed"}
4️⃣ langchain_agent.py(Agent 实现,调用 OpenAPI 工具)
from langchain.agents import initialize_agent, AgentType
from langchain.tools import Tool
from langchain.chat_models import ChatOpenAI
import requests
def query_sqlite_with_prompt(prompt: str):
response = requests.post("http://localhost:8000/query_custom", json={"query": prompt})
return response.json()
tools = [
Tool.from_function(
name="SQLiteQuery",
func=query_sqlite_with_prompt,
description="对 SQLite 数据库执行 SQL 查询"
)
]
llm = ChatOpenAI(temperature=0, model="gpt-4")
agent = initialize_agent(
tools=tools,
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
def run_agent(prompt):
return agent.run(prompt)
5️⃣ app.py(Streamlit 可视化界面)
import streamlit as st
from agent.langchain_agent import run_agent
st.title("🧠 MCPo SQLite 智能分析 Agent")
user_query = st.text_input("请输入你的问题:", "查一下员工表中工资最高的5个人")
if st.button("执行"):
with st.spinner("分析中..."):
result = run_agent(user_query)
st.json(result)
🐳 Dockerfile 示例
FROM python:3.10-slim
WORKDIR /app
COPY . .
RUN pip install --no-cache-dir -r requirements.txt
EXPOSE 8000
CMD ["uvicorn", "mcpo.main:app", "--host", "0.0.0.0", "--port", "8000"]
三、 构建一个本地运行的 MCPo + SQLite 智能分析系统
从零构建一个本地运行的 MCPo + SQLite 智能分析系统。这个系统将包括:
-
一个 SQLite 示例数据库
-
一个 FastAPI MCPo Proxy 服务
-
一个 LangChain 智能体,支持自然语言转 SQL
-
一个 Streamlit 前端界面
1、第一步:准备开发环境
建议你先新建一个工作目录,比如:
mkdir mcpo_sqlite_agent && cd mcpo_sqlite_agent
然后创建一个虚拟环境并安装依赖:
python -m venv venv
source venv/bin/activate # Windows 用 venv\Scripts\activate
pip install fastapi uvicorn langchain openai streamlit sqlite-utils
🔐 如果要用 GPT-4,请准备好 OpenAI API Key,并设置环境变量:
export OPENAI_API_KEY=sk-xxxxx # Windows 用 set
2、第二步:创建 SQLite 示例数据库
创建一个 data/sample.db 数据库,并建个表,比如 employees:
mkdir data
# create_db.py
import sqlite3
conn = sqlite3.connect("data/sample.db")
cursor = conn.cursor()
cursor.execute("""
CREATE TABLE employees (
id INTEGER PRIMARY KEY,
name TEXT,
department TEXT,
salary INTEGER,
hire_date TEXT
)
""")
cursor.executemany("""
INSERT INTO employees (name, department, salary, hire_date)
VALUES (?, ?, ?, ?)
""", [
("张三", "技术部", 12000, "2020-01-10"),
("李四", "销售部", 9000, "2019-05-22"),
("王五", "技术部", 15000, "2021-03-15"),
("赵六", "市场部", 8000, "2018-07-30"),
("周七", "人事部", 7000, "2020-11-01")
])
conn.commit()
conn.close()
运行一次创建数据库:
python create_db.py
3、第三步:构建 MCPo 接口服务(FastAPI)
创建文件 mcpo.py:
# mcpo.py
from fastapi import FastAPI, Request
import sqlite3
app = FastAPI()
DB_PATH = "data/sample.db"
@app.get("/query_table")
def query_table(table: str, limit: int = 10):
with sqlite3.connect(DB_PATH) as conn:
cursor = conn.cursor()
result = cursor.execute(f"SELECT * FROM {table} LIMIT ?", (limit,))
columns = [desc[0] for desc in cursor.description]
return [dict(zip(columns, row)) for row in result.fetchall()]
@app.post("/query_custom")
async def query_custom(request: Request):
data = await request.json()
query = data.get("query", "")
with sqlite3.connect(DB_PATH) as conn:
cursor = conn.cursor()
try:
result = cursor.execute(query)
columns = [desc[0] for desc in cursor.description]
return [dict(zip(columns, row)) for row in result.fetchall()]
except:
return {"message": "Query executed"}
运行服务:
uvicorn mcpo:app --reload --port 8000
测试接口:
curl "http://localhost:8000/query_table?table=employees&limit=3"
4、第四步:构建 LLM 智能体调用 MCPo 接口
创建 agent.py:
# agent.py
import requests
from langchain.agents import initialize_agent, AgentType
from langchain.chat_models import ChatOpenAI
from langchain.tools import Tool
def call_sql_api(prompt: str):
response = requests.post("http://localhost:8000/query_custom", json={"query": prompt})
return response.json()
tool = Tool.from_function(
name="SQLiteTool",
description="执行 SQL 查询的工具,用于分析企业员工数据",
func=call_sql_api
)
llm = ChatOpenAI(temperature=0, model="gpt-4") # 或 gpt-3.5-turbo
agent = initialize_agent(
tools=[tool],
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
def ask_agent(query: str):
return agent.run(query)
5、第五步:构建前端界面(Streamlit)
创建 app.py:
# app.py
import streamlit as st
from agent import ask_agent
st.set_page_config(page_title="MCPo 智能 SQLite 查询助手")
st.title("🧠 MCPo SQLite 智能分析")
query = st.text_input("请输入你的问题:", "查询技术部工资最高的员工")
if st.button("执行"):
with st.spinner("思考中..."):
result = ask_agent(query)
st.json(result)
运行前端:
streamlit run app.py
✅ 第一次启动 Checklist
-
SQLite 数据创建成功
-
FastAPI 8000 端口已启动
-
OpenAI Key 可用
-
Streamlit 能运行并调用 Agent
四、支持多表 / 自定义 OpenAPI 规范
✅ 支持多表自动分析 + 自定义 OpenAPI 规范生成,为 MCPo Proxy Server 打下一个更强大的基础!
1、功能目标
希望达到:
-
自动列出当前数据库所有表名(
/tables接口) -
自动列出某张表的字段名与字段类型(
/schema?table=xxx接口) -
自动生成 OpenAPI 规范(
/openapi或导出 YAML) -
智能体能通过表名 + 字段自动构造 SQL
2、db_utils.py:数据库工具函数(支持多表)
创建 db_utils.py:
import sqlite3
DB_PATH = "data/sample.db"
def list_tables():
with sqlite3.connect(DB_PATH) as conn:
cursor = conn.cursor()
cursor.execute("SELECT name FROM sqlite_master WHERE type='table'")
return [row[0] for row in cursor.fetchall()]
def get_table_schema(table):
with sqlite3.connect(DB_PATH) as conn:
cursor = conn.cursor()
cursor.execute(f"PRAGMA table_info({table})")
return [
{"column": row[1], "type": row[2], "notnull": bool(row[3]), "pk": bool(row[5])}
for row in cursor.fetchall()
]
def query_table(table, limit=10):
with sqlite3.connect(DB_PATH) as conn:
cursor = conn.cursor()
result = cursor.execute(f"SELECT * FROM {table} LIMIT ?", (limit,))
columns = [desc[0] for desc in cursor.description]
return [dict(zip(columns, row)) for row in result.fetchall()]
def execute_sql(query):
with sqlite3.connect(DB_PATH) as conn:
cursor = conn.cursor()
result = cursor.execute(query)
try:
columns = [desc[0] for desc in cursor.description]
return [dict(zip(columns, row)) for row in result.fetchall()]
except:
return {"message": "Query executed"}
3、修改 mcpo.py:支持多表 + 自定义 schema API
更新后的 mcpo.py:
from fastapi import FastAPI, Request
from db_utils import list_tables, get_table_schema, query_table, execute_sql
app = FastAPI()
@app.get("/tables")
def get_tables():
return list_tables()
@app.get("/schema")
def get_schema(table: str):
return get_table_schema(table)
@app.get("/query_table")
def get_table_data(table: str, limit: int = 10):
return query_table(table, limit)
@app.post("/query_custom")
async def query_custom(request: Request):
body = await request.json()
query = body.get("query", "")
return execute_sql(query)
启动 FastAPI:
uvicorn mcpo:app --reload --port 8000
✅ 测试接口:
curl http://localhost:8000/tables
curl "http://localhost:8000/schema?table=employees"
4、自动生成 OpenAPI 规范(OpenAPI YAML 导出)
可以使用如下方法导出 OpenAPI JSON / YAML:
curl http://localhost:8000/openapi.json > openapi.json
然后使用工具转换为 YAML(可选):
pip install pyyaml
python -c "import json, yaml; yaml.safe_dump(json.load(open('openapi.json')), open('openapi.yaml','w'))"
LLM Agent 提示优化建议(自动构造)
可以让 LLM 使用
/tables和/schema?table=xxx来“了解数据库结构”,再生成 SQL,再通过/query_custom执行查询!
比如构造提示:
你正在访问一个 SQLite 数据库,有如下表结构:
- employees: id, name, department, salary, hire_date
请根据用户输入的问题,构造合适的 SQL 查询,并返回结果(不解释 SQL,只写 SQL)。
用户问题:查一下技术部工资最高的员工
五、构建 Prompt Generator
构建一个 Prompt Generator 模块,用于:
✅ 自动读取数据库的所有表和字段结构
✅ 自动生成 LLM 可用的上下文提示,用于更准确地构造 SQL 查询
1、整体结构
创建一个模块 prompt_generator.py,它负责:
-
调用 MCPo 的
/tables和/schemaAPI -
获取数据库结构信息
-
将其转换成自然语言提示(用于 Agent)
-
支持缓存,避免每次都调用 API(可选)
2、示例目标 Prompt
目标效果如下:
可以访问一个 SQLite 企业管理数据库,结构如下:
表:employees
字段:
- id: INTEGER, 主键
- name: TEXT
- department: TEXT
- salary: INTEGER
- hire_date: TEXT
用户的问题将基于以上表结构,请生成合理的 SQL 查询,返回结果而不解释 SQL。
3、 实现:prompt_generator.py
# prompt_generator.py
import requests
BASE_URL = "http://localhost:8000"
def get_all_tables():
return requests.get(f"{BASE_URL}/tables").json()
def get_table_schema(table_name):
return requests.get(f"{BASE_URL}/schema", params={"table": table_name}).json()
def generate_schema_prompt():
tables = get_all_tables()
prompt = "你可以访问一个 SQLite 企业管理数据库,结构如下:\n\n"
for table in tables:
schema = get_table_schema(table)
prompt += f"表:{table}\n字段:\n"
for column in schema:
col_line = f"- {column['column']}: {column['type']}"
if column["pk"]:
col_line += ",主键"
if column["notnull"]:
col_line += ",不能为空"
prompt += col_line + "\n"
prompt += "\n"
prompt += "请根据用户提出的问题,构造合理的 SQL 查询,并返回查询结果(不要解释 SQL)。"
return prompt
4、在 agent.py 中使用 Prompt
修改Agent 调用逻辑(agent.py)如下:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from prompt_generator import generate_schema_prompt
import requests
llm = ChatOpenAI(temperature=0, model="gpt-4")
def call_sql_api(sql_query: str):
res = requests.post("http://localhost:8000/query_custom", json={"query": sql_query})
return res.json()
def ask_agent(user_question: str):
schema_info = generate_schema_prompt()
full_prompt = f"{schema_info}\n\n用户问题:{user_question}\n请直接给出对应 SQL:"
chain = LLMChain(
llm=llm,
prompt=PromptTemplate(
input_variables=["input"],
template="{input}"
)
)
sql_query = chain.run(full_prompt)
print(f"🔎 生成 SQL:{sql_query}")
return call_sql_api(sql_query)
5、效果预览
运行前端 app.py 时输入:
查询工资最高的技术部员工是谁?
后台打印:
🔎 生成 SQL:SELECT * FROM employees WHERE department = '技术部' ORDER BY salary DESC LIMIT 1;
结果直接展示在页面中
6、Bonus:缓存表结构(提高性能)
如果担心频繁请求 /schema 慢,可以在 prompt_generator.py 中加上缓存机制,比如使用 functools.lru_cache:
from functools import lru_cache
@lru_cache()
def get_all_tables_cached():
return get_all_tables()
@lru_cache()
def get_table_schema_cached(table_name):
return get_table_schema(table_name)
7、当前模块一览
mcpo_sqlite_agent/
├── app.py # 前端交互
├── agent.py # 调用 LLM 并执行 SQL
├── prompt_generator.py # 自动生成 LLM Prompt
├── mcpo.py # FastAPI 服务
├── db_utils.py # SQLite 查询工具
├── create_db.py # 初始化数据库
└── data/sample.db # 示例数据
六、用 GPT 自动生成自然语言回答
升级 Agent 系统:
✅ 在执行完 SQL 查询后,用 GPT 自动生成自然语言回答,让用户看到的是“结果解释”而不是“原始数据表”。
1、整体目标
-
✅ 用户输入自然语言问题
-
✅ GPT 生成 SQL(保留已有流程)
-
✅ 执行 SQL 得到数据表格
-
✅ GPT 读取查询结果,自动总结回答(自然语言说明)
2、 修改 Agent:新增数据解释模块
升级 agent.py,加入“结果解释”:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from prompt_generator import generate_schema_prompt
import requests
import json
llm = ChatOpenAI(temperature=0, model="gpt-4")
def call_sql_api(sql_query: str):
res = requests.post("http://localhost:8000/query_custom", json={"query": sql_query})
return res.json()
def ask_agent(user_question: str):
schema_info = generate_schema_prompt()
# 1. 生成 SQL
full_prompt = f"{schema_info}\n\n用户问题:{user_question}\n请直接给出对应 SQL:"
sql_chain = LLMChain(
llm=llm,
prompt=PromptTemplate(input_variables=["input"], template="{input}")
)
sql_query = sql_chain.run(full_prompt).strip()
print(f"🔎 生成 SQL:{sql_query}")
# 2. 执行 SQL
query_result = call_sql_api(sql_query)
# 3. 用 GPT 生成自然语言解释
explain_prompt = f"""你是一个数据库分析专家。用户提出了问题:"{user_question}"。
下面是 SQL 查询语句:
{sql_query}
以下是查询结果(JSON 格式):
{json.dumps(query_result, ensure_ascii=False, indent=2)}
请你基于以上结果,用简洁中文自然语言回答用户的问题,尽量言简意赅:"""
explain_chain = LLMChain(
llm=llm,
prompt=PromptTemplate(input_variables=["input"], template="{input}")
)
answer = explain_chain.run(explain_prompt).strip()
return {
"sql": sql_query,
"raw_data": query_result,
"answer": answer
}
3、示例效果
用户输入:
哪个部门的平均工资最高?
生成 SQL:
SELECT department, AVG(salary) as avg_salary FROM employees GROUP BY department ORDER BY avg_salary DESC LIMIT 1;
查询结果:
[
{ "department": "技术部", "avg_salary": 15600 }
]
GPT 生成自然语言回答:
技术部是所有部门中平均工资最高的,平均工资为 15,600 元。
4、前端展示建议(Streamlit 或 FastAPI + Vue)
返回数据结构:
{
"sql": "SELECT ...",
"raw_data": [ { ... } ],
"answer": "技术部是所有部门中平均工资最高的..."
}
可以:
-
展示自然语言答案(
answer) -
提供“显示 SQL / 原始数据”按钮以供展开查看
七、自动图表生成
✅ 自动图表生成(柱状图 / 折线图 / 饼图等),配合 GPT 回答,让智能体更直观地展示查询结果!
1、功能目标
-
✅ 执行 SQL 查询后,自动检测数据结构
-
✅ 自动判断是否适合生成图表(如含有分类 + 数值)
-
✅ 自动选择图表类型(柱状图/饼图/折线图)
-
✅ 返回可用于前端渲染的图表数据结构(或直接渲染)
2、Step 1:添加图表分析函数(chart_generator.py)
添加一个 chart_generator.py:
# chart_generator.py
def auto_chart_type(rows):
if not rows or not isinstance(rows, list) or not isinstance(rows[0], dict):
return None
keys = list(rows[0].keys())
if len(keys) == 2:
x_key, y_key = keys
y_vals = [row[y_key] for row in rows if isinstance(row[y_key], (int, float))]
if y_vals:
return {
"type": "bar",
"x": x_key,
"y": y_key,
"data": rows
}
return None # 暂不支持更复杂结构
3、Step 2:在 agent.py 中集成图表逻辑
在 agent.py 顶部引入:
from chart_generator import auto_chart_type
修改返回结构:
chart_info = auto_chart_type(query_result)
return {
"sql": sql_query,
"raw_data": query_result,
"answer": answer,
"chart": chart_info
}
4、Step 3:前端展示建议(Streamlit 版本)
如果用的是 Streamlit,图表可以直接这样显示:
import streamlit as st
import pandas as pd
import altair as alt
res = ask_agent(user_input)
st.write("### 💬 回答")
st.success(res["answer"])
with st.expander("🔍 查看 SQL / 原始结果"):
st.code(res["sql"])
st.write(res["raw_data"])
# 自动图表
if res["chart"]:
chart_type = res["chart"]["type"]
df = pd.DataFrame(res["chart"]["data"])
x, y = res["chart"]["x"], res["chart"]["y"]
st.write("### 📊 自动生成图表")
if chart_type == "bar":
c = alt.Chart(df).mark_bar().encode(x=x, y=y)
st.altair_chart(c, use_container_width=True)
5、最终返回结构示例
{
"sql": "SELECT department, COUNT(*) as total FROM employees GROUP BY department",
"raw_data": [
{"department": "技术部", "total": 10},
{"department": "财务部", "total": 3}
],
"answer": "技术部有 10 名员工,是人数最多的部门。",
"chart": {
"type": "bar",
"x": "department",
"y": "total",
"data": [
{"department": "技术部", "total": 10},
{"department": "财务部", "total": 3}
]
}
}
6、支持图表类型(当前)
| 类型 | 适用条件 |
|---|---|
| Bar Chart | 1 个分类字段 + 1 个数值字段 |
| Pie Chart | 可拓展:用 GPT 判断是否使用饼图 |
| Line Chart | 可拓展:有时间字段时优先折线图 |
八、让 GPT 自动说出“图表说明”
✅ GPT 自动生成图表说明文字,让用户不仅看到图,还能快速理解图传达的含义!
1、效果目标
生成一段图表说明,比如:
上图展示了各部门的员工人数分布。可以看出技术部人数最多,其次是财务部和人事部。
2、Step 1:添加说明生成函数(chart_description.py)
新建一个 chart_description.py:
# chart_description.py
import json
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
llm = ChatOpenAI(temperature=0.4, model="gpt-4")
def generate_chart_description(user_question, sql_query, chart_info):
if not chart_info:
return None
chart_data = json.dumps(chart_info["data"], ensure_ascii=False, indent=2)
x, y = chart_info["x"], chart_info["y"]
prompt = f"""你是一个数据可视化专家。
用户提问是:“{user_question}”
你根据以下 SQL 查询结果生成了一张图表:
- 图表类型:{chart_info["type"]}
- 横轴(x):{x}
- 纵轴(y):{y}
- 数据如下(JSON):
{chart_data}
请用简洁中文为这张图表撰写一段**自然语言说明**,帮助用户理解图中内容。说明应包括趋势、对比、主要发现等,不要解释 SQL。
"""
chain = LLMChain(
llm=llm,
prompt=PromptTemplate(input_variables=["input"], template="{input}")
)
return chain.run(prompt).strip()
3、Step 2:在 agent.py 中调用说明生成器
在 agent.py 中顶部添加:
from chart_description import generate_chart_description
在 ask_agent() 的末尾添加:
chart_info = auto_chart_type(query_result)
chart_description = generate_chart_description(user_question, sql_query, chart_info)
return {
"sql": sql_query,
"raw_data": query_result,
"answer": answer,
"chart": chart_info,
"chart_desc": chart_description
}
4、Step 3:前端展示说明(以 Streamlit 为例)
if res["chart"]:
df = pd.DataFrame(res["chart"]["data"])
x, y = res["chart"]["x"], res["chart"]["y"]
st.write("### 📊 自动生成图表")
chart = alt.Chart(df).mark_bar().encode(x=x, y=y)
st.altair_chart(chart, use_container_width=True)
if res.get("chart_desc"):
st.markdown(f"📝 **图表说明:** {res['chart_desc']}")
5、示例效果
用户输入:
各部门的员工人数如何分布?
自动生成图表说明:
上图显示了各部门的员工人数分布情况。技术部拥有最多的员工,其次是财务部与人事部,说明公司以技术人员为主导。
九、 Chart Agent
1、Chart Agent 功能总览
| 模块 | 说明 |
|---|---|
| ✅ 自动选择图表类型 | 让 GPT 根据查询结果推荐柱状图、折线图、饼图、表格或无图 |
| ✅ 自动生成图表标题 | 自动起个有语义的图标题,例如“各部门员工人数分布” |
| ✅ 图表说明文字 | 自动生成图表说明:趋势、对比、重点信息 |
| ✅ 图表数据结构 | 输出结构统一:type / x / y / data,方便前端渲染 |
2、一体化模块:chart_agent.py
# chart_agent.py
import json
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
llm = ChatOpenAI(temperature=0.3, model="gpt-4")
def call_gpt(prompt: str):
chain = LLMChain(
llm=llm,
prompt=PromptTemplate(input_variables=["input"], template="{input}")
)
return chain.run(prompt).strip()
def chart_agent(user_question: str, sql_query: str, query_result: list):
if not query_result or not isinstance(query_result, list) or not isinstance(query_result[0], dict):
return None
preview = json.dumps(query_result, ensure_ascii=False, indent=2)
columns = list(query_result[0].keys())
base_prompt = f"""
你是一个图表智能助手,专门将 SQL 查询结果转化为可视化图表。
### 用户问题:
{user_question}
### SQL 查询:
{sql_query}
### 查询结果:
{preview}
请判断是否可以生成图表。如果可以,请按以下格式回答(JSON):
```json
{{
"title": "图表标题",
"type": "bar|line|pie|table|none",
"x": "横轴字段名",
"y": "纵轴字段名",
"desc": "对图表的自然语言说明",
"data": [ ... 与上方结果一致 ... ]
}}
如果不适合生成图表,请将 "type" 设置为 "none",其余字段可为空。 """
gpt_response = call_gpt(base_prompt)
try:
# 提取 JSON 块(可选加 parser 强化)
json_start = gpt_response.find("{")
json_text = gpt_response[json_start:]
chart_obj = json.loads(json_text)
return chart_obj
except Exception as e:
print(f"❌ GPT 图表生成失败: {e}")
return None
yaml
---
## 🧪 示例输出
```json
{
"title": "各部门员工人数分布",
"type": "bar",
"x": "department",
"y": "total",
"desc": "图表显示了各部门的员工人数,技术部最多,其次是财务部和人事部。",
"data": [
{ "department": "技术部", "total": 12 },
{ "department": "财务部", "total": 4 },
{ "department": "人事部", "total": 3 }
]
}
3、在 agent.py 中使用 Chart Agent
可以替代原来的图表部分:
from chart_agent import chart_agent
chart_info = chart_agent(user_question, sql_query, query_result)
return {
"sql": sql_query,
"raw_data": query_result,
"answer": answer,
"chart": chart_info
}
4、前端渲染建议(Streamlit)
if res["chart"] and res["chart"]["type"] != "none":
df = pd.DataFrame(res["chart"]["data"])
x, y = res["chart"]["x"], res["chart"]["y"]
st.write(f"### 📊 {res['chart']['title']}")
chart_type = res["chart"]["type"]
if chart_type == "bar":
st.altair_chart(alt.Chart(df).mark_bar().encode(x=x, y=y), use_container_width=True)
elif chart_type == "line":
st.altair_chart(alt.Chart(df).mark_line().encode(x=x, y=y), use_container_width=True)
elif chart_type == "pie":
st.write("🎨 你可以用 plotly 或 matplotlib 展示饼图")
st.markdown(f"📝 **图表说明:** {res['chart']['desc']}")
十、 FastAPI + Docker 服务
✅ FastAPI + Docker 服务:
接收用户问题 + SQL结果,返回图表类型、标题、数据、自然语言说明等结构化响应。
1、项目结构一览
chart-agent/
├── app/
│ ├── main.py # FastAPI 主程序
│ ├── chart_agent.py # GPT 图表生成核心逻辑
│ └── models.py # 请求 & 响应数据结构
├── requirements.txt
├── Dockerfile
└── README.md
2、chart_agent.py(核心逻辑)
# app/chart_agent.py
import json
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
llm = ChatOpenAI(temperature=0.3, model="gpt-4")
def call_gpt(prompt: str):
chain = LLMChain(
llm=llm,
prompt=PromptTemplate(input_variables=["input"], template="{input}")
)
return chain.run(prompt).strip()
def chart_agent(user_question: str, sql_query: str, query_result: list):
preview = json.dumps(query_result, ensure_ascii=False, indent=2)
base_prompt = f"""
你是一个图表智能助手,负责将 SQL 查询结果可视化。
用户问题是:
{user_question}
SQL 是:
{sql_query}
SQL 查询结果如下:
{preview}
请输出以下结构的 JSON:
```json
{{
"title": "图表标题",
"type": "bar|line|pie|table|none",
"x": "横轴字段",
"y": "纵轴字段",
"desc": "图表说明",
"data": [ ... ]
}}
""" gpt_response = call_gpt(base_prompt)
try:
json_start = gpt_response.find("{")
json_text = gpt_response[json_start:]
return json.loads(json_text)
except Exception as e:
return {"type": "none", "title": "", "desc": f"GPT 解析失败:{str(e)}", "data": []}
yaml
---
## 2️⃣ models.py(数据结构)
```python
# app/models.py
from pydantic import BaseModel
from typing import List, Dict
class ChartRequest(BaseModel):
user_question: str
sql_query: str
query_result: List[Dict]
class ChartResponse(BaseModel):
type: str
title: str
x: str
y: str
desc: str
data: List[Dict]
3、main.py(FastAPI 主入口)
# app/main.py
from fastapi import FastAPI
from app.models import ChartRequest, ChartResponse
from app.chart_agent import chart_agent
app = FastAPI()
@app.post("/generate_chart", response_model=ChartResponse)
def generate_chart(req: ChartRequest):
result = chart_agent(req.user_question, req.sql_query, req.query_result)
return result
4、requirements.txt
fastapi
uvicorn
langchain
openai
也可以加上:
pydantic
python-dotenv
5、Dockerfile
FROM python:3.10-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY app/ ./app/
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000"]
6、运行说明 README.md
# 📊 Chart Agent API
一个将 SQL 查询结果转为可视化图表的 GPT 接口服务。
## ✅ 功能
- 自动判断图表类型(柱状图/折线图/饼图/表格)
- 自动生成图表标题、说明
- 支持 FastAPI 调用
- 可部署为 Docker 微服务
## 🚀 本地运行
```bash
uvicorn app.main:app --reload
7、Docker 运行
docker build -t chart-agent .
docker run -p 8000:8000 chart-agent
8、API 示例
POST /generate_chart
{
"user_question": "各部门员工人数?",
"sql_query": "SELECT department, COUNT(*) as total FROM employees GROUP BY department",
"query_result": [
{"department": "技术部", "total": 12},
{"department": "财务部", "total": 4}
]
}
返回:
{
"type": "bar",
"title": "各部门员工人数分布",
"x": "department",
"y": "total",
"desc": "技术部员工最多,其次是财务部。",
"data": [...]
}
yaml
---
## ✅ 后续建议
| 方向 | 描述 |
|------|------|
| ➕ 接入前端 | Streamlit / React / Dash |
| ➕ 日志记录 | log 查询历史、生成情况 |
| ➕ 缓存机制 | 相同问题避免重复请求 GPT |
| ➕ 权限控制 | 接口加 Token 验证 |
---



















 2442
2442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











