








算法:
一个reverse函数就能直接解决。但是如果一个库函数能直接解决的问题,千万不要用这个方法!
这里推荐双指针法
可以发现,双指针法一般都是一个指针在首,另一个指针在尾,两个指针不断靠近,读取数据。这里也是,两个指针交换数值,不断靠近、读数、交换数值。
调试过程:
双指针法
class Solution:
def reverseString(self, s: List[str]) -> None:
"""
Do not return anything, modify s in-place instead.
"""
#初始化双指针
left = 0
right = len(s)-1
for i in range(len(s)):
s[left], s[right] = s[right], s[left]
left += 1
right -= 1

原因:在循环中,我每次都交换了左指针和右指针所指向的元素,这样会导致字符串中的所有字符都被交换了两次,最终还是原来的顺序。
因为i在for循环里面根本没用到。。。。。
改用while循环:
class Solution:
def reverseString(self, s: List[str]) -> None:
"""
Do not return anything, modify s in-place instead.
"""
#初始化双指针
left = 0
right = len(s)-1
while left < right:
s[left], s[right] = s[right], s[left]
left += 1
right -= 1

使用range的双指针法,那就要用i表示left和right:
比如一个字符串长度为4:
第一次遍历,left=0 right=3
第二次遍历,left=1 right=2
left 用i表示,字符串长度为n
则left+right=n-1,所以right = n-1-left=n-1-i
调试过程:
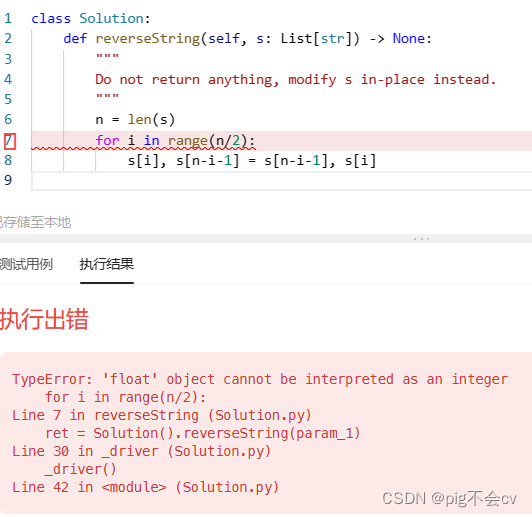
原因:
在Python中,`/` 是除法运算符,它返回一个浮点数结果,而 `//` 是整数除法运算符,它返回一个整数结果。
在你提供的代码中,`n/2` 使用的是除法运算符,这意味着 `n` 除以 2 的结果将是一个浮点数。然而,`range()` 函数要求传入整数作为参数,因此将浮点数作为参数会导致错误。
修改后:
class Solution:
def reverseString(self, s: List[str]) -> None:
"""
Do not return anything, modify s in-place instead.
"""
n = len(s)
for i in range(n//2):
s[i], s[n-i-1] = s[n-i-1], s[i]

内存比while循环少了一点哎,时间一样的
切片法:
class Solution:
def reverseString(self, s: List[str]) -> None:
s[:] = s[::-1]
"""
Do not return anything, modify s in-place instead.
"""

时间变少了,但内存增加
切片法复习:
在Python中,冒号(`:`)用于表示切片操作。切片操作用于从序列(如字符串、列表、元组等)中获取子序列。
切片操作的一般语法形式是:`[start:stop:step]`,其中:
- `
start`:表示切片的起始位置(包含在切片内)。 - `
stop`:表示切片的结束位置(不包含在切片内)。 - `
step`:表示切片的步长(默认为1)。
一些常见的切片操作示例:
s = "Hello, World!"
# 获取从索引2到索引5之间的子字符串(不包含索引5)
substring = s[2:5] # 输出: "llo"
# 获取从索引3到末尾的子字符串
substring = s[3:] # 输出: "lo, World!"
# 获取从开头到索引7之间的子字符串(不包含索引7)
substring = s[:7] # 输出: "Hello, "
# 获取完整的字符串的副本
substring = s[:] # 输出: "Hello, World!"
# 从索引0开始,每隔2个字符获取子字符串
substring = s[::2] # 输出: "Hlo ol!"
# 从索引末尾开始,每隔3个字符获取子字符串
substring = s[::-3] # 输出: "!WlH" 以上方法的时间、空间复杂度:
- 时间复杂度: O(n)
- 空间复杂度: O(1)















 587
587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









