






在此博客文章中,我将讨论个性化页面排名(personalized pagerank),其定义和应用。 让我们从一些基本术语和定义开始。
定义
1. 随机游走
给定一个图,随机游走是一个从随机顶点开始的迭代过程,并且在每个步骤中,要么跟随当前顶点的随机输出边缘,要么跳到随机顶点。 跳跃部分很重要,因为某些顶点可能没有任何向外的边缘,因此遍历将在那些位置终止而不会跳转到另一个顶点。
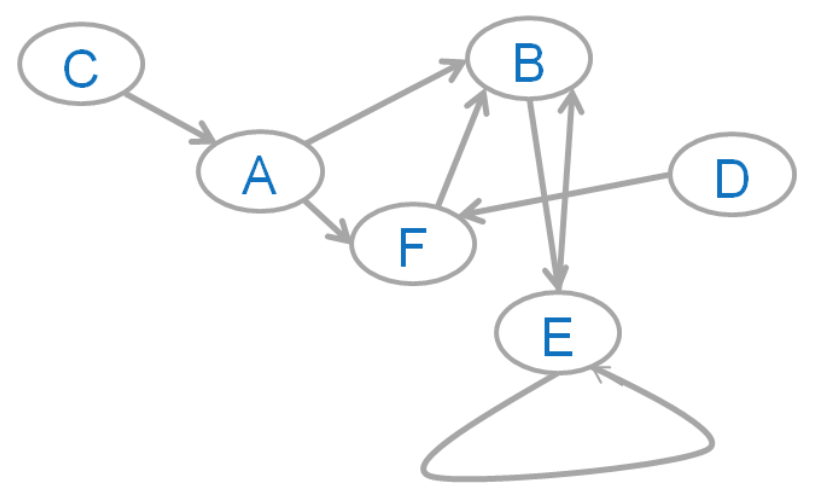
在下图中,示例随机游走可以从A开始,沿着A到B的输出边缘,沿着B到E的输出边缘,沿着E的一条向外的边缘到达B,跳到D,然后沿着A的向外边缘 D到F,然后跳到C。
2. PageRank (PR)
PageRank (PR) 衡量一种特定类型的随机游走的平稳分布,该随机游走从随机顶点开始,并且在每次迭代中均以预定义的概率 p p p 跳至随机顶点,并且概率 1 − p 1-p 1−p 跟随当前顶点的随机输出边缘。
PageRank通常是在具有均质边的图上进行的,例如,具有“A linksTo B”、“A reference B”、“A likes B”、“A endors B”,或者 “A readsBlogsWrittenBy B”、“A hasImpactOn B”等形式的边的图。
在图上运行PageRank算法将生成顶点的排名(PR值),并且数字PR值可以视为顶点的“重要性”或“相关性”。 通常将具有高PR值的顶点比具有低PR值的顶点更“重要”或更“有影响力”或具有更高的“相关性”。
3. 个性化PageRank (PPR)
个性化PageRank (PPR) 与PR相同,不同之处在于跳转会返回到给定的一组起始顶点之一。 在某种程度上,与PR中执行的随机遍历相比,PPR中的遍历偏向于这组起始顶点(或者说更个性化),并且更加局限。
推荐系统中的PPR
现在,我们已经了解了随机游走、PR和PPR的术语。 让我们看一下如何将PPR用作推荐。 假设我们有以下客户购买产品图(带有反向边)。 假设我们要从用户John开始PPR。 从直觉上讲,PPR中的随机游走很可能会接触到John购买的产品以及购买这些产品的其他用户,以及这些用户购买的产品,依此类推。 从某种意义上讲,这种游走方式能够吸引与John相似的用户,因为他们购买了相同(或相似或相关)的产品。 此外,PPR中的漫游会发现相似/相关产品,因为它们是由相同(或相似或相关)用户购买的。

使用Oracle大数据空间和图属性图的推荐工作流程
以下Java代码段可以在Oracle Big Data Spatial和Graph支持的Groovy环境中执行。
// First, execute gremlin-opg-hbase.sh or gremlin-opg-nosql.sh
// ...
// Get an instance of OraclePropertyGraph which is a key Java
// class to manage property graph data
opg = OraclePropertyGraph.getInstance(cfg);
opg.clearRepository(); // remove all vertices and edges
// Add vertices for the users and products
vJohn=opg.addVertex(1l); vJohn.setProperty("name","John");
vJohn.setProperty("age",10i);
vMary=opg.addVertex(2l); vMary.setProperty("name","Mary");
vMary.setProperty("sex","F");
vJill=opg.addVertex(3l); vJill.setProperty("name","Jill");
vJill.setProperty("city","Boston");
vTodd=opg.addVertex(4l); vTodd.setProperty("name","Todd");
vTodd.setProperty("student",true);
sdf = new java.text.SimpleDateFormat("mm/dd/yyyy");
vPhone=opg.addVertex(10l); vPhone.setProperty("type","Prod");
vPhone.setProperty("desc","iPhone5");
vPhone.setProperty("released",sdf.parse("02/21/2012"));
vKindle=opg.addVertex(11l);
vKindle.setProperty("type","Prod");
vKindle.setProperty("desc","Kindle Fire");
vFitbit=opg.addVertex(12l);
vFitbit.setProperty("type","Prod");
vFitbit.setProperty("desc","Fitbit Flex Wireless");
vFitbit.setProperty("rating","****");
vPotter=opg.addVertex(13l);
vPotter.setProperty("type","Prod");
vPotter.setProperty("desc","Harry Potter");
vHobbit=opg.addVertex(14l);
vHobbit.setProperty("type","Prod");
vHobbit.setProperty("desc","Hobbit");
// List the vertices
opg.getVertices()
==>Vertex ID 14 {type:str:Prod, desc:str:Hobbit}
==>Vertex ID 2 {name:str:Mary, sex:str:F}
==>Vertex ID 4 {name:str:Todd, student:bol:true}
==>Vertex ID 11 {type:str:Prod, desc:str:Kindle Fire}
==>Vertex ID 10 {type:str:Prod, desc:str:iPhone5,
released:dat:Sat Jan 21 00:02:00 EST 2012}
==>Vertex ID 12 {type:str:Prod, desc:str:Fitbit Flex
Wireless, rating:str:****}
==>Vertex ID 13 {type:str:Prod, desc:str:Harry Potter}
==>Vertex ID 1 {name:str:John, age:int:10}
==>Vertex ID 3 {name:str:Jill, city:str:Boston}
// Add edges with Blueprints Java APIs. Note that if the number of
// edges is much bigger, then use the parallel data loader & flat file format.
opg.addEdge(1l, vJohn, vPhone, "purchased");
opg.addEdge(2l, vPhone, vJohn, "purchased by");
opg.addEdge(3l, vJohn, vKindle, "purchased");
opg.addEdge(4l, vKindle, vJohn, "purchased by");
opg.addEdge(5l, vMary, vPhone, "purchased");
opg.addEdge(6l, vPhone, vMary, "purchased by");
opg.addEdge(7l, vMary, vKindle, "purchased");
opg.addEdge(8l, vKindle, vMary, "purchased by");
opg.addEdge(9l, vMary, vFitbit, "purchased");
opg.addEdge(10l, vFitbit, vMary, "purchased by");
opg.addEdge(11l, vJill, vPhone, "purchased");
opg.addEdge(12l, vPhone, vJill, "purchased by");
opg.addEdge(13l, vJill, vKindle, "purchased");
opg.addEdge(14l, vKindle, vJill, "purchased by");
opg.addEdge(15l, vJill, vFitbit, "purchased");
opg.addEdge(16l, vFitbit, vJill, "purchased by");
opg.addEdge(17l, vTodd, vFitbit, "purchased");
opg.addEdge(18l, vFitbit, vTodd, "purchased by");
opg.addEdge(19l, vTodd, vPotter, "purchased");
opg.addEdge(20l, vPotter, vTodd, "purchased by");
opg.addEdge(21l, vTodd, vHobbit, "purchased");
opg.addEdge(22l, vHobbit, vTodd, "purchased by");
opg.commit();
// Create in-memory analytics session and analyst
session=Pgx.createSession("session_ID_1");
analyst=session.createAnalyst();
// Read the graph from database into memory
pgxGraph = session.readGraphWithProperties(opg.getConfig());
// We are going to get a recommendation for user John.
// Find this vertex with a simple query
v=opg.getVertices("name", "John").iterator().next();
// Add John to the start vertex set
vertexSet=pgxGraph.createVertexSet();
vertexSet.addAll(v.getId());
// Run personalized page rank using John as the start vertex
ppr=analyst.personalizedPagerank(pgxGraph, vertexSet, \
0.0001 /*maxError*/, 0.85 /*dampingFactor*/, 1000);
// Examine the top 9 entries of the PPR output
// The vertices for John, iPhone5, and Kindle Fire have the highest PR
// values (shown below in the first column) because John is the starting point of PPR
// and iPhone5 and Kindle Fire were purchased by John.
// Mary and Jill also have high PR values because they made similar purchases as John.
//
it=ppr.getTopKValues(9).iterator(); while
(it.hasNext()) {
entry=it.next(); vid=entry.getKey().getId();
System.out.format("ppr=%.4f vertex=%s\n",
entry.getValue(), opg.getVertex(vid));}
==>
ppr=0.2496 vertex=Vertex ID 1 {name:str:John, age:int:10}
ppr=0.1758 vertex=Vertex ID 11 {type:str:Prod,
desc:str:Kindle Fire}
ppr=0.1758 vertex=Vertex ID 10 {type:str:Prod,
desc:str:iPhone5, released:dat:Sat Jan 21 00:02:00 EST 2012}
ppr=0.1229 vertex=Vertex ID 3 {name:str:Jill,
city:str:Boston}
ppr=0.1229 vertex=Vertex ID 2 {name:str:Mary, sex:str:F}
ppr=0.0824 vertex=Vertex ID 12 {type:str:Prod,
desc:str:Fitbit Flex Wireless, rating:str:****}
ppr=0.0451 vertex=Vertex ID 4 {name:str:Todd,
student:bol:true}
ppr=0.0128 vertex=Vertex ID 13 {type:str:Prod, desc:str:Harry
Potter}
ppr=0.0128 vertex=Vertex ID 14 {type:str:Prod,
desc:str:Hobbit}
// Now, let's filter out users from this list
// (assume we only want to recommend products for John,
// not other similar buyers)
// If we exclude the top 2 products that John purchased
// before, the remaining three, Fitbit, Harry Potter,
// and Hobbit, are our recommendations for John, in that order.
// Note that for John, Fitbit has a much higher PR value
// than Harry Potter and Hobbit.
//
it=ppr.getTopKValues(9).iterator(); while (it.hasNext()) {
entry=it.next(); vid=entry.getKey().getId();
vertex=opg.getVertex(vid);
if ("Prod".equals(vertex.getProperty("type")))
System.out.format("ppr=%.4f vertex=%s\n",
entry.getValue(), opg.getVertex(vid));}
=>
ppr=0.1758 vertex=Vertex ID 11 {type:str:Prod,
desc:str:Kindle Fire}
ppr=0.1758 vertex=Vertex ID 10 {type:str:Prod,
desc:str:iPhone5, released:dat:Sat Jan 21 00:02:00 EST 2012}
ppr=0.0824 vertex=Vertex ID 12 {type:str:Prod,
desc:str:Fitbit Flex Wireless, rating:str:****}
ppr=0.0128 vertex=Vertex ID 13 {type:str:Prod, desc:str:Harry
Potter}
ppr=0.0128 vertex=Vertex ID 14 {type:str:Prod,
desc:str:Hobbit}
// So the final recommended products for John are,
Fitbit, Harry Potter, and Hobbit
ppr=0.0824 vertex=Vertex ID 12 {type:str:Prod,
desc:str:Fitbit Flex Wireless, rating:str:****}
ppr=0.0128 vertex=Vertex ID 13 {type:str:Prod, desc:str:Harry
Potter}
ppr=0.0128 vertex=Vertex ID 14 {type:str:Prod,
desc:str:Hobbit}















 18
18











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









