






AFLnet源码分析
afl-fuzz.c分析
函数分析
找到main函数,开始逐步分析:
通过while输入参数,一直到9128行为止都是对参数的操作。

然后是参数错误处理,主要就是提醒参数的标准格式:
save_cmdline的作用是把参数全部转移到堆上存储。
fix_up_banner的作用跟UI有关,跟功能关系不大。
check_if_tty的作用是检查程序是否在tty终端运行。
get_core_count的作用是获取核心数。
这些函数都不是很重要,重点函数从9196行开始:
init_count_class16
定义了两个结构:lookup8和lookup16:

这两个结构的定义是这样的,需要注意的是,lookup8是8字节大小,lookup16是16字节大小,字节大小的不同决定了他们的作用不同:

其中lookup8是用来记录到达路径的,这样定义的原因是因为对于一些路径,比如循环,对于同一个循环,因为条件的不同,一次可能循环3次就跳出,一次可能循环6次跳出,但是不管循环多少次,其实都是同一条路径。
但是AFL不能做出上面的判断,因为命中次数不一样,AFL就会把同一个循环当作两条路径。为了减少这种因为命中次数不同而导致的误判,所以设计者用了上面的数组定义方式,规定命中次数4-7次都认为是命中8次,8-15次都认为是命中32次…128-255次都认为是命中128次。
这样一来,就能减少(注意是减少不是消除)循环次数不同带来的路径误判。

前面说了,lookup8是8字节大小,lookup16是16字节大小,那么一个lookup16单元就可以存放两个lookup8单元,这里可以把lookup8看作一个数组,那么lookup16就可以看作一个二维数组。lookup16的作用是用来表示路径路由的,比如A->B->C->D这条路径,在lookup16里存放的方式为:
[A,B] [B,C] [C,D]
setup_ipsm是设置进程间同步管理器。
set_dirs_fds该函数的作用是对输入输出目录进行处理。
read_testcases
首先检测in_dir目录下有没有queue这个文件夹,如果有,则设置in_dir为in_dir/queue.

然后用scandir()和alphasort()函数对in_dir文件夹进行扫描,如果in_dir文件夹中没有任何文件,则nl_cnt为-1,然后报错如下:

如果in_dir里有文件,则将扫描出来的文件数赋值给nl_cnt,然后将扫描结果存储再nl中。

如果设置了shuffle_queue为1,且nl_cnt>1,则用shuffle_ptrs函数对nl中的数组进行重新排序。
然后是对nl里的所有testcase进行遍历,需要注意的是nl是一个dirent的结构体数组,结构为:
struct dirent
{
long d_ino; /* inode number 索引节点号 */
off_t d_off; /* offset to this dirent 在目录文件中的偏移 */
unsigned short d_reclen; /* length of this d_name 文件名长 */
unsigned char d_type; /* the type of d_name 文件类型 */
char d_name [NAME_MAX+1]; /* file name (null-terminated) 文件名,最长255字符 */
}
所以下面这段代码就是将in_dir/d_name赋值给fn,将in_dir/.state/deterministic_done/d_name赋值给dfn,然后为了节省空间,free掉nl[i].

lstat函数用于获取文件信息,提取fn路径的文件,然后将获取的文件信息赋值给st,如果没有检测到路径为fn的文件,则报错;
access函数用来判断指定的文件或目录是否存在(F_OK),已存在的文件或目录是否有可读(R_OK)、可写(W_OK)、可执行(X_OK)权限,这里是检查fn路径的文件是否是可读的,如果不是,则报错。

通过strstr函数,对文件名进行过滤,主要是为了过滤掉一些README之类的无用文件,之后就不用对这些文件进行处理了。(这里可以自己进行改进,筛选掉自己的testcases中不需要的文件)

这里对每一个testcase进行了文件大小的限制,MAX_FILE为1024*1024,也就是1M,此处可以自己根据自己的测试文件大小更改:


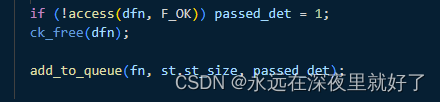
这里对dfn路径文件是否可读进行了判断,如果可读则设置passed_det为1.

为什么要这么设置呢,他的注释说了:
这是为了在resum 扫描的时候使用,如果这个entry已经结束了deterministic fuzzing,在恢复异常终止的扫描时,我们不想重复deterministic fuzzing,因为这将毫无意义,而且可能非常耗时。
为了理解这个注释,需要知道fuzz的几个阶段:
在AFL的fuzzing过程中,维护了一个 testcase 队列 queue ,每次把队列里的文件取出来之后,对其进行变异,下面就先粗略讲一下各个阶段的变异是怎样的。
bitflip:按位翻转,每次都是比特位级别的操作,从 1bit 到 32bit ,从文件头到文件尾,会产生一些有意思的额外重要数据信息;
arithmetic:与位翻转不同的是,从 8bit 级别开始,而且每次进行的是加减操作,而不是翻转;
interest:把一些有意思的东西“interesting values”对文件内容进行替换;
dictionary:用户提供的字典里有token,用来替换要进行变异的文件内容,如果用户没提供就使用 bitflip 自动生成的 token;
havoc:进行很大程度的杂乱破坏,规则很多,基本上换完就是面目全非的新文件了;
splice:通过将两个文件按一定规则进行拼接,得到一个效果不同的新文件;
其中bitflip、arithmetic、interest、dictionary 是 deterministic过程(确定性过程),是dumb mode(-d) 和主 fuzzer(-M) 会进行的操作。而havoc、splice是随机过程,是所有fuzz mod都会采取的策略。
为了避免无意义的变异,节约资源,所以deterministic fuzz不会重复执行。在后面的循环中,havoc和splice这类随机过程会反复执行。
所以前面的pass_det设置为1,就是为了后面不重复执行deterministic fuzz这个过程。

然后是add_to_queue函数:
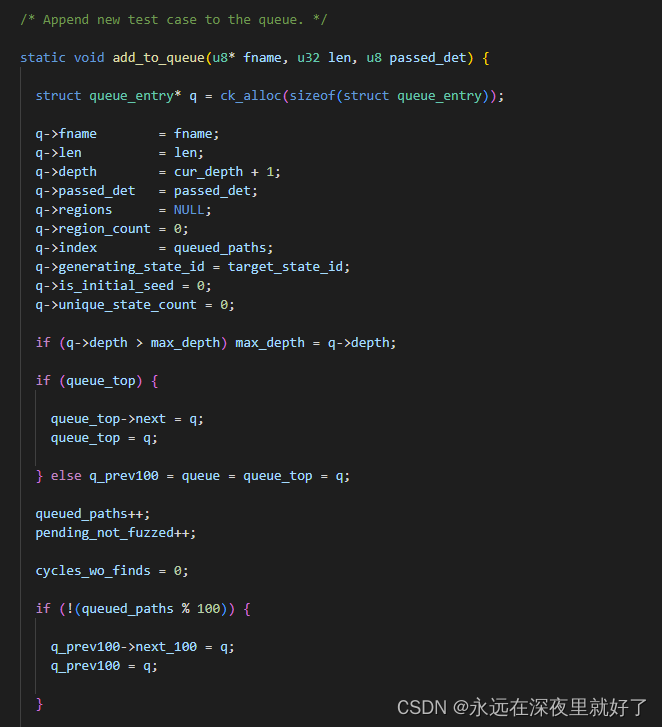
前面说了,afl里面维护了一个testcase的队列queue,add_to_queue函数就是将新的testcase添加到queue中,成为一个queue_entry结构体q:

queue结构体如下:
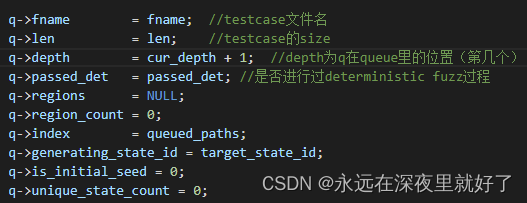
max_depth为queue队列中元素个数,会随着扫描到的testcases的增加而增加:

从这里可以看出来,queue采用的维护方法是头插法:

queue记录的是总的testcase数量,max_depth记录的是每一个队列里的数量,这两个变量有区别。
pending_not_fuzzed记录的是待fuzz的testcase数量。
cycles_wo_finds的注释是Cycles without any new paths,这里尚不知道是个什么意思,后续补充

从下面可以看出,每100个testcase作为一个队列管理。

load_auto
循环遍历,以只读模式打开"%s/.state/auto_extras/auto_%06u", in_dir, i
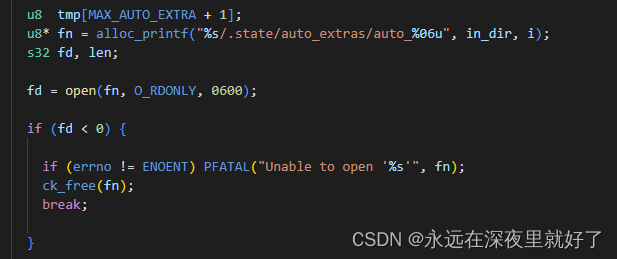
从目标文件中读出MAX_AUTO_EXTRA+1个字节到tmp里面。
如果读不到就报错,读出数据在MIN_AUTO_EXTRA和MAX_AUTO_EXRTA之间,就使用maybe_add_auto函数。
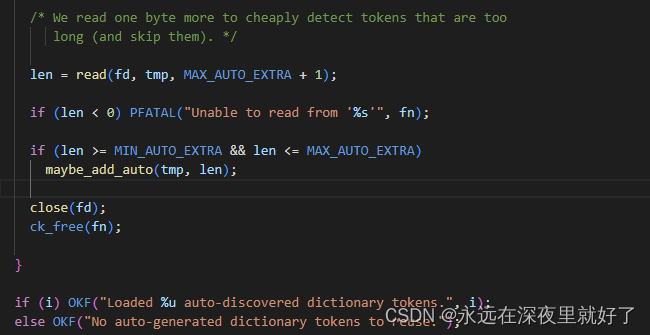
maybe_add_auto 重点函数,用于添加token
这个函数通过MAX_AUTO_EXTRAS和USE_AUTO_EXTRAS两个标志符决定是否采取自动的字典:

下面是通过异或运算,跳过相同mem。(如果两个mem从头到尾都一样,则最终i会等于len,直接return,起到了跳过相同mem的作用):

如果len的长度为2,就和interesting_16数组里的元素比较,如果和其中某一个相同,就直接return。
如果len的长度为4,就和interesting_32数组里的元素比较,如果和其中某一个相同,就直接return。
这一部分相当于是在筛选token,如果某一候选token在interesting数组里已经存在了,那么就淘汰掉这个候选token。
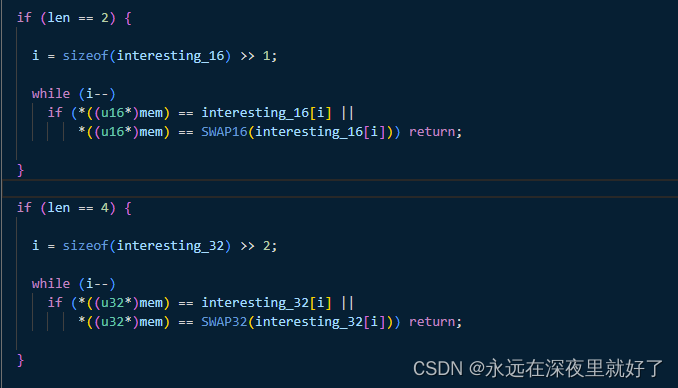
这一部分也是在筛选token,首先利用extras里的元素都是按照size大小排序的这个特性来优化算法,用一个循环找到大小跟候选token一样的tokens,然后用第二个循环比较extras里是否存在跟候选token一样的token,如果有,候选token就被淘汰。

如果通过了上面的筛选,则会设置auto_changed = 1,然后进行跟a_extras的比较(a_extras的含义是Automatically selected extras),如果a_extras[i]跟通过筛选的token一样,则a_extras[i].hint_cnt加一,这代表这个token在语料里出现的次数。然后跳转到sort_a_extras.

sort_a_extras用了两个快排,对a_extras进行排序。第一个是根据使用次数进行降序排序。第二个是对根据size进行排序。
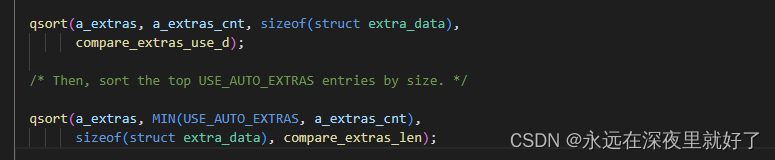
排序完毕之后进行的操作是:
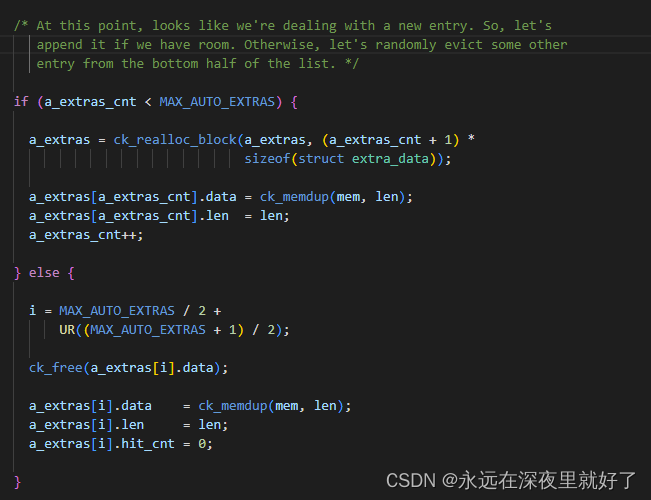
首先判断a_extras_cnt是否小于MAX_AUTO_EXTRAS,如果小于,则表示a_extras数组没有被填满,所以此时直接将候选token加入到a_extra数组里。
如果a_extras_cnt大于MAX_AUTO_EXTRAS,则从a_extras数组的后半部分里面随机选择一个元素,用候选token替换,也就是更改a_extras[i].data,a_extras[i].len。然后将a_extras[i].hit_cnt设置为0.
pivot_inputs
该函数的作用是在output目录里面创建输入的testcase的硬链接。
可以看到,这里通过while循环对testcases进行操作:

通过strrchr得到文件名字,例如/123.pdf,然后通过后面rsl++,将rsl编程123.pdf,起到一个去除/的作用:

这一段有三个条件,必须全部满足。
第一要求rsl的前三个字符必须是id:
第二个条件的作用是将id:后面的内容赋值给orig_id。比如如果rsl是id:123123123123,则orig_id为123123123.
第三个要求是为了比较orig_id和id是否相等,为什么要做这个比较呢。我们看他的注释:
意思就是如果源文件名字和我们记录的id号是一样的,那么就使用原来的文件名就行了。这样做是为了方便恢复模糊测试现场。
/* If the original file name conforms to the syntax and the recorded ID matches the one we'd assign, just use the original file name. This is valuable for resuming fuzzing runs. */
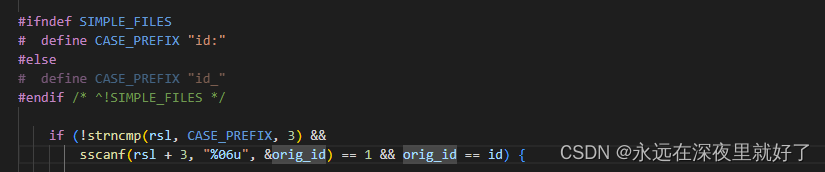
如果满足上述三个条件,则设置resuming_fuzz=1
然后将nfn赋值为outdir/queue/rsl

然后将nfn赋值为,out_dir/queue/id:xxxxxxx,orig:use_name.
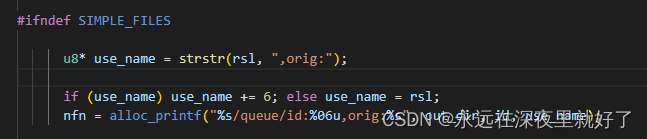
将nfn赋值给q->name.
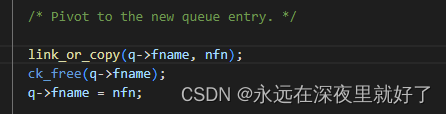
还记得我们前面说的,passed_det这个变量,是为了标识是否经过了deterministic fuzz这个过程,如果该标识符为1,就表示该testcase是经历过确定性变异,然后调用mark_as_det_done函数。
mark_as_det_done函数的主要作用就是将该testcase文件放入deterministic_done文件夹,这样做是为了将经历过deterministic fuzz过程单独放置,节省处理时间。

如果in_place_resume=1,则调用nuke_resume_dir函数,这个函数的作用大致是删除一些用于恢复会话的临时目录。

load_extras(区别于load_auto)
前面我们分析过一个函数,他的名字叫load_auto,主要作用是加载自动生成的extras。load_extras这个函数则是加载自己指定的extras。
如下图,如果你指定了extras_dir,则会从这个目录里加载extras。

使用-x指定extras_dir:

可以看出,load_extras这个函数,支持通过文件名字定义dictionary的level。
比如存放extras的文件夹为QL@0,则此时加载的extra dictionary的级别为0。但是这个level的作用我不是很清楚,希望大佬指点。
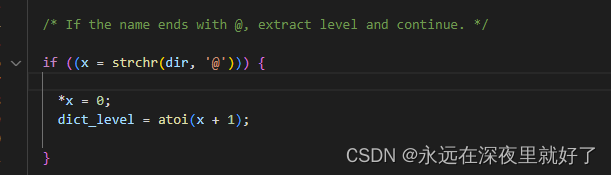
然后使用load_extras_file加载extras,然后按照size对extras进行排序。
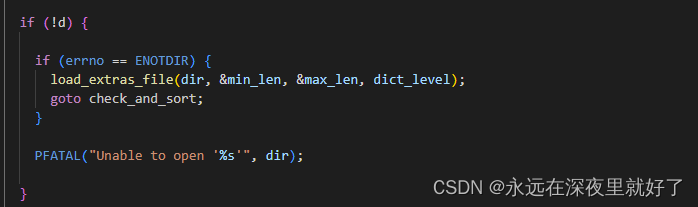
find_timeout
这是个超时处理函数,看这个函数的注释:
The same, but for timeouts. The idea is that when resuming sessions without -t given, we don’t want to keep auto-scaling the timeout over and over again to prevent it from growing due to random flukes.
意思就是,可以通过-t设置超时时间,但是如果在没有设置-t的情况下resuming session,也能够通过这个而函数迅速确定超过时间。
这里不做多分析,因为对于改造fuzz工具不是很重要。
detect_file_args
探测文件名中含有的参数,不是很重要,不做分析。
setup_stdio_file
当用户不指定输出目录的时候,会自动设置输出目录,不过我们一般会自己设置输出目录,所以这个函数也没什么好分析的。

check_binary
该函数的主要作用是检查执行路径里面是否有shell脚本,这样做是为了安全考虑。
第二个作用是检查ELF头以及程序是否被插桩编译。

Dry run
获取fuzz开始时间,检查是不是在qemu模式下:
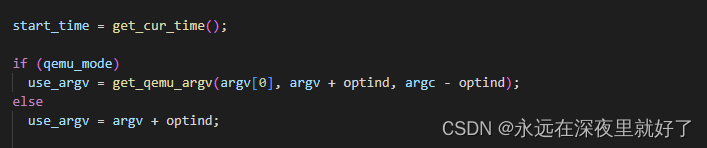
perform_dry_run 重点函数
这个函数是AFLnet的非常关键的函数。
他的作用将input文件夹里的所有testcase作为输入,生成初始化的queue和bitmap。需要注意的是,这个函数只对初始输入执行一次。

通过while循环,遍历队列里面的每一个testcase:
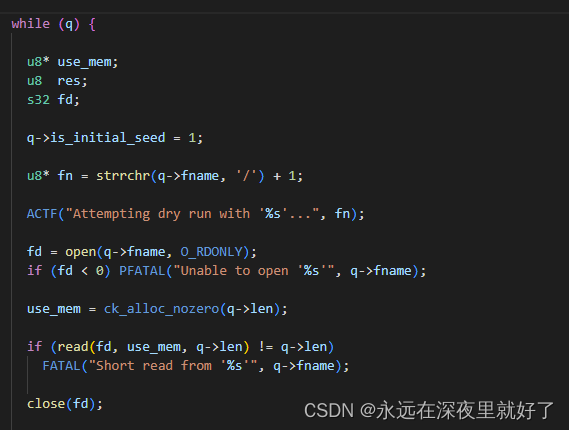
calibrate_case 重点函数
然后调用calibrate_case这个函数。这个函数非常重要,用于校准testcase,是fuzz的主要运行函数。其返回值赋值给res。

首先,如果dumb_mode!=1或者forkserver没有启动,则调用init_forkserver来fork一个进程:
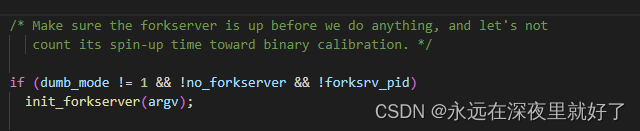
我们对fork的过程进行分析,就当顺便复习一下操作系统了。
这里我们借用一张图来帮助说明:
父进程通过fork创建一个进程之后,父进程和子进程就同时从fork处开始分别往下执行,就像从这里开始世界线分叉了。
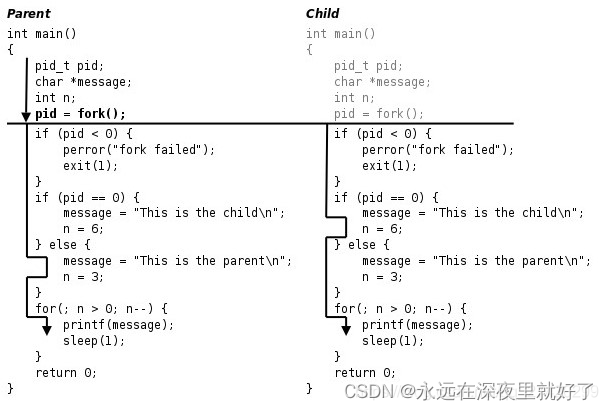
所以我们看init_forkserver这个函数:
父进程在fork出一个子进程之后,子进程满足if(!forksrv_pid),所以子进程进入if语句块。而父进程不满足if(!forksrv_pid),所以父进程会直接跳过这个if语句块。
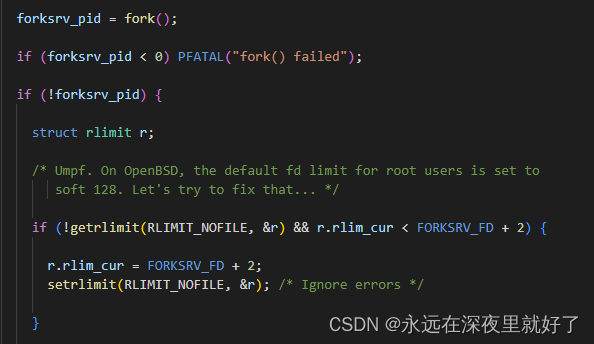 在这里,子进程调用execv函数,执行目标程序。
在这里,子进程调用execv函数,执行目标程序。
调用execv()函数执行某一个程序时,如果运行的程序不结束,execv()是不会return的。所以可以看到,只有在程序结束,子进程才会exit(0),然后通过一个EXEC_FAIL_SIG信号,告诉父进程目标程序执行失败。

父进程则直接跳到了下面的位置,等待子进程创建的server上线:
如果收到了四个字节的"hello"消息,说明server已经上线,则父进程return,结束init_forkserver函数。
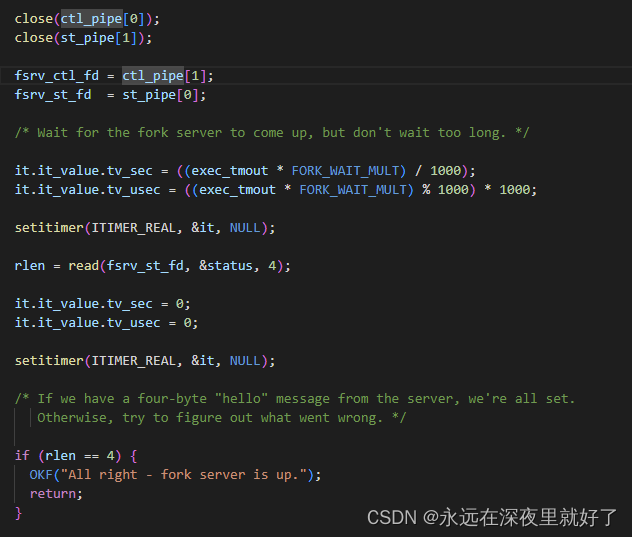
结束init_forkserver函数之后,首先判断这个testcase是不是第一次被运行。如果不是第一次运行这个testcase,则拷贝trace_bits到first_trace里。然后调用get_cur_time_us函数,得到开始时间。

然后进入进入一个循环,如果不是第一次执行这个testcase且stage_cur%stats_update_freq == 0.则会调用show_stats函数,刷新展示界面,可以通过调整stats_update_freq来调整刷新频率。

然后调用wirte_to_testcase函数,这个函数的作用是使用ckwirte的方法,把testcase的内容写入out/.cur_input中。

但是因为AFLnet通过网络传输testcase,所以不需要这个函数。
AFLnet传输testcase的函数叫send_over_network,后面遇到再分析。

run_target
这个函数的主要作用是执行目标应用程序,监控超时,返回状态信息,然后利用调用的程序更新trace_bits[].
之前提到过,init_forserver这个函数已经通过fork子进程,启动了目标程序,但是如果在dumb mode(相当于黑盒)或者no_forkserver下运行的话,在这里就通过run_target函数启动目标程序。
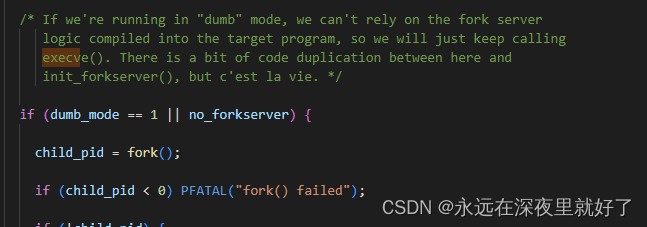
如果不是dumb_mode,或者之前已经fork过一个子进程用来执行目标程序了,那么就会跳过上面的代码段,从下述代码开始执行。
这一部分代码是通过管道来进行父进程和子进程之间的通信。目的是告诉父进程子进程的存在,然后获取子进程进程号。
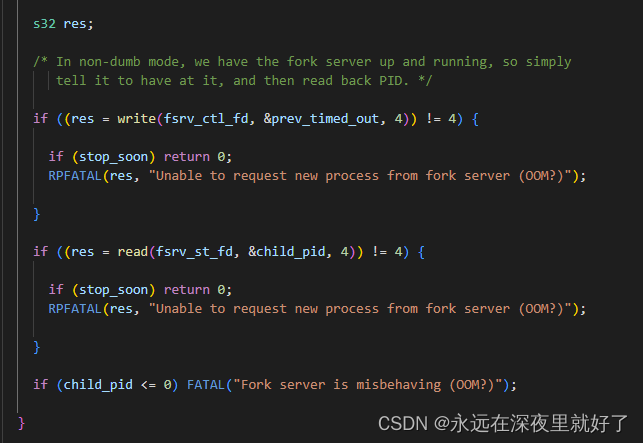
设置超时时间,调用setitimer函数等待子进程终止。

通过send_over_network函数发送数据到目标,来造成目标服务器进入各种状态。后面我们会分析是怎样通过send_over_network函数来传输数据的。
不同的是,由于dumb_mode模式或者no_forkserver无法得知目标服务器的状态,所以这里需要通过一个waitpid函数来获取子进程状态,从而确认目标服务器是否存活。
如果不是dump_mode,则可以直接利用read函数,通过读管道读出目标状态。

通过WIFSTOPPED函数判断子进程是否已经结束。
然后获取当前时间作为运行结束时间,与之前的开始时间做减法,得到运行时长。
然后total_execs自增1。total_execs是这个过程执行的次数。

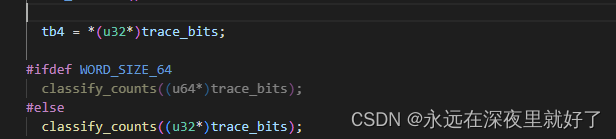
然后用classify_counts函数,对trace_bits共享内存记录的路径执行次数进行分类,是一个对稀疏位图进行优化的操作,具体原理不清楚。
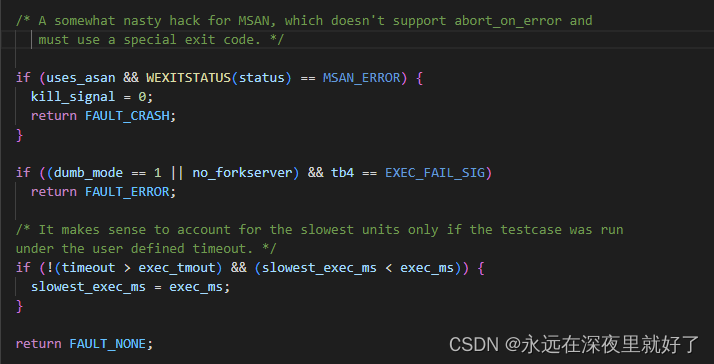
从下面可以看出根据目标服务器的状态,会返回三种类型:FAULT_CRASH,FAULT_ERROR,FAULT_NONE.
其中:
FAULT_CRASH和FAULT_ERROR状态都表示当前运行的testcase造成了目标服务器崩溃。
FAULT_NONE表示当前testcase的运行时间超过了用户定义的超时时间的情况,也就是说这个testcase在我们定义的超时时间内并没有造成目标服务器崩溃。
run_target函数就分析到这,总结一下这个函数就是进行fuzzer与目标服务器之间的通信,通过这个函数将testcase发送到服务器,然后判断服务器状态。
send_over_network
这个函数很长,但是主要目的很清晰,就是传输变异之后的testcase。aflnet与afl的区别也主要在于这个函数。
首先是一些参数的设置,比如目标服务器的IP地址和端口号,超时设置,轮询间隔。

创建并初始化消息存放的缓冲区:

创建TCP/UDP的sockets:

后面就不分析了,很长,我相信研究fuzz的也没几个关心他的通信过程。/狗头
update_bitmap_score
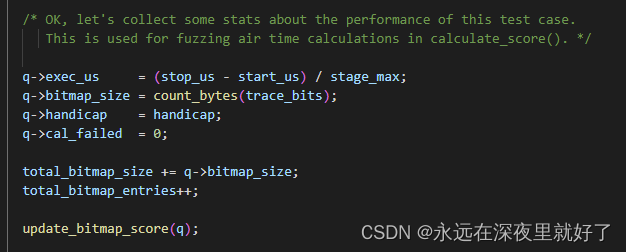
在进入这个函数之前,需要收集testcase的各种状态参数,形成一个结构体。
需要注意的是bitmap_size的计算,是通过count_bytes函数进行计算的。
count_bytes函数是通过计算位图中设置的字节数,主要作用是更新状态或者检查新的路径。

update_bitmap_score函数的注释翻译如下(机翻):
当我们遇到一条新路径时,我们调用它以查看该路径是否比任何现有路径看起来更“有利”。“有利”的目的是拥有一组最小的路径来触发到目前为止在位图中看到的所有位,并专注于模糊它们,而牺牲其余位。
该过程的第一步是为位图中的每个字节维护一个 top_rated[] 条目的列表。如果没有先前的竞争者,或者竞争者具有较小的唯一状态计数,或者它具有更有利的速度 x 大小因子,我们将赢得该插槽。
说人话就是:
update_bitmap_score函数在每一次run_target函数结束之后执行,主要是对于当前的testcases造成的程序执行路径进行评估。
不同的程序执行路径会触发位图中不同的位,我们要用尽可能少的时间和尽可能少的testcase,覆盖尽可能多的位。每一条执行路径的“有利”程度,就是指这个程序执行路径执行时间是否短,是否覆盖到更多的位。

具体实现方式就是:
首先,定义一个fav_factor,它的值等于当前执行testcase队列的执行时间与testcases数目的乘积。

设置一个数组top_rated[i],表示trace_bits中第i个字节的最“有利”路径。
然后循环遍历trace_bits中的每一个字节,如果trace_bits[i]为0,表示这个位置还没有被覆盖到,如果trace_bits[i]为1,则表示该路径已经被覆盖到了,这个时候检查对应位置的top_rated,进行下面的比较:
首先,如果不存在top_rated,说明当前testcase队列就是最优路径,这个时候直接跳过if语句,执行top_rated[i]=q,将最优路径设置为当前路径。
如果存在top_rated:则首先比较当前testcase队列和top_rated的状态数(unique_state_count),如果当前testcase队列造成的独特状态数小于top_rated造成的独特状态数,则跳过该次循环,进行下一次循环。
然后进行fav_factor的比较,如果当前testcase队列的fav_factor小于top_rated,则当前testcase队列获胜。
当前testcase队列获胜之后,会减少top_rated的引用次数(top_rated[i]->tc-ref),如果top_rated的引用次数本来就为0,则删除当前top_rated.

如果当前的test case队列获胜,则将当前testcase队列设为top_rated[i].然后将他的引用次数tc_ref加1。
如果该队列条目还没有最小化的trace_bits数组,则是哟个minimize_bits函数分配和填充一个数组。
最后设置变量score_changed为1,表示位图已经更新。
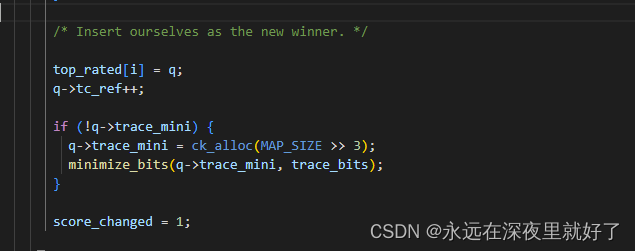
第一次dry_run,我们差不多分析完了,但是后续还有一些处理操作,我们简单分析一下。
cull_queue
执行完perform_dry_run这个函数之后,就会执行cull_queue函数。
这个函数的主要作用是精简队列。

工作原理就是遍历top_rated中的每一个queue。然后寻找能够发现新的edge的queue,并标记为favored。这样在下一轮fuzz的过程中,这些能够发现新edge的queue就有更多执行fuzz的机会。
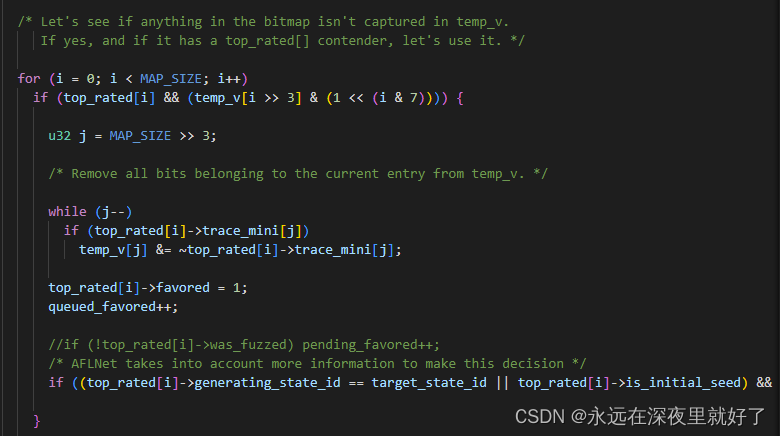
进入主循环之前的一些准备工作
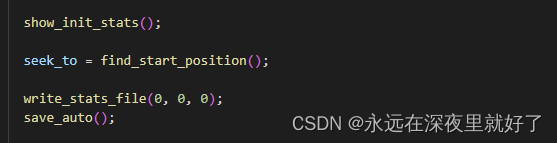
find_start_position函数的作用是找刀一个queue入口的testcase,也就是一个testcase队列的第一个testcase。然后返回值传给seek_to,后面会用到。
write_stats_file函数时更新状态的函数。
save_auto函数是更新token的函数,保存token的目录为"%s/queue/.state/auto_extras/auto_%06u", out_dir, i
fuzz主循环
首先调用cull_queue优化队列:

queue_cur表示当前遍历到的queue,也就是queue_current的意思。
如果queue_cur==0,则表示已经完成了对队列的遍历。
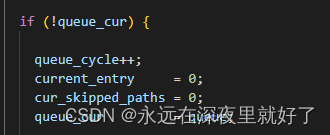
seek_to我们前面说过了,是通过find_start_position函数得到的,目的是为了找到queue的开始testcase。
下面通过一个循环,使queue_cur移动到了queue的首部,也就是一个queue的开始。

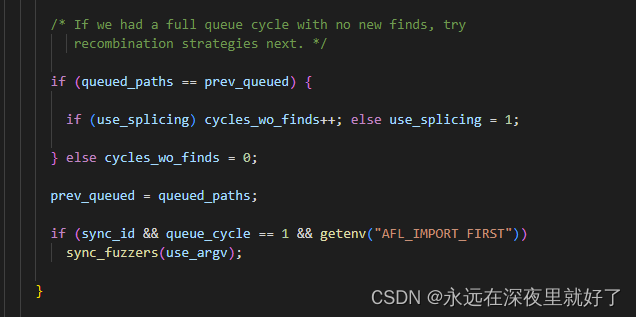
然后如果循环了一整个queue之后还是没有新的发现,则需要重组策略。
其中,sync_fuzzers这个函数,作用是读取其他fuzz的queue中的testcase,然后保存到自己的queue中。
fuzz_one 重点函数
这个函数特别长,有接近两千行,是变异策略的具体实现过程。限于篇幅,本文不对其进行分析,后续会专门写一篇博客对其进行研究,主要关于变异策略的添加与改写。
本文仅为个人学习记录,若有错误,欢迎私信指正。














 5330
5330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









