






background
The data for segmentation is hard to get as it need pixel-wise label.
contribution
Find a new way to generate labeled data
method
(1) Use classification network to generate the seed of CAMs:
classification network: A series of convolution layers follow by a fully connected layers
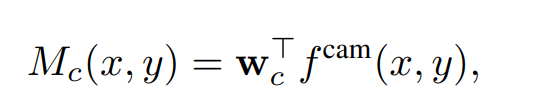
Mc is the function of CAMs,
w
c
w_c
wc is the weights of the last fc layers.
f
c
a
m
f^{cam}
fcam is the output of the last convolution layers.
I used to have a question that how the 7*7 feature map become the heat-map is not like chess. I try by myself and find that due to the effect of “cv2.reize”.
(2) Use the seed of CAMs to generate “Affinity” by AffinityNet
Affinity W W W:
the measurement of the probability to pixel are in the same class. In this essay, the AffinityNet output a vector and the Euclid distance of the vector D, and e − ∣ D ∣ e^{-|D|} e−∣D∣ is the value.
Data to train AffinityNet:
The pair which subjects to explicitly belonging to background or object area, and their distance less than a values (a hyper parameter).
The question of these Data
But this will cause the unbalance between the positive and negative samples, as most pixel in this field form positive samples.
So we need to divide the sample into two subset, and then sample from them evenly.
The area of background*:
disregard
M
c
′
M_{c'}
Mc′ by making its activation scores zero and then (?)
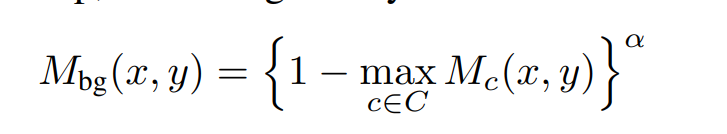
Loss of Affinity Net:
cross-entropy loss by image_label
(3) random walk
Now we can have a Affinity matrix T: the i th rows is the transit probability from the pixel within specific distance between the i th pixel
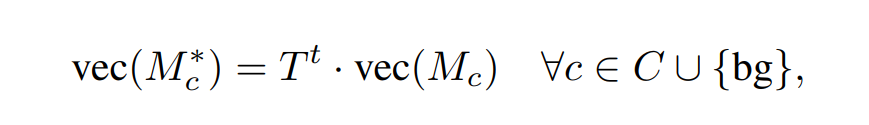
So we can get the refined CAMs















 8053
8053











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









