







p509-522
List接口
ArrayList
1.Arraylist 可以加入null,并且多个定什么都能放
2.ArrayRist 和yector其生一致,但A)是成程不安全的源码没有synchronized.优总是效率高
王.Amayeit底层由数数组实现.
阶以变线程的情况下不建议用Arroyst
源码分析
)Aranglast中主d户了-个obje化类的数组
element Date:
2.创建AL时,老用的无参构造器,则初始
elementPnte容量为0第次添加扩容为10.
当需要再次添加时,到1.5倍
0—→10→5→22
3. 老使用将定大小的构造器,要需要广容时就直接扩到1.5倍
如:ArrayList list=new Anaylist(8);后8→12→18→27
transi'ent Obiect[] element Data;
表示该属性不会被序列化。
P51) 讲了Araylist底层的扩容机制
P512 首有将定大小的构造器的Arraytist
有参:CJ第一次扩容就按照1.5倍扩容
(2)整个执行流程和前面一样
建议:自己去debng.一把扩容体程.
Vector
<E>是什么?
1.Vector底层也是一个对象类文组.protected Object[ ] element Data;
2.Vector是线程同步的.即线程安全:有synchronized
3.开发时,需要线称同步安全时,用Vector.
(不需要时,用Arraylist.因为效率高)
LinkedList


package com.day25;
import java.util.LinkedList;
import java.util.Vector;
public class Day25 {
public static void main(String[] args) {
Node jack = new Node("jack");
Node mdk = new Node("mdk");
Node lan = new Node("lan");
//形成链表,连接三个节点!
jack.next=mdk;
mdk.next=lan;
lan.pre=mdk;
mdk.pre=jack;
Node first = jack;//让first引用指向jack,也就是头结点
Node last = lan;//尾节点
//遍历:
while (true){
if(first == null){
break;
}
System.out.println(first);
first=first.next;
}
//添加节点到mdk和lan之间
Node simis = new Node("simis");
mdk.next = simis;
simis.next=lan;
lan.pre = simis;
simis.pre = mdk;
System.out.println("=======添加后======");
first=jack;
while (true){
if(first == null){
break;
}
System.out.println(first);
first=first.next;
}
}
}
class Node{
//表示双向链表的一个节点(对象
public Object item;//真正存放数据的地方
public Node next;
public Node pre;
public Node(Object name){
this.item = name;
}
public String toString(){
return "Node name:"+item;
}
}
删除节点源码:
remove-removefirst-unlinkFirst
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
遍历:
由于LinckedList实现了List接口,所以遍历方式也是一样的:迭代器、增强for、普通for
ArrayList和LinckedList对比

Set接口
Set接口和常用方法
1.无序
2.不允许重复元素,所以最多包含一个null
常用方法:
和List接口一样,Set接口也是Collection的子接口,因此常用方法和List一样
Set接口的遍历方式
1.可以使用迭代器
2.增强for
3.不能使用索引的方式来获取
![]()
发现它存放的数据是无序的!(即添加的顺序和取出的顺序不一致)但是它这次这样取了,下次还是这样取的,取出的顺序是固定的。底层是数组+链表的形式!
public static void main(String[] args) {
Set set = new HashSet();
set.add("14");
set.add("12");
set.add("53");
set.add("24");
set.add("56");
set.add("68");
set.add(null);
System.out.println(set);
}
1.HashSet
1.HashSet的底层其实是HashMap
HashMap的底层是数组+链表+红黑树
结构:
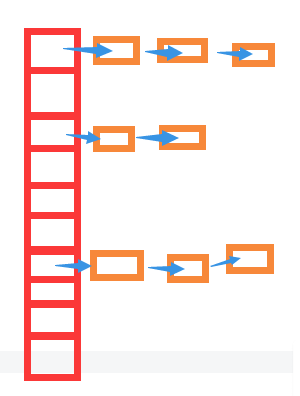
把每个链表的头结点存在table数组里面,效率非常高。
2.HashSet是可以放null的,但是只能放一个,数据是不能重复的!
3.HashSet不保真元素是有序的,取决于hash后,再确定索引的结果。
经典面试题
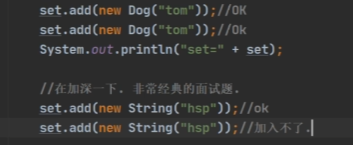
1.HashSet底层是HashMap
2添加一个元素时,先得到hash值-会转成->索引值
3.找到存储数据表table,看这个索引位者是否已经存放的有元素
4如果没有。直接加入table里
5.如果有,调用equals比较,如果相同,就放弃添加,如果不相同,则添加到最后
6.在Java8中,如果一条链表的元素个数超过TREEIFY_THRESHOLD(默认是8)。并且table的大小>=MIN TREEIFY CAPACITY(默认64).就会进行树化(红黑树)
源码来咯
HashSet的add底层干了什么-1
首先new一个HashSet的时候:
public HashSet() {
map = new HashMap<>();
}
接下来打开add:这里的map是HashSet里的一个字段,是HashMap
put是map 的一个方法,参数e是泛型,这里姑且当它是我hashset.add(“小小肥橘”)的这个小小肥橘。PRESENT是HashSet类里的占位符,
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
接下来我们进入put,这是HashMap 的方法(毕竟是map.put)

public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
那么,实际上前文的e就是这里的key,key是“小小肥橘”,value是PRESENT占位符,不管它。
不管以后这个key变化了多少次,value都是不变的。
接下来,分析这个put方法,它返回了putVal,参数有hash(key),我们进入hash这个方法:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这也就解释了null为什么总是在HashSet里排在0号位。往右位移16位是为了避免碰撞哈希值。注意这个hash方法返回的不是hashCode!!
回来接着看putVal方法:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i;//定义了辅助变量 if ((tab = table) == null || (n = tab.length) == 0)//这个table是HashMap的一个字段,用来存放Node节点的数组 n = (tab = resize()).length;//给tab进行resize,这个方法进入后发现是在对table进行计算扩容的值,默认是16,并且按照0.75来进行提前扩容,比如存放到12的时候就继续扩容它。执行了resize()后,table的大小就变成了16 if ((p = tab[i = (n - 1) & hash]) == null)//根据key得到hash,去计算key应该放在哪个位置,并把这个位置的对象赋给p,如果p是否为空,就创建一个节点,并存到这个tab【i】的位置。 tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount;//表示我们修改的次数 if (++size > threshold)//如果放入的数据超过了缓冲线12,就扩容 resize(); afterNodeInsertion(evict);//其实它什么都没干,给HashMap子类实现用的 return null;//返回空的意思就是,我刚刚添加的这个对象,里面是没有的,也就是添加成功了。否则,见前文还会return别的 }
HashSet的add底层干了什么-2
脑壳痛,先睡了...















 732
732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









