







引言
机器学习:无需具体编程让计算机自己学习。
大致分为监督学习和无监督学习
一:监督学习
learns from being given “right answers”
给标签x正确答案y,目的是让机器找到更多类似的正确答案
例如:预测房价
两大类:分类、回归。
二:无监督学习
不告诉机器答案
三大类:聚类、异常检测、降维
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
线性回归模型

预测房价:
是监督学习:每个输入的x(房子大小)都有正确答案y(房价),当我的房子大小是1250时,房价应该是多少?(回归)
图1的数据为训练集,x为“输入变量”,又叫特征。y为“输出变量”(目标变量),将训练集的数据(特征和目标)输入算法中,通过算法自己确定一条直线f(x)=wx+b(模型)
通过function(模型)进行预测,得到y-hat(预测值)。
实现步骤
1.寻找成本函数(损失函数?)
为了不让“随着训练集变大而自动变大”,除以m
为了方便计算再除以2
#这叫均方误差

2.理解损失函数
模型f(x)=wx+b中,w为权重,b为偏置。需要寻找最合适的w和b使得预测的y-hat更接近真实值y。
不断尝试来调整预测的y-hat,那么当损失函数J最小时,就能得到最合适的参数w与b了。
一个简单的例子:
三组数据:(1,1),(2,2),(3,3)
模型:y=wx
J=上面那图上的
通过不断调整w,得到了下图:

w=1时,损失函数J=0,也就是说w=1是最优解。
J实际上是关于参数w的函数啊
回到房价的例子中,求得损失函数的图长这样:
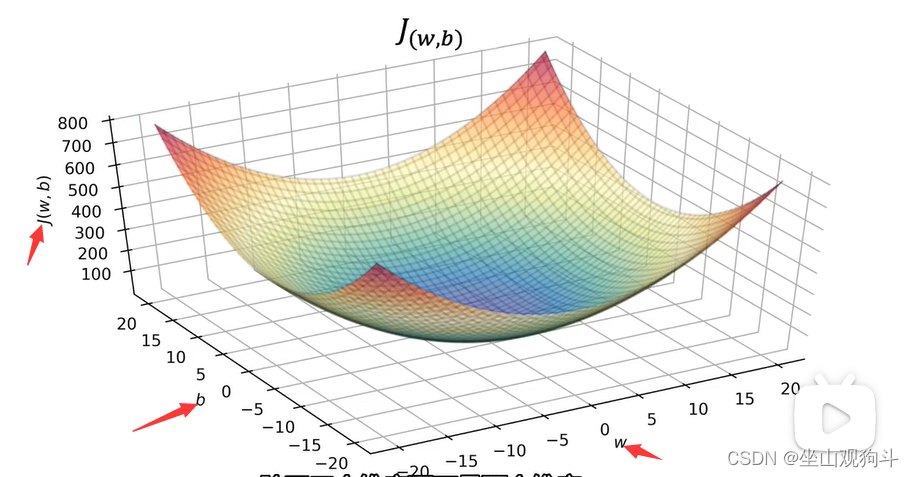
现在我们想要一个算法,让它自动找到参数w和b的值使得J最小→梯度下降
3.梯度下降法
选择一个初始的山峰,再环顾四周,找一个最陡的方向下山,每走一步就循环这个过程,最后会到达一个山谷,根据初始山峰选择的不同,可能会到达不同的山谷→局部最小值。
数学表示方法:

等号:赋值(不是数学的“等于”)
蓝色w:更新后的w
α:学习率,0~1,步长。如果α很大那你就是在下陡坡。
 表示你在向哪个方向下坡(求偏导)
表示你在向哪个方向下坡(求偏导)
同理,我们也能找到新的b:
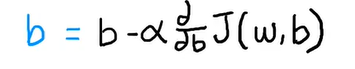
没水印舒服了
注:还有同步更新和不同步更新的区别,即“先求出了w,把更新后的w带入到求新b的公式里”
我怎么感觉不同步的方法会更快呢?不过老师说不要用这种。
理解梯度下降
先忽略b的影响,当b=0看。由于学习率是正数,斜率正了那我们就减小w,斜率负那我们就增加w,这样可以让J更小→想办法求极值(偏导数归0)。

学习率的影响:太小会收敛太慢,太大会导致你一脚跨过山谷,踩不到那个最小值。
那局部最小值怎么办?
batch gradient descent(一批梯度下降?)指在梯度下降的每一步中,我们都在查看所有的训练示例,而不仅仅是训练数据的一个子集。(就是说每次下降的时候,会把所有的参数都拿去算一次)
还有其他版本的梯度下降,训练数据集较小的子集,不过老师说这里选择批训练。
多特征(多元)线性回归
很像矩阵运算呢。
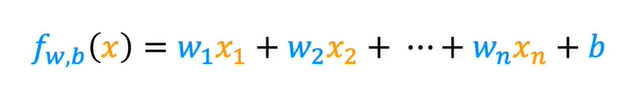
比如:
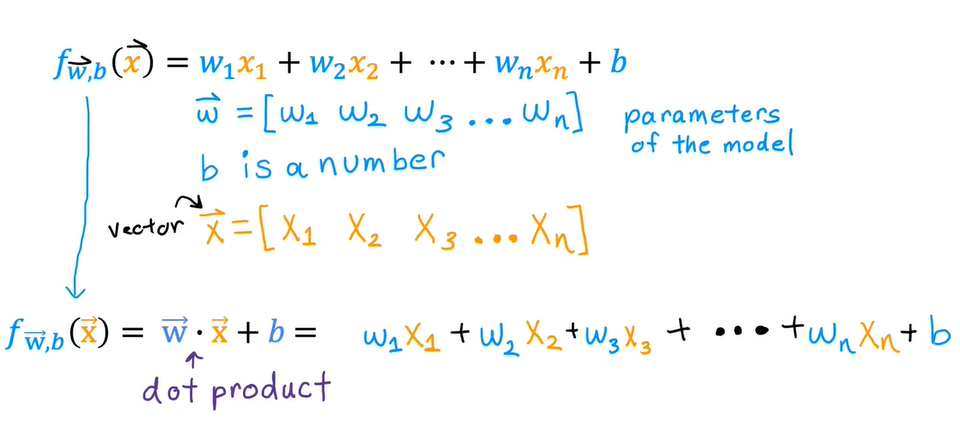
矢量化
为了让代码更简洁快速
w=np.array([1,2,3])
b=4
x=np.array([10,20,30])#本来是这样写的↓
f=w[0]*x[0]+w[1]*x[1]+w[2]*x[2]+b
#或者
f=0
for j in range(3):
f=f+w[j]*x[j]
f=f+b
#现在能这样写了
f=np.dot(w,x)+b
运行速度快是因为它并行运算的。 (x1*w1和x2*w2是同时进行的)
多特征时的参数更新方式:一次更新向量w里的每个值(就是都求一次偏导)

ps其他方法:正规方程(不泛化,慢)
今天到此为止吧24.2.27















 2953
2953











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









