







p116-p132
异常检测流程
1.假设我们有10000个好的,20个坏的。选择6000个好的作为训练集,但是不打标签,不告诉算法这是好的还是坏的。然后选择2000好+10坏作为交叉验证集,2000好+10坏作为测试集。
2.在训练集上可以得到特征的正态分布曲线,根据这个结果可以在cv(验证集)上找到异常,同样也可以在测试集上找到。
3.注意,这仍然是无监督学习算法,因为训练集上没有标签。
4.另一种方法:如果坏的数量很少,那么不再使用测试集,把全部异常都放在验证集上。数据集很小的时候不得不这样做。
我的理解:相当于用无标注训练集训练出一个特定均值和方差的正态分布,并默认两端是不正常的,再通过验证集来调整阈值。
异常检测和监督学习对比
1.当异常值(正例样本)非常少时,使用异常检测。监督学习往往有大量标记好的正负两种样本。
2.当异常千奇百怪(比如今天是太热导致发动机坏了,明天是振动太慢导致发动机坏了。。。)这时候选择异常检测:我的理解就是异常检测是拿正常的发动机特征进行训练,算法认得出什么是正常,其他千奇百怪的异常都叫异常。所以当出现一种全新的故障方式,它也能标记出异常(毕竟和它学过的正常值长得不一样)。相反,监督学习会有足够多的异常值来让它知道异常长什么样。一个正向学习,一个反向排除。
选择什么特征
1.为无监督学习选择的特征,需要是高斯分布的。如果不是,那么把它调整成高斯分布。


2.例子:监控计算机有没有异常,通常我们会从内存占用、cpu负荷、磁盘读写速度、网络流量来看,但是当你发现了有这样一台计算机,它具有高cpu负荷和低网络流量,都在正常值内,但是计算机异常了,这时我们可以通过旧的特征来建立新特征:CPU负荷/网络流量。
电影推荐系统(好抽象)
协同过滤算法
 这里的(w,b)为每个用户对于电影类型的偏好,x是电影的特征(比如爱情片、恐怖片)标签y为用户对电影的评分。通过成本函数J来求w、b、x。与前文线性回归中不一样的是,这里的电影特征也是计算得来的。
这里的(w,b)为每个用户对于电影类型的偏好,x是电影的特征(比如爱情片、恐怖片)标签y为用户对电影的评分。通过成本函数J来求w、b、x。与前文线性回归中不一样的是,这里的电影特征也是计算得来的。
梯度下降法求偏导时会过滤掉其他因素。
均值归一化
 这个矩阵的行表示电影(5部),列表示每个用户对五部电影的评分。“?”表示用户没有打分。
这个矩阵的行表示电影(5部),列表示每个用户对五部电影的评分。“?”表示用户没有打分。
进行均值归一化就是获取所有分,并计算每部电影的评价得分。注意,没打分的就不参与计算。

使用原始数据减去平均值得到的矩阵,拿来作为y,来计算w、x、b
最终得分会加上平均值μ
当新用户加入时,使用上面的参数进行计算,这样它的初始值就是群众的平均值了。
寻找相关特征
如果有一新电影,没什么人评价,或者来了个新用户,没评价过电影→冷启动。
对于新电影,可以估计导演、经费等等,对于新用户,可以了解他的年龄、性别等等。
基于内容过滤法
协同过滤中,一般会根据您给出相似评分的用户的评分向您推荐电影。
内容过滤中,寻找一些用户和电影的特征来匹配用户。
1.获取用户特征:输入用户信息(国籍、年龄、性别等),通过神经网络计算得到一个特征向量,即“电影偏好度”,比如[0.9,0.2,0.5],其中0.9表示用户对爱情片的喜好度,0.2是对恐怖片的喜好度等等。

2.相似的,输入电影的特征,得出描述电影的向量:

比如是[0.2,0.9,0.6]表示电影有0.2的爱情片成分,0.9的恐怖片成分。
3.通过两个向量求点积,得出评分,就可以推测出用户对电影的评分。

成本函数:
PCA降维
现在有两个特征x1、x2,这时候我想选择一个新轴,成为z,如何让它来替换x1、x2。
首先在使用pca之前,先把特征均值归一化(让和为0,保留偏移)。
例:房屋特征包含大小和卧室数量,通过特征缩放和归一化后,可视化为下图:

现在要找出一个z轴替换掉x1和x2轴。下图是一个例子:
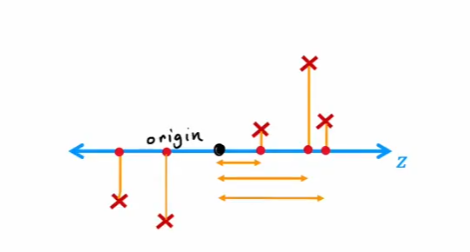
选择的这个z轴中,我们找到每个点在z上的投影作为压缩的特征。
更好的选择:

这个轴称为主成分轴(拟合的直线吗)
理解:
 当z轴(蓝)这样选择时
当z轴(蓝)这样选择时
每个数据在z的投影上是这样的:
可见有些都叠在一起了。
我们把线扭一扭:

这样每个数据在z轴的投影是: 保留了更多特征。
保留了更多特征。
疑问:你这个算法得保证x1、x2之间有线性的关系才行吧?要是完全随机分布你咋办捏?
和线性回归的区别?















 2965
2965











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









