







图机器学习(使用GNN进行频繁的子图挖掘)
1. 前言
1. subgraph
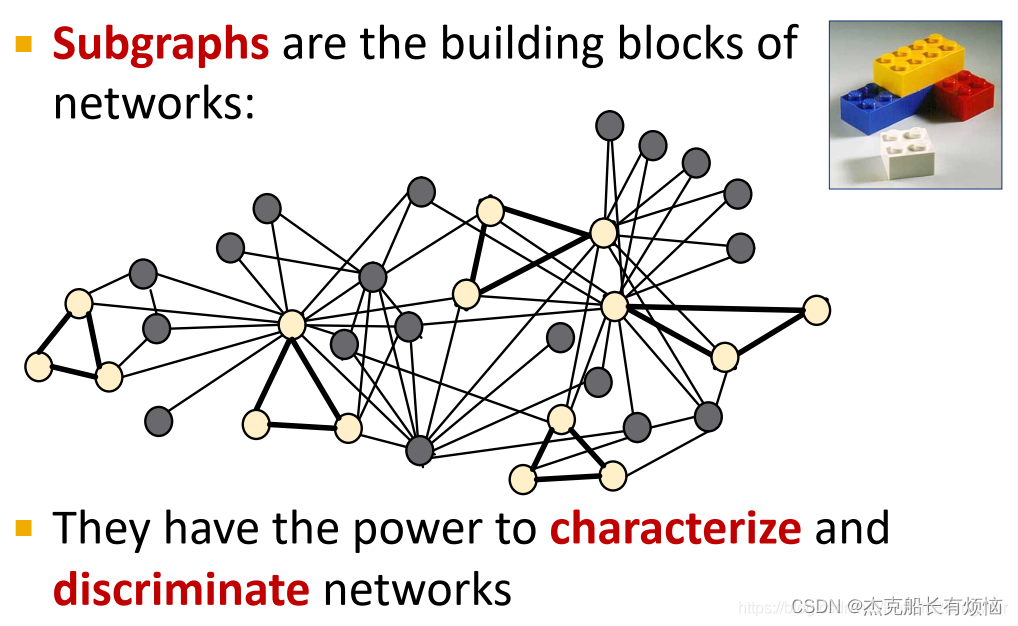
subgraph是网络的组成部分,可用于识别和区分不同的网络(可以说是不同种类网络会具有不同特征的subgraph)。
使用传统的discrete type matching方法代价很大,接下来将会介绍使用神经网络解决subgraph matching问题的方法。
2. 以下图分子式为例:含有羧基(subgraph)的分子(graph)是羧酸(group)

2. Subgraph
1. 子图的定义
对于子图的定义通常有两种,主要看适用的场景例如:
化学:节点诱导(官能团)
知识图谱:通常是边缘诱导的(重点是表示逻辑关系的边缘)
1. 节点诱导
取节点的子集和节点诱导的所有边:
常用定义:图中的一个节点子集+原图中两个节点都在该节点子集内的边。
G
‘
=
(
V
‘
,
E
‘
)
当且仅当
V
‘
⊆
V
E
‘
=
{
(
u
,
v
∈
E
∣
u
,
v
∈
V
‘
}
G^`=(V^`,E^`) \\当且仅当\\ V^`\subseteq V\\ E^`=\{(u,v\in E|u,v\in V^`\}
G‘=(V‘,E‘)当且仅当V‘⊆VE‘={(u,v∈E∣u,v∈V‘}
也叫induced subgraph由节点集决定的子图。
2. 边诱导
图中的一个边子集+该子集的对应节点
G
‘
=
(
V
‘
,
E
‘
)
当且仅当
E
‘
⊆
E
V
‘
=
{
v
∈
V
∣
(
u
,
v
)
∈
E
‘
对于部分
u
}
G^`=(V^`,E^`) \\当且仅当\\ E^`\subseteq E\\ V^`=\{v\in V|(u,v)\in E^` 对于部分u\}
G‘=(V‘,E‘)当且仅当E‘⊆EV‘={v∈V∣(u,v)∈E‘对于部分u}
3. 包含子图
上面两种子图定义都是针对从源图中取的子图,如果节点或者边是来自不同的图,那么我们把两个图称为包含关系。确定包含关系的关键之处就是确定图是否同构。

2. 图同构(Graph isomorphism)
由于节点的无序性,同构可能是NP-hard的问题(未证明),具体定义如下:
如果两个图存在一个双射函数(bijection function)f,使得:
(
u
,
v
)
∈
E
1
i
f
f
(
f
(
u
)
,
f
(
v
)
)
∈
E
2
(u,v)\in E_1 iff (f(u),f(v))\in E_2
(u,v)∈E1iff(f(u),f(v))∈E2我们就说这两个图是同构的

子图的同构问题与上面的包含关系等价。这个是NP-hard的问题
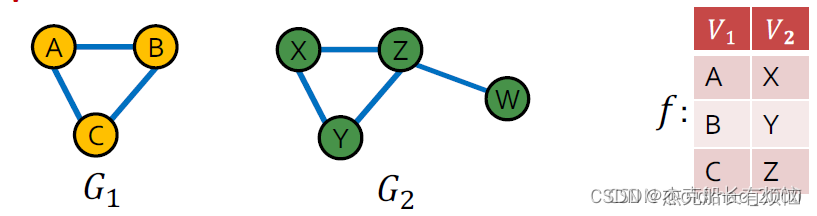
可以看到函数f不是唯一的的,这里的点顺序可以换一下,不影响结果。
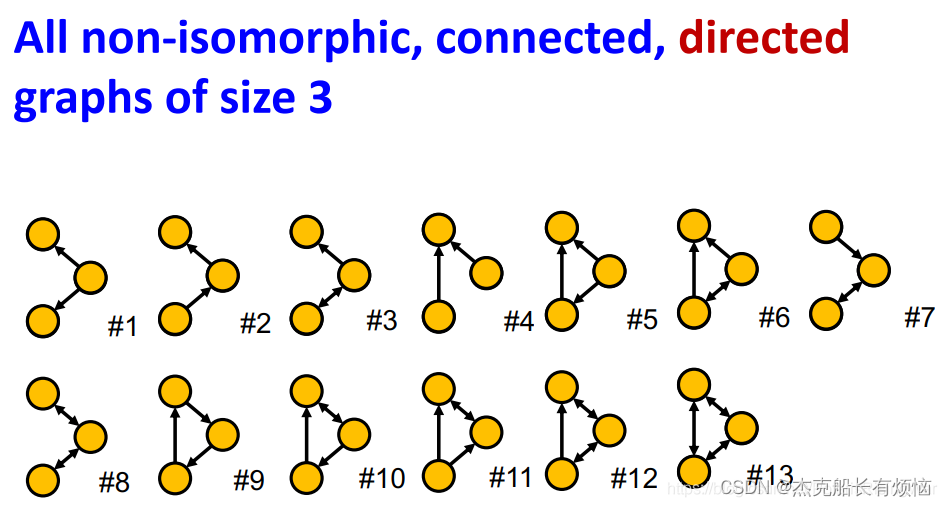
3. 举例
- 所有非同构的、连通、无向的4个节点的图:

- 所有非同构的、连通、有向的3个节点的图:
3. motif
有了上面的结论,可以继续往下推,就是一个图结构可以分解为上面的一个个小的子图构成,构成图结构的一个个小的子图就是Motif
1. Network motifs的特征
模式:小(节点诱导的)子图
重复:发现多次,即高频
显着:比预期更频繁,即在随机生成的图形中
2. 举例
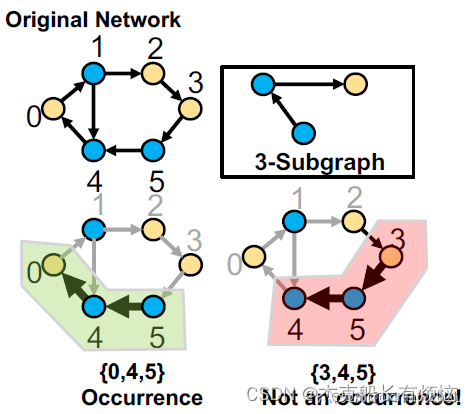
一个motif匹配的例子(induced表示是基于节点的):

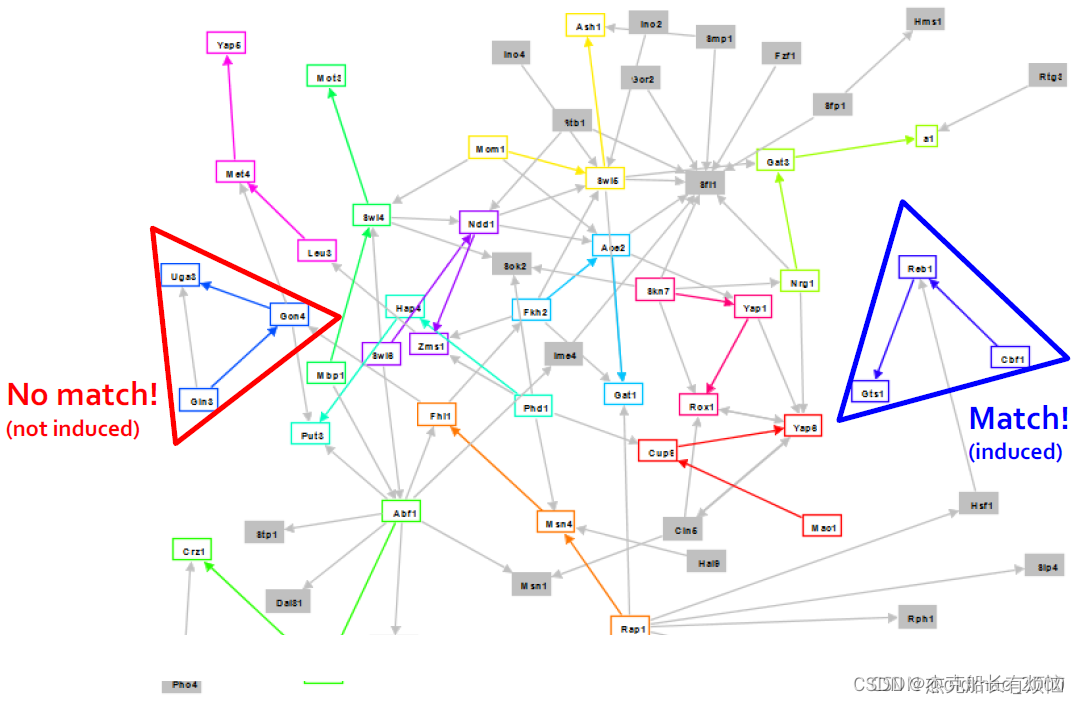
如图所示:左上角就是我们所感兴趣的induced subgraph(motif)。蓝三角内的induced subgraph符合要求,红三角内不是induced subgraph不符合要求。
3. motif的作用
1. motif的意义
1. 帮助我们了解图的工作机制。
2. 帮助我们基于图数据集中某种subgraph的出现和没有出现来做出预测
2. 例子
- 前馈环(feed-forward loops):神经元网络中用于中和生物噪音
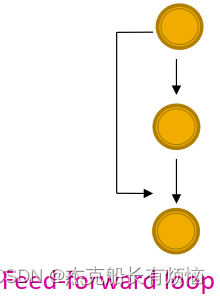
- 并行环路(parallel loops):食物链中(就两种生物以同一种生物为食并是同一种生物的猎物嘛)
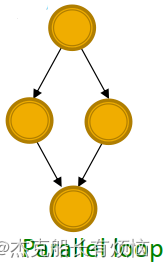
- 单输入模块(single-input modules):基因控制网络中

4. subgraph frequency
1. 图级别的subgraph frequency定义
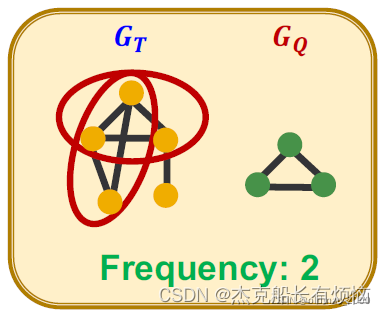
设 G Q G_Q GQ是一个小图, G T G_T GT是目标图数据集。
G Q G_Q GQ在 G T G_T GT中的频率: G T G_T GT不同的节点子集 V T V_T VT的数目( V T V_T VT诱导的 G T G_T GT的子图与 G Q G_Q GQ同构)
图中频率为2
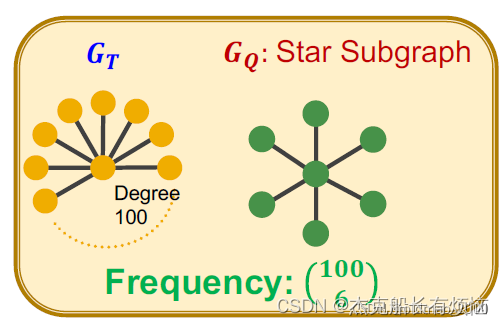
图中频率为 C 100 6 C_{100}^6 C1006
2. 节点基本的subgraph frequency定义
设 G Q G_Q GQ是一个小图,v是其中一个锚点, G T G_T GT是目标图数据集。
G Q G_Q GQ是 G T G_T GT中的频率: G T G_T GT中节点u的数目( G T G_T GT的子图与 G Q G_Q GQ同构,其同构映射u到v上)
( G Q , v G_Q,v GQ,v)叫节点-锚点子图,这种定义对异常值有很好的鲁棒性
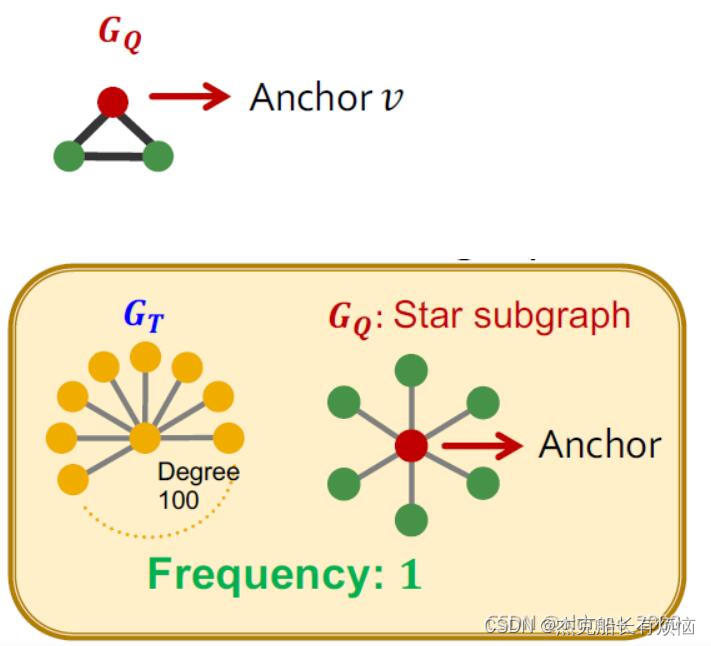
可以看到中心点只算了一次。
如果 G T G_T GT是个多个图,则可以将不同的图堪称同一个图的非连通子图来进行计算。
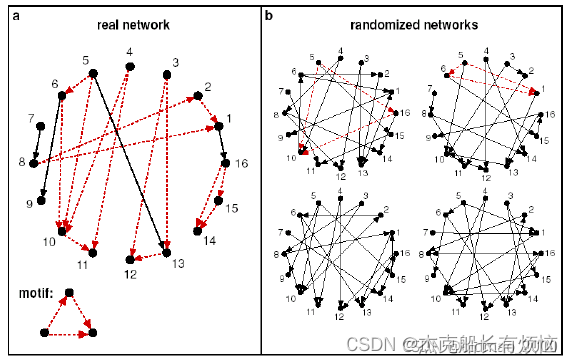
5. Motif significance(重要性/显著性)
主要体现在:现实世界中的图比起随机生成的图具有更加功能意义。
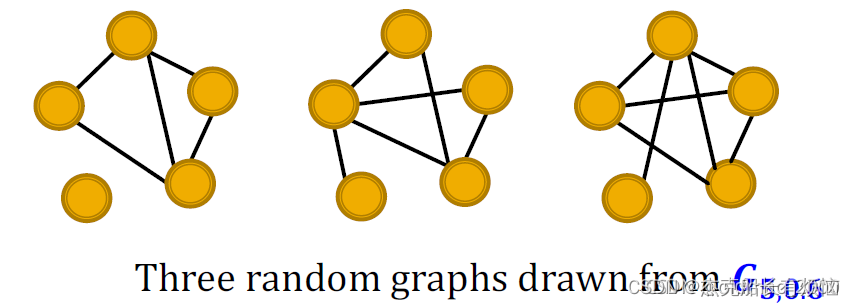
1. 随机图生成法:ER
ER随机图可以定义为: G n , p G_{n,p} Gn,p,意思是含有n个节点的无向图中,每条边(u,v)以独立同分布的概率p出现
2. 随机图生成法:Configuration model
配置模型的目标是以给定的度序列: K 1 . K 2 … … , K n K_1.K_2……,K_n K1.K2……,Kn生成一个随机图。他可以作为网络的null model【1】,用来比较具有相同度序列的真实图 G r e a l G^{real} Greal和随机图 G r a n d G^{rand} Grand
Null model的定义:就是随机图,但每个随机图和真实图有相同的节点数量、边数量、度分布相同。
下面是一个configuration model的例子,可以看到节点的度分别是3421,图中叫spokes(条幅)
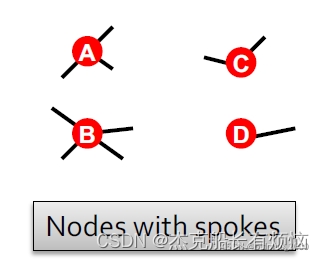
然后对节点进行两两配对(随机的)
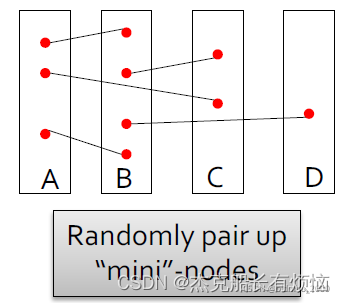
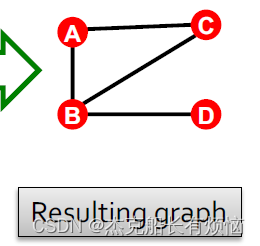
得到生成的图,生成过程中如有重复的边则忽略(上面AB就出现两次,但是结果中只有一条边),有自循环也忽略:
3. 随机图生成法:Switching
这种方法可以看作是交换法
- 给定图G
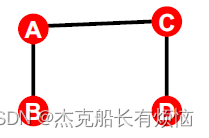
- 重复以下步骤Q ⋅ ∣ E ∣次

- 随机选两条边,例如AB和CD
当于在保证度不变的情况下,随机重新连接图中的边。(通常Q = 100,该算法可以收敛。)
4. Motif significance 计算步骤
由于在真实图中Motif 出现次数要比随机图多(overrepresented),因此我们的思路就是用随机图来 和实际图进行Motif的频次统计比较,步骤如下:
- 在真实图中统计motif的个数。
- 产生多个与真实图有相同统计量(如节点数、边数、度数序列等)的随机图,在这些随机图中统计motif的个数。
- 使用统计量(Z-score)来评估每个motif的重要性
1. Z-score计算公式:
Z i = N i r e a l − N ‾ i r a n d s t d ( N i r a n d ) Z_i=\frac{N_i^{real}-\overline N_i^{rand}}{std(N_i^{rand})} Zi=std(Nirand)Nireal−Nirand
其中 N i r e a l N_i^{real} Nireal是真实图中motif i的个数, N ‾ i r a n d \overline N_i^{rand} Nirand 是随机图实例中motif i ii 的平均个数。 s t d ( N i r a n d ) std(N_i^{rand}) std(Nirand)表示标准差【2】
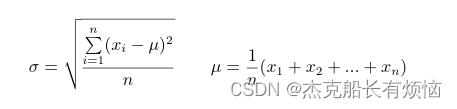
0就是说真实图和随机图中motif出现的一样多。绝对值大于2时就算显著地多或者显著地少。
2. 网络重要性表现(sp)
S P i = Z i ∑ j Z j 2 SP_i=\frac {Z_i}{\sqrt{\sum _jZ_j^2}} SPi=∑jZj2Zi
SP 是归一化的Z-score向量,其维度取决于我们考虑的motif的数量。
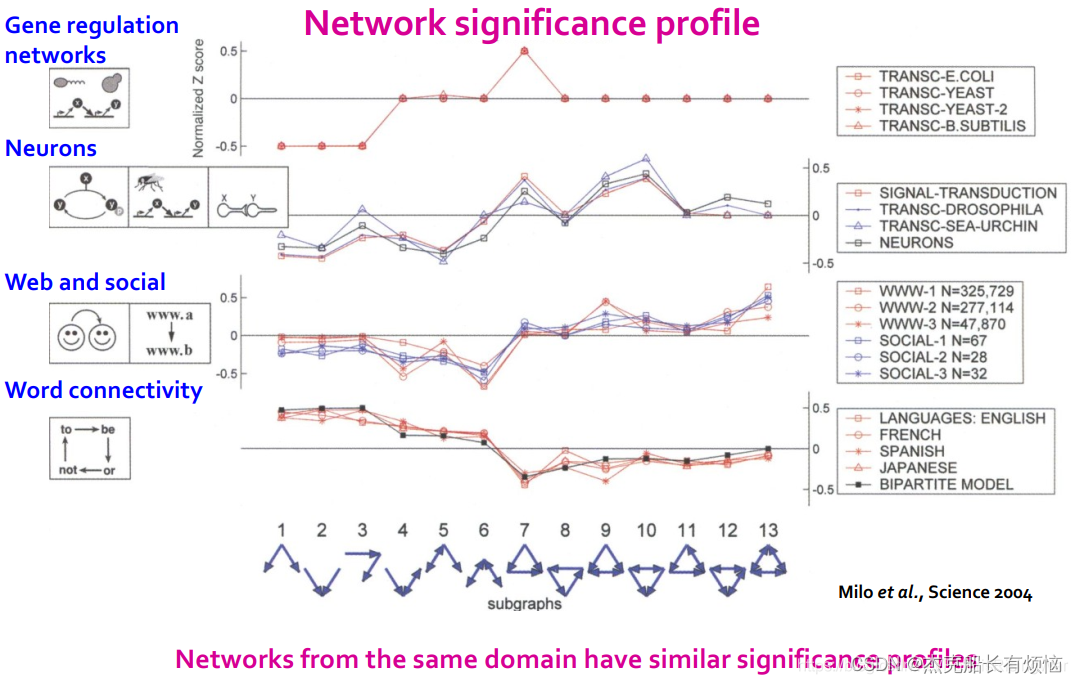
SP 强调subgraph的相对重要性:在比较不同大小的网络时很重要,因为一般来说,大图会出现更高的Z-score
不同领域的motif有不同的特点,各自的领域都有相似的sp
6. Motif扩展及概念变体
1. 扩展
§ Directed and undirected
§ Colored and uncolored
相当于考虑不同节点类型,如下图:
时空、静态图
2. 变体
- 不同频率的概念
- 不同重要性的指标
- 代表性不足(anti-motifs)
- 不同的null model【1】
7. Neural Subgraph Matching / Representations
1. 子图匹配
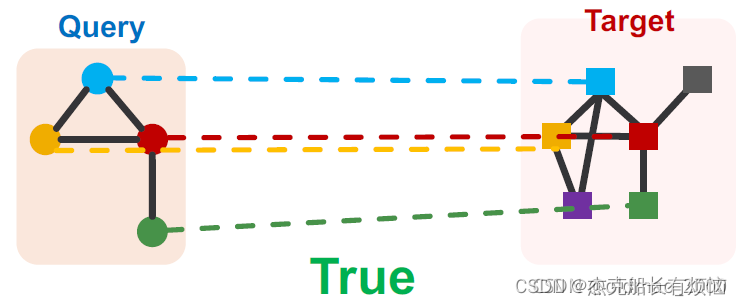
目标图可以是不联通的(can be disconnected),查询子图必须是联通的(connected)。
然后把这个任务转化为机器学习的二分类问题:
如果查询与目标图的子图同构,则返回 True,否则返回 False
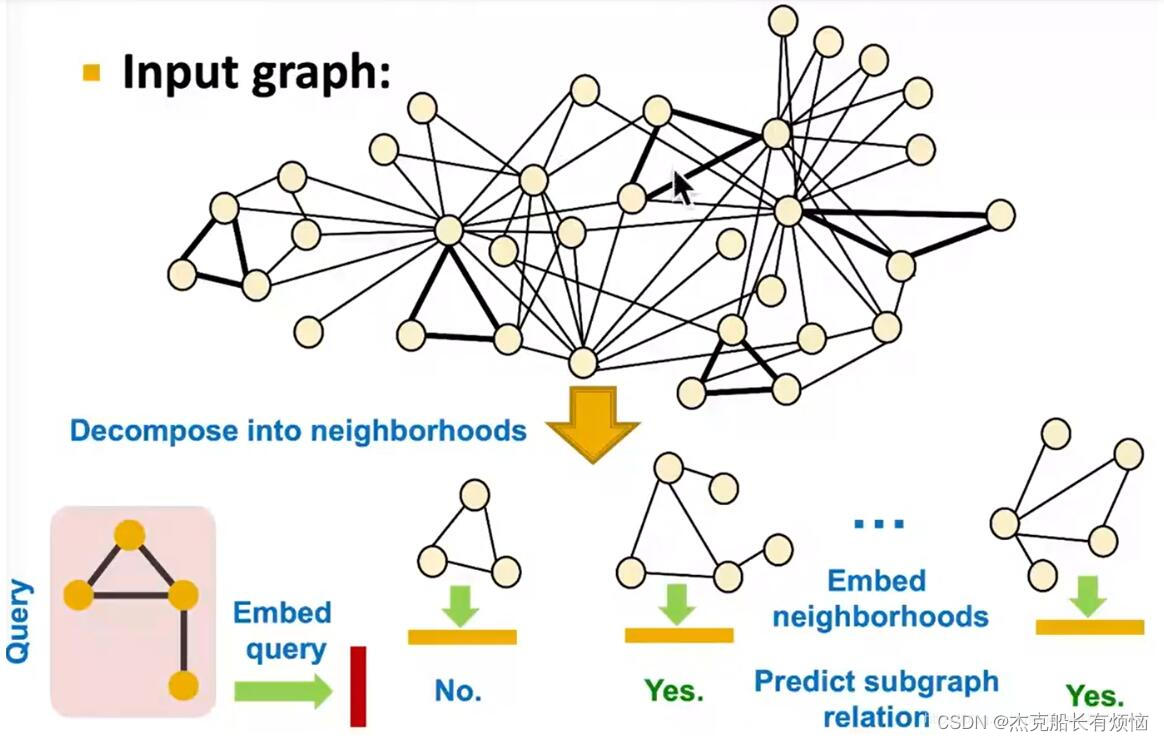
2. 整体流程
- 将输入的图进行分解得到子图
- 求分解后的子图的embedding
- 将查询子图和分解子图embedding进行匹配,做预测
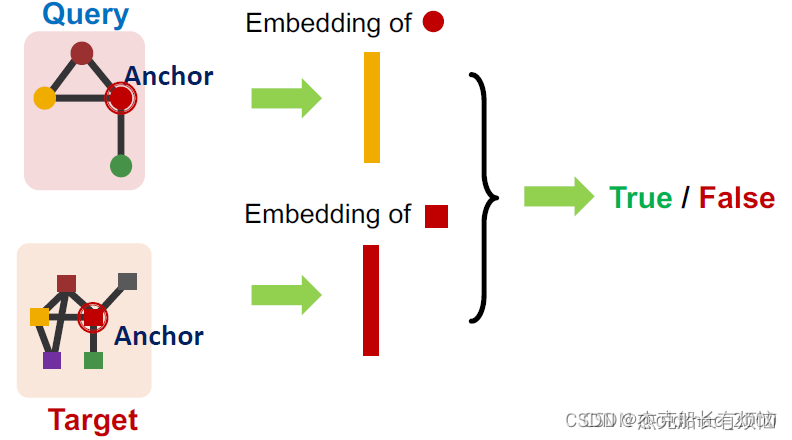
3. neural architecture for subgraphs
在进行子图比较前,先要给出几个Neural architecture常用定义:
- node-anchored definitions:要以anchor为基准进行比对
2. node-anchored neighborhoods:基于锚点可以得到锚点的n跳邻域信息
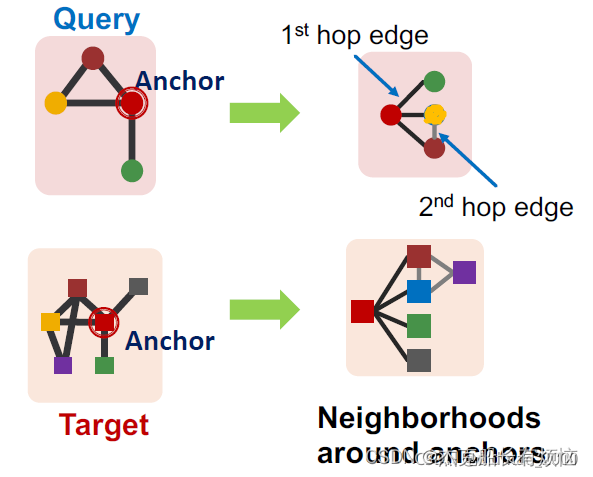
上面两个例子看起来就是GNN思想:
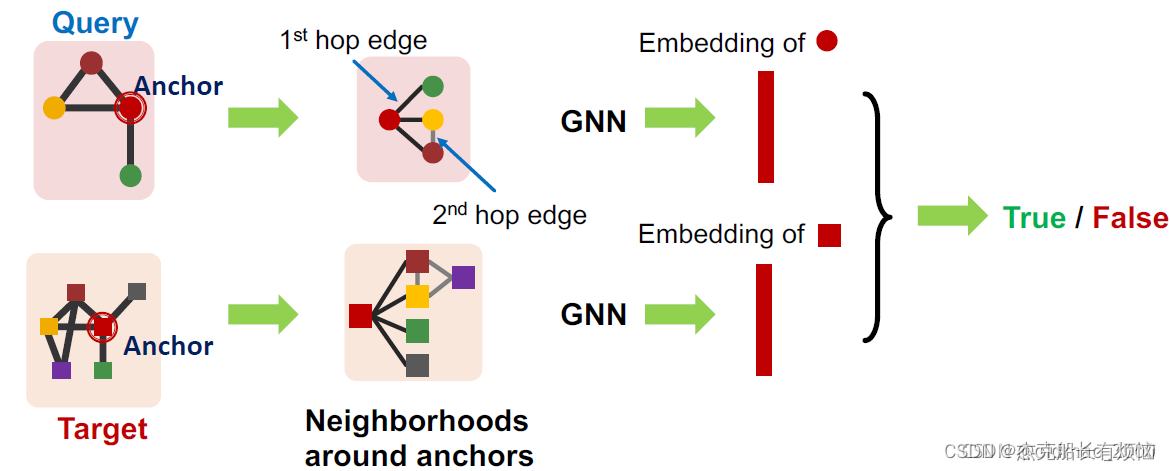
也就是可以用GNN来计算两个锚点的embedding,并用embedding来判断两个锚点的邻域是否同构;另外还可以通过这个方法来得到两个锚点的对应(mapping)关系。
4. G T G_T GT的分解
实际上就是获取图中每一个节点的领域表示。
对于每一个节点在 G T G_T GT:
- 获取锚点周围的k跳领域
- 可以使用广度优先搜索 (BFS) 执行
- 其中深度K就是一个超参
注意:深度越深,模型的成本约高
5. Order embedding space
有序特征空间:将图A映射到高维(64维)的特征空间,得到 Z A Z_A ZA这里假设所有维度都是非负的。这样可以捕获到图表征的Ordering(transitivity)特性,例如:
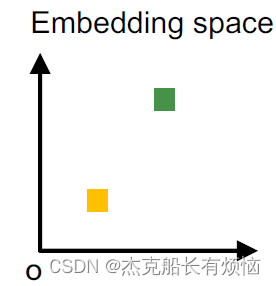
左下角的这个黄色方块其实表示了是绿色方块的子图关系。
根据transitivity特性,则有:

用这个空间来判断子图的关系:
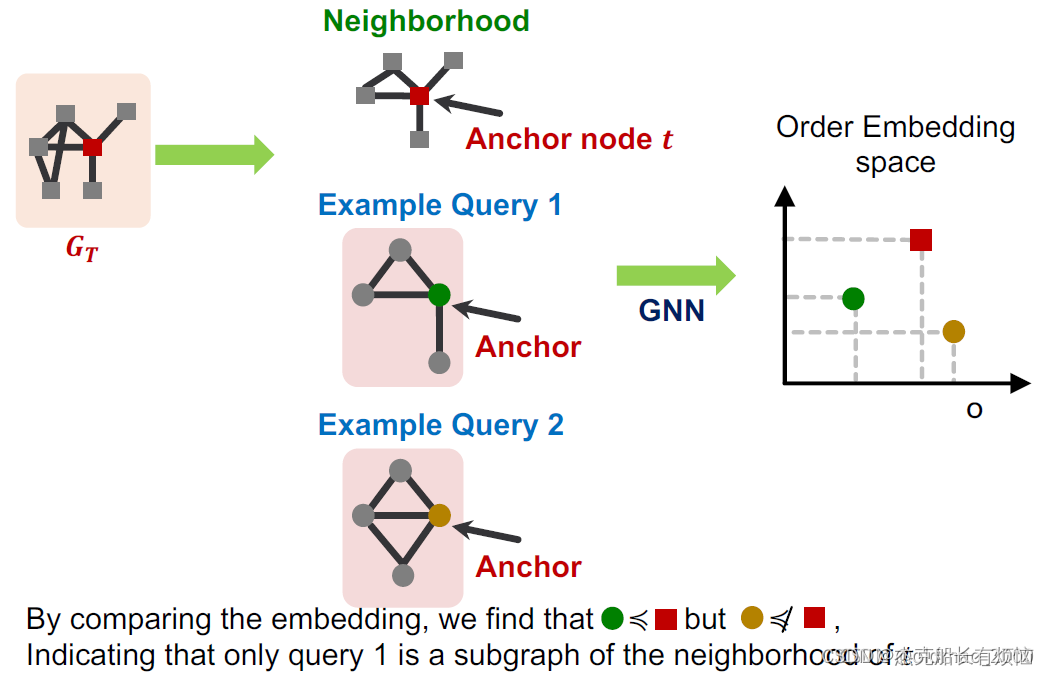
6. Order embedding space的特点
Order embedding space很好的表达了子图的同构关系,同时还有以下三个特性:

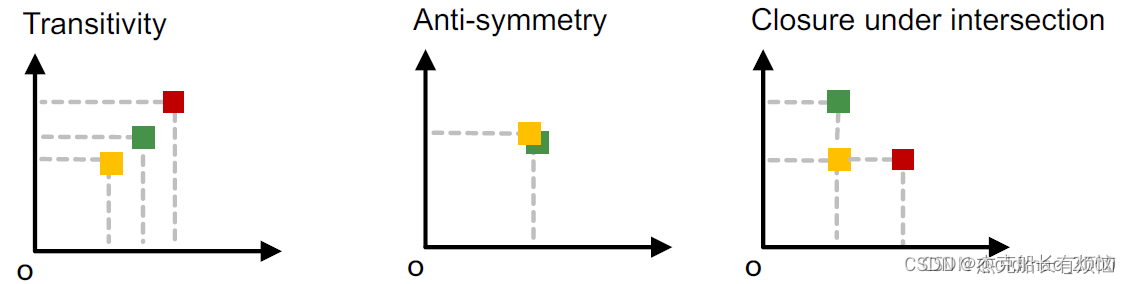
7.Order Constraint
如何使得GNN学习到的图表征能有上面提到的Order Constraint(可以在空间中反映子图的关系)呢?这里就需要设计一个loss函数。
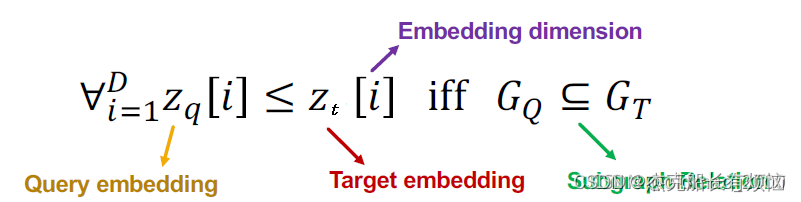
这个损失函数非常的直观,只要图 G Q 是 G T G_Q是G_T GQ是GT的子图,那么对于所有的维度 i i i都满足上面的条件: z q [ i ] ≤ z t [ i ] z_q[i]\leq z_t[i] zq[i]≤zt[i]
然后用max-margin loss来训练,两个图的距离可以用下面公式表示:
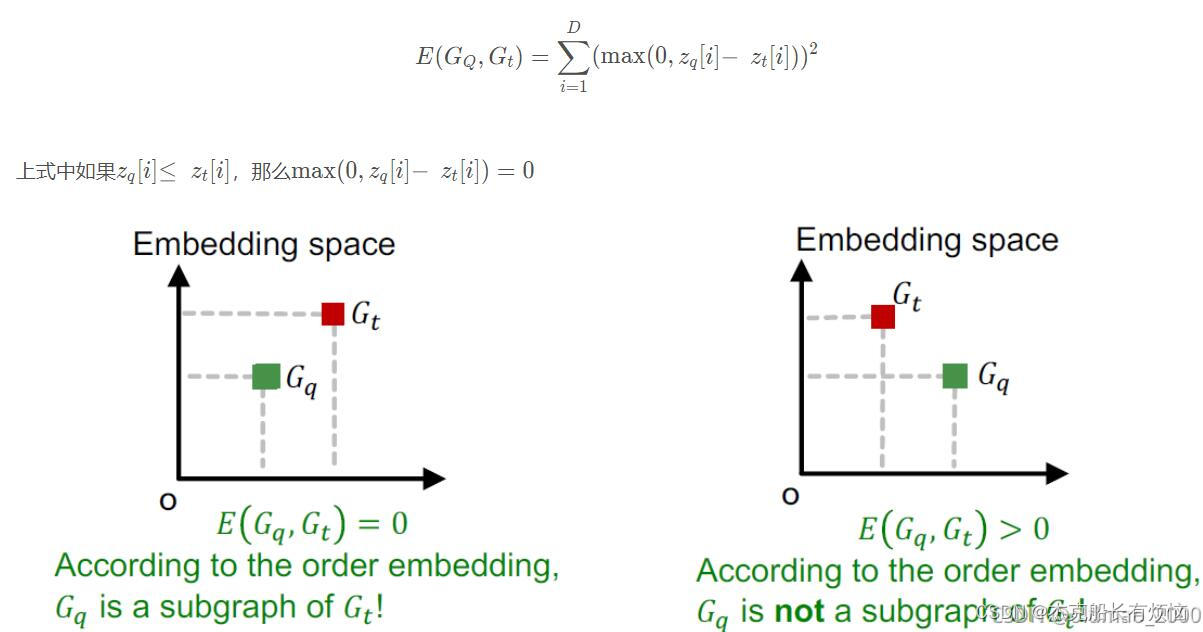
8. Training neural subgraph matching

8. Mining / Finding Frequent Motifs / Subgraphs
有两个挑战:
1. 穷举所有大小为k的motif(connected subgraphs)
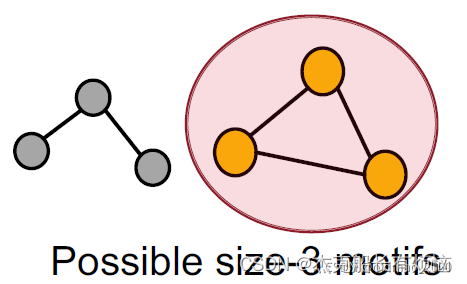
2. 计算每种motif在图中出现的次数。
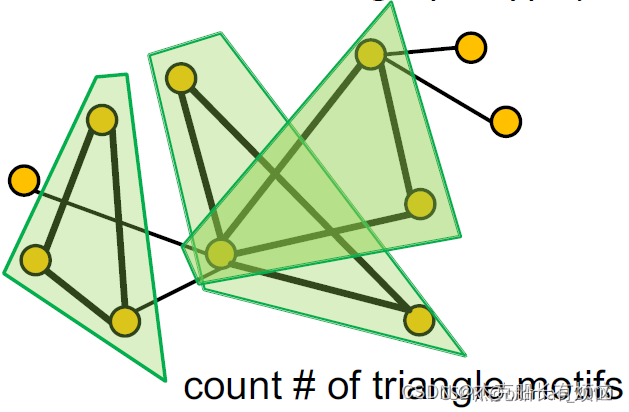
3. 解决方案
1. Representation Learning
对于问题1可以通过search space解决,不直接枚举k节点的子图,而是从小子图开始,每次增加一个节点,直到k个节点为止,具体看后面。对于问题2可以通过上节的GNN子图同构分类问题解决。
2. 设置
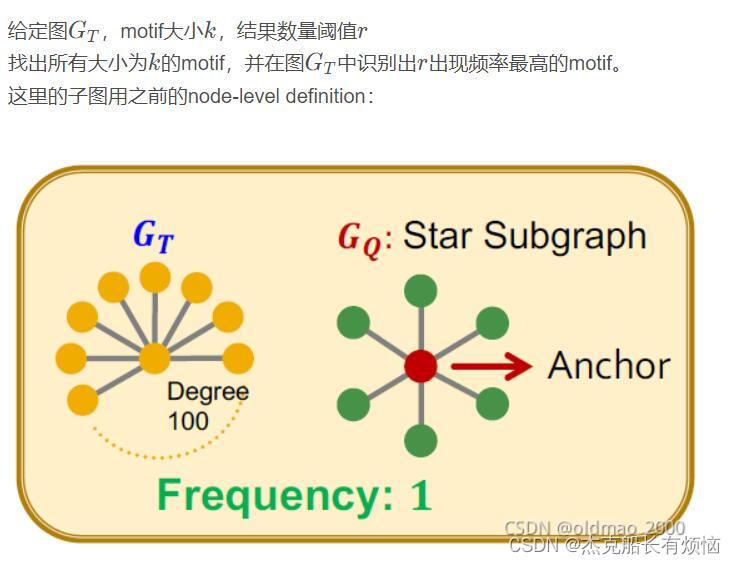
6. SPMiner:概述
SPMiner:识别高频motifs的神经网络模型
- 输入是 G T G_T GT
- 然后是分解为anchor neighborhood
- 然后用GNN学习到order embedding space
- 最后是将motif逐步增大,并在order embedding space找出对应的最大出现频率
7. Motif Frequency Estimation
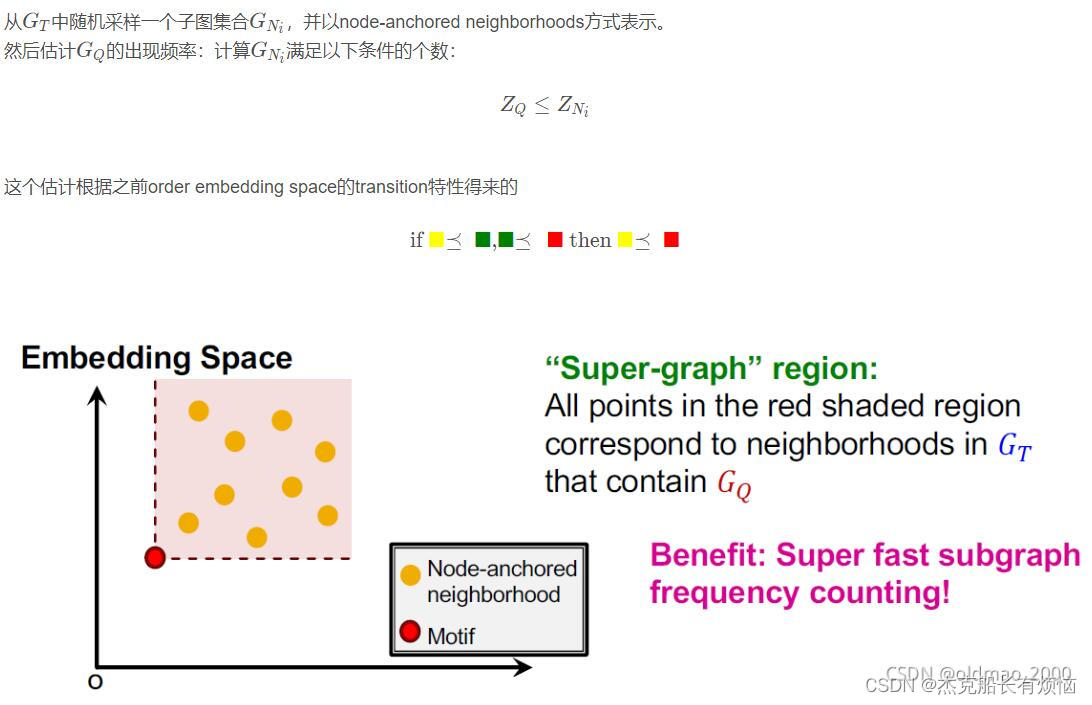
这个方法的好处是计算很快( G N G_N GN可以提前计算好,剩下都是比较运算当然快)
8. SPMiner 搜索过程
下面步骤中的目标是最大化红色阴影区域中点的数量
-
因此刚开始的时候,目标图 G T G_T GT中所有采样出来的子图的embedding都在节点u 的右上角
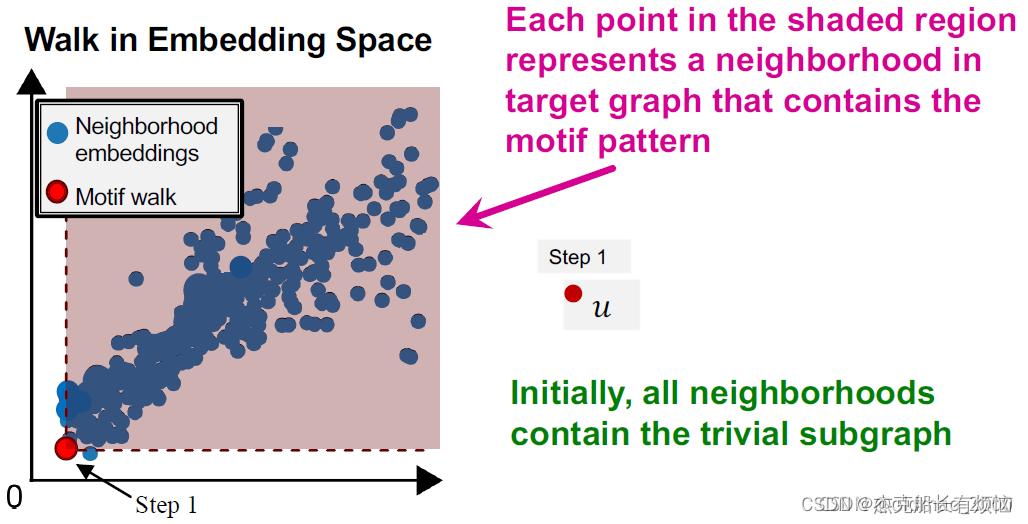
-
迭代
通过迭代选择 S 中节点的邻居并将该节点添加到 S 来扩展主题 我们希望扩展motifs以找到更大的motifs!这里从第三个节点开始,这里的motif增加节点要在蓝色节点中选,避免的motif的生成计算。
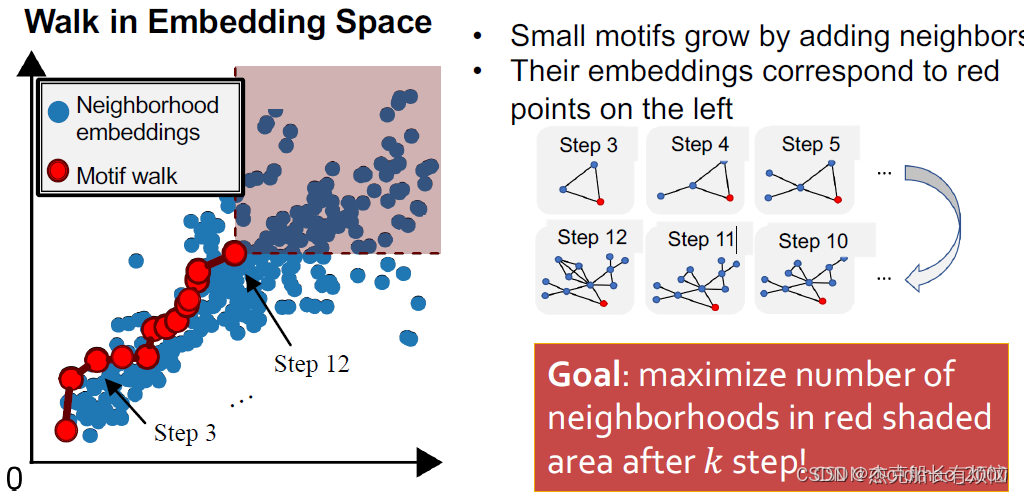
- 终止
达到所需的基序大小时,取由 S 诱导的目标图的子图
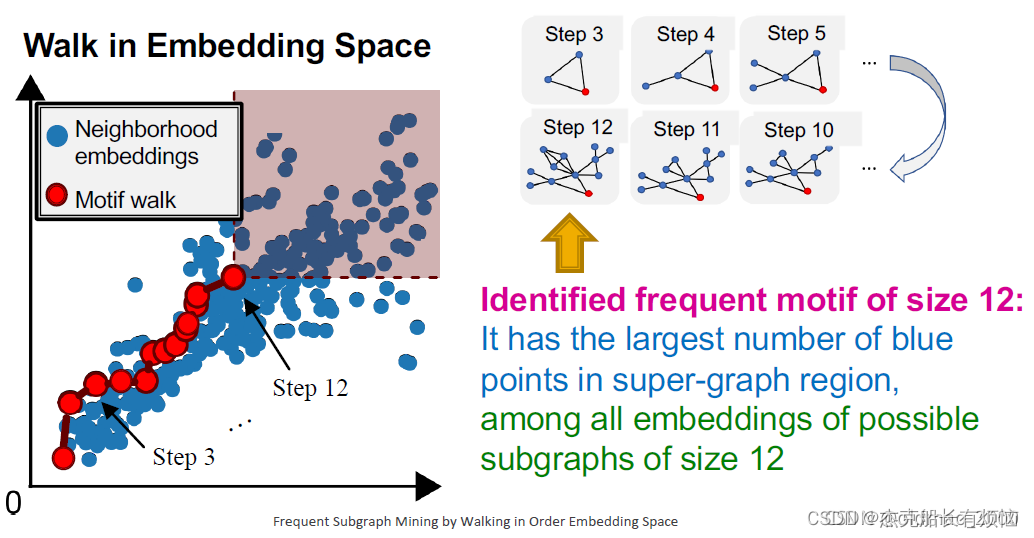
这里每个step使用贪心算法来求跳转的红点。这里的结果和暴力枚举法类似。















 2933
2933











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









