







文章目录
一. CentralCache介绍
CentralCache是所有线程所共享的,ThreadCache按需从CentralCache中获取对象,另外CentralCache合适的时机会回收ThreadCache中多余不用的对象,避免了一个线程占用了太多的内存,从而其它线程的内存吃紧情况,达到内存分配在多个线程中更均衡的按需调度的目的。
CentralCache是存在竞争的,所有想要从这里拿内存空间的线程都需要申请锁。首先这里用的是桶锁,其次只有ThreadCache中没有内存对象时才会找CentralCache要,所以这里竞争不会很激烈:
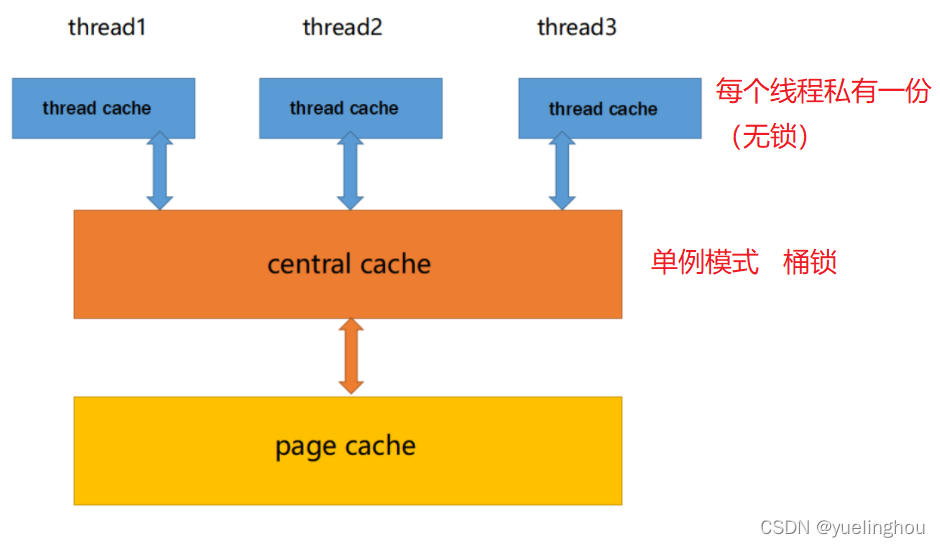
CentralCache也是一个哈希桶结构,它的哈希函数跟ThreadCache是一样的。不同的是它的每个哈希桶位置挂是SpanList链表结构,链表中存储的是以页为单位的span大块跨度内存,每一个span又按照映射关系被切成了一个个小块定长内存以单链表的形式组织起来:
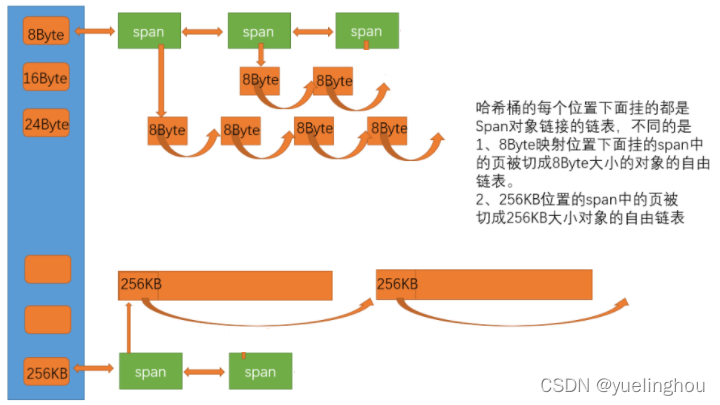
二. CentralCache相关结构介绍
1. 管理一个大块跨度内存的span类
Span类管理一个由许多连续页(一页是8KB)组成的大块跨度内存,下面是Span类的声明:
// Span管理以页为单位一个的大块跨度内存
struct Span
{
size_t _n = 0; // 页的数量
PAGE_ID _pageId = 0; // 大块跨度内存起始页的页号
Span* _next = nullptr; // 指向双向链表中前一个大块跨度内存
Span* _prev = nullptr; // 指向双向链表中后一个大块跨度内存
size_t _useCount = 0; // 被分配给ThreadCache的小块定长内存计数
void* _freeList = nullptr;// 存储切好的小块定长内存的自由链表
};
Span中记录有组成这个大块跨度内存的连续页的数量和起始页的编号。我们假设一页是8KB,即2^13个字节,计算系统中最多有多少页:

由于CentralCache自身的调节机制,一个Span所存储的页不会太多,如果Span有太多不用的页空间的话,会被下拨给PageCache负责组成更大的页。但是存储页编号的时候,在64位系统下页的数量会超过size_t的存储范围,必须要用unsigned long long类型来存储,使用unsigned long long既可以满足32位系统下的存储要求,也可以满足64位系统,我们可以统一使用unsigned long long。但是不同的系统使用不同的类型,表达的会更准确,并且区别了64位和32位系统,显示地说明了程序具有移植性,对此我们可以通过条件编译加以区分:不同的系统使用不同的页编号类型:

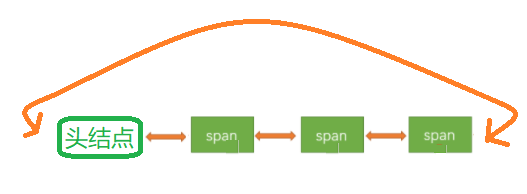
Span对象彼此之间是通过双链表SpanList组织起来的,这是因为SpanList中有任意位置插入、删除Span对象的需求,鉴于此使用带头双向循环链表会更加高效:
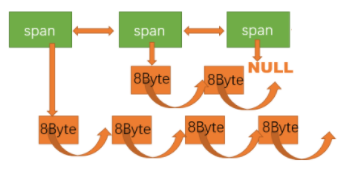
另外大块跨度内存Span中的连续页又会被切分成一个个小块的定长内存,它们通过Span里的成员变量Span::_freeList以单链表的形式组织起来:
2. 管理Span的SpanList类
SpanList是存储span节点的带头双向循环链表,它的成员变量包括一个哨兵位的头结点,还有一个该链表的专属桶锁。因为存在多个线程向同一个SpanList桶申请小块定长内存的情况,所以需要互斥锁保证线程之间的互斥关系:
// 管理span的带头双向循环链表
class SpanList
{
public:
// 构造函数中new一个哨兵位的头结点
SpanList()
{
_head = new Span;
_head->_prev = _head;
_head->_next = _head;
}
// 在pos位置插入一个新的大块跨度内存
void Insert(Span* pos, Span* newSpan)
{
assert(pos);
assert(newSpan);
// 1、记录前一个节点
Span* prev = pos->_prev;
// 2、newSpan插入到中间位置:prev newSpan pos
prev->_next = newSpan;
newSpan->_prev = prev;
newSpan->_next = pos;
pos->_prev = newSpan;
}
// 移除pos位置的一个大块跨度内存
void Erase(Span* pos)
{
assert(pos);
assert(pos != _head); // 不能删除哨兵位的头结点
// 1、拿到pos位置的前后节点
Span* prev = pos->_prev;
Span* next = pos->_next;
// 2、连接前后节点,pos不用delete这里只负责把它移出链表,外部会还对pos做处理
prev->_next = next;
next->_prev = prev;
}
// 获取桶锁
std::mutex& GetSpanListMutex()
{
return _mtx;
}
private:
Span* _head; // 哨兵位的头结点
std::mutex _mtx; // 桶锁
};
3. CentralList类基本框架
CentralCache的核心成员是一个元素类型为SpanList的哈希桶_spanLists[NFREELIST],哈希桶的映射规则和ThreadCache中的自由链表桶映射规则一样,都是通过传入要申请对象空间的大小来映射对齐后得到的小块定长内存大小的桶的位置。
因为所有的Span大块跨度空间只需一个SpanList桶就能组织好,所以在整个进程中CentralCache的实例对象只需要一个就够了,我们考虑把它设计成单例模式,所有想访问CentralCache单例对象的线程只需通过类名调用GetInstance(...)静态成员函数接口即可:
#pragma once
#include "Common.h"
// 饿汉的单例模式
class CentralCache
{
public:
// 返回CentralCache的单例对象
static CentralCache* GetInstance()
{
return &_sInst;
}
// 从中心缓存获取一定数量的小块定长内存给ThreadCache
size_t FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t alignBytes);
private:
// 从特定的SpanList中获取一个非空的span
Span* GetOneSpan(SpanList& list, size_t alignBytes);
SpanList _spanLists[NFREELIST];// 哈希桶
private:
CentralCache()
{}
CentralCache(const CentralCache&) = delete;
static CentralCache _sInst;
// _sInst的定义和成员函数的实现一起放到对应的.cpp文件中
//CentralCache CentralCache::_sInst;
};
三. 其它接口和数据的补充
为了实现CentralCache中成员函数的功能,还需在其它部分补充一些接口和数据。
1. FreeList类中的补充
在Common.h文件下的自由链表类class FreeList中需要补充:
- 成员函数
PushRangeFront(...),该接口用于把ThreadCache从中心缓存中申请到的批量小块定长内存头插到ThreadCache的对应的自由链表桶中。 - 此外还增加了一个成员变量
adjustSize,该变量的值与ThreadCache从中心缓存中申请到的批量小块定长内存的具体数量有关,我们一开始让等于1。
// 管理切分好的小块定长内存的自由链表
class FreeList
{
public:
// 头插批量小块定长内存
void PushRangeFront(void* start, void* end, size_t n)
{
assert(start);
assert(end);
assert(n > 0);
NextObj(end) = _freeList;
_freeList = start;
_size += n;
}
// 获取该链表像中心缓存申请内存时的慢启动调节值的引用
size_t& GetAdjustSize()
{
return adjustSize;
}
private:
size_t _size = 0; // 小块定长内存的数数量
size_t adjustSize = 1; // 向中心缓存申请内存的慢启动调节值
void* _freeList = nullptr; // 存储小块定长内存的自由链表
};
2. 在SizeClass类中的补充
在Common.h文件下的SizeCalss类,我们在里面增加了一个计算ThreadCache一次从中心缓存批量获取小块定长内存的数量的上、下限的函数SizeCalss::LimitSize(...)。这个函数只需传入需要批量申请的每一个小块定长内存的大小alignBytes,用它去除ThreadCache中允许申请的最大字节数MAX_BYTES,即256KB。这样确保申请小内存时多给点,申请大内存时就少给点,但最终给多给少是有上下限的:
class SizeClass
{
// ThreadCache一次从中心缓存批量获取小块定长内存数量的上、下限
static size_t LimitSize(size_t alignBytes)
{
assert(alignBytes != 0);
// [2, 512],一次批量移动多少个对象的(慢启动)上限值
// 大对象(最大256KB)一次批量下限为2个
// 小对象(最小8字节)一次批量上限为512个
size_t num = MAX_BYTES / alignBytes;
if (num < 2)
num = 2;
if (num > 512)
num = 512;
return num;
}
};
四. CentralList成员函数的实现
现阶段CentralList中只包含两个成员函数:

CentralList::GetOneSpan(...)这个函数用于从指定的SpanList链表中获取一个非空的span大块跨度内存,里面还会涉及到从PageCache,所以该函数的实现先空着,后面设计PageCache的时候在完善它:
// 从特定的SpanList中获取一个非空的span
Span* CentralCache::GetOneSpan(SpanList& list, size_t alignBytes)
{
// 涉及到PageCache,先空着
return nullptr;
}
我们主要实现的是CentralList::FetchRangeObj(...),该函数的作用是从中心缓存获取一定数量的小块定长内存给ThreadCache。其中前两个参数是由ThreadCache负责传入作为输出型参数,用来记录申请到的单链表连接的批量小块内存起始节点和最后一个节点;第三个参数是想要申请的小块内存的数量;最后一个参数是小块定长内存的大小。
该函数的实现逻辑如下:
- 先通过小块定长内存的大小映射得到_spanList哈希桶中对应的Span双链表桶下标index,然后拿到存储span大块跨度内存的_spanList[index]双向链表。
- 调用
CentralCache::GetOneSpan(...)从_spanList[index]双向链表中拿出一块span大块跨度内存出来。 - 从span大块内存中获取batchNum个小块定长内存,如果不够batchNum个,有多少拿多少。
- 最后return返回拿到的小块定长内存的数量。
PS:线程访问_spanList[index]桶时需要加桶锁,注意这个桶锁是每一个SpanList类型的双向链表结构独有的,它是声明在SpanList这个类中的,而不是在CentralCache这个类中,CentralCache中只有SpanList _spanLists[NFREELIST]这个哈希桶。
// 从中心缓存获取一定数量的小块定长内存给ThreadCache
size_t CentralCache::FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t alignBytes)
{
assert(batchNum > 0);
assert(alignBytes >= 8);
size_t index = SizeClass::Index(alignBytes);
_spanLists[index].GetSpanListMutex().lock();
// 从span中获取batchNum个小块定长内存
// 如果不够batchNum个,有多少拿多少
// 拿完后end存储的下一个节点要为置为空,span的自由链表也要对应更新
Span* span = GetOneSpan(_spanLists[index], alignBytes);
assert(span);
assert(span->_freeList);
start = span->_freeList;
end = span->_freeList;
size_t actualNum = 1;
while (actualNum < batchNum && NextObj(end))
{
++actualNum;
end = NextObj(end);
}
span->_freeList = NextObj(end);
NextObj(end) = nullptr;
span->_useCount += actualNum;
_spanLists[index].GetSpanListMutex().unlock();
return actualNum;
}
五. ThreadCache对接CentralList申请内存
接下来我们可以完善第二篇讲ThreadCache类时是遗留下来的一个接口ThreadCache::FetchFromCentralCache(...)没有实现,这个函数是线程的ThreadCache中自由链表没有小块内存了,通过调用该函数的从中心缓存中申请批量小块定长内存过来。
一次从中心缓存拿多少个小块定长内存合适呢?每次拿一个的话会效率太低,一次批量太多的话太多了可能又用不完。在这里我们先通过前面在SizeCalss类中补充的函数SizeClass::LimitSize(...)来限定每一种大小的小块定长内存一次批量的上、下限。然后再使用慢启动反馈调节法从批量一个开始,逐渐增加之后批量的小块定长内存的数量,每一次批发数量在之前的基础下加一,最后直到它的上限为止。
// 从中心缓存获取“一批”小块定长内存,并返回给外部“一块”小块定长内存
void* ThreadCache::FetchFromCentralCache(size_t index, size_t alignBytes)
{
// 慢启动反馈调节算法
// 1、最开始不会一次向CentralCache批量太多,因为要太多了可能用不完
// 2、每次批发的数量逐渐增多,直到上限
// 3、alignBytes越小,一次向CentralCache要的batchNum就越大
// 4、alignBytes越大,一次向CentralCache要的batchNum就越小
assert(index >= 0);
assert(alignBytes >= 8);
// 1、计算需要向CentralCache申请的小块定长内存的数量
size_t batchNum = min(_freeLists[index].GetAdjustSize(), SizeClass::LimitSize(alignBytes));
if (_freeLists[index].GetAdjustSize() == batchNum)
{
_freeLists[index].GetAdjustSize() += 1;
}
// 2、传入输出型参数向CentralCache申请批量小块定长内存
void* begin = nullptr;
void* end = nullptr;
size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(begin, end, batchNum, alignBytes);
// 3、返回给外部第一个小块定长内存,其它的挂到自由链表桶中
assert(actualNum > 0);
if (actualNum == 1)
{
assert(begin == end);
return begin;
}
else
{
_freeLists[index].PushRangeFront(NextObj(begin), end, actualNum-1);
return begin;
}
}















 1395
1395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









